Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
В этой статье представлена архитектура «озера медальона» и описывается, как вы можете реализовать шаблон проектирования в Microsoft Fabric. Он предназначен для нескольких аудиторий:
- Специалисты по обработке и анализу данных: технические специалисты, которые разрабатывают, создают и поддерживают инфраструктуру и системы, которые позволяют организации собирать, хранить, обрабатывать и анализировать большие объемы данных.
- Центр знаний, ИТ-специалистов и команд бизнес-аналитики: Команды, ответственные за надзор за аналитикой по всей организации.
- Администраторы Структуры: администраторы, ответственные за надзор за Структурой в организации.
Архитектура medallion lakehouse, известная как архитектура медальона, является шаблоном проектирования, который используется организациями для логического упорядочения данных в лейкхаусе. Это рекомендуемый подход к проектированию для Fabric. Поскольку OneLake является озером данных для Fabric, архитектура медальона реализуется путем создания озер-хранилищ данных в OneLake.
Архитектура медальона состоит из трех различных слоев, также называемых зонами. Три уровня медальона: бронза (необработанные данные), серебро (проверенные данные) и золото (обогащенные данные). Каждый слой указывает качество данных, хранящихся в озере, с более высоким уровнем, представляющим более высокое качество. Этот многоуровневый подход помогает создать единый источник истины для корпоративных продуктов данных.
Важно, что медальонная архитектура гарантирует атомарность, согласованность, изоляцию и долговечность (ACID), по мере того как данные проходят через слои. Данные начинаются в необработанной форме, а затем ряд проверок и преобразований подготавливает данные для оптимизации данных для эффективной аналитики, а также поддержания исходных копий в качестве источника истины.
Дополнительные сведения см. в разделе "Что такое архитектура medallion lakehouse?".
Архитектура Medallion в Fabric
Цель архитектуры медальона заключается в постепенном и постепенном улучшении структуры и качества данных по мере прогресса на каждом этапе.
Архитектура медальона состоит из трех отдельных слоев (или зон).
- Бронза: Также называется необработанной зоной, этот первый слой сохраняет исходные данные в исходном формате, включая неструктурированные, полуструктурированные или структурированные типы данных. Данные в этом слое обычно доступны только для добавления и неизменяемы. Сохраняя необработанные данные в бронзовом слое, вы сохраняете источник истины и включаете повторную обработку и аудит в будущем.
- Серебро: Также называется обогащенной зоной, этот слой сохраняет данные, полученные из бронзового слоя. Данные очищаются и стандартизированы, а теперь структурированы как таблицы (строки и столбцы). Она также может быть интегрирована с другими данными для предоставления корпоративного представления всех бизнес-сущностей, таких как клиенты, продукты и многое другое.
- Золото: Также называется курированной зоной, этот окончательный слой сохраняет данные, полученные из серебряного слоя. Данные уточнены для удовлетворения конкретных требований к бизнесу и аналитике. Таблицы обычно соответствуют схеме звезд, которая поддерживает разработку моделей данных, оптимизированных для повышения производительности и удобства использования.
Каждая зона должна быть разделена на собственное озеро данных или хранилище данных в OneLake, при этом данные перемещаются между зонами по мере их преобразования и уточнения.
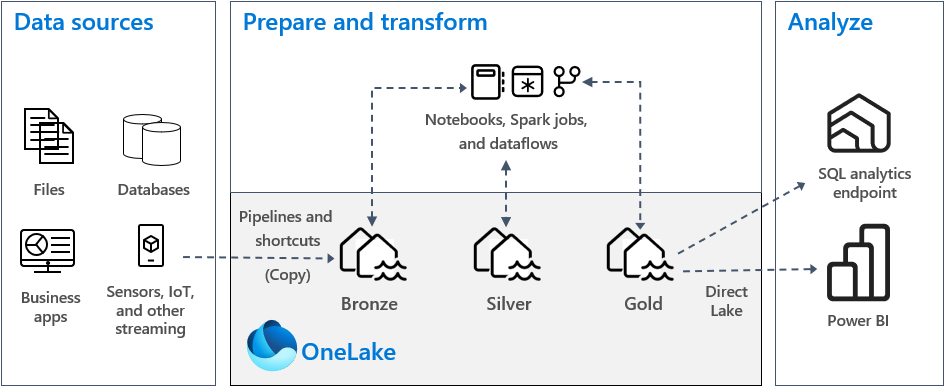
В типичной реализации архитектуры медальона в Fabric бронзовая зона сохраняет данные в том же формате, что и источник данных. Если источник данных является реляционной базой данных, разностные таблицы являются хорошим выбором. Серебряные и золотые зоны должны содержать таблицы Delta.
Совет
Чтобы узнать, как создать lakehouse, ознакомьтесь с руководством по комплексному сценарию Lakehouse.
OneLake и lakehouse в Fabric
Основой современного хранилища данных является озеро данных. Microsoft OneLake — это единое, единое, логическое озеро данных для всей организации. Он предоставляется автоматически для каждого клиента Fabric и является единственным местом для всех данных аналитики.
Вы можете использовать OneLake для:
- Удалите силосы и уменьшите усилия по управлению. Все данные организации хранятся, управляются и защищены в одном ресурсе озера данных.
- Уменьшение перемещения и дублирования данных. Цель OneLake — хранить только одну копию данных. Меньше копий данных приводит к уменьшению числа процессов перемещения данных, что приводит к повышению эффективности и снижению сложности. Используйте сочетания клавиш для ссылки на данные, хранящиеся в других местах, а не для копирования в OneLake.
- Используется с несколькими аналитическими подсистемами. Данные в OneLake хранятся в открытом формате. Таким образом, данные можно запрашивать различными аналитическими подсистемами, включая службы Analysis Services (используемые Power BI), T-SQL и Apache Spark. Другие приложения, отличные от Fabric, также могут использовать API и пакеты SDK для доступа к OneLake .
Чтобы хранить данные в OneLake, создайте lakehouse в Fabric. Lakehouse — это платформа архитектуры данных для хранения, управления и анализа структурированных и неструктурированных данных в одном расположении. Он может масштабироваться до больших объемов данных всех типов файлов и размеров, и так как данные хранятся в одном расположении, их можно совместно использовать и повторно использовать в организации.
Каждый lakehouse имеет встроенную конечную точку аналитики SQL, которая разблокирует возможности хранилища данных без необходимости перемещать данные. Это означает, что вы можете запрашивать данные в lakehouse с помощью запросов SQL и без каких-либо специальных настроек.
Дополнительные сведения см. в статье "Что такое lakehouse в Microsoft Fabric?".
Таблицы и файлы
При создании озерного дома в OneLake автоматически предоставляются два физических места хранения.
- Таблицы — это управляемая область для хранения таблиц всех форматов в Apache Spark (CSV, Parquet или Delta). Все таблицы, созданные автоматически или явным образом, распознаются как таблицы в lakehouse. Все таблицы Delta, которые являются файлами данных Parquet с журналом транзакций на основе файлов, также распознаются как таблицы.
- Файлы — это неуправляемая область для хранения данных в любом формате файла. Все разностные файлы, хранящиеся в этой области, не распознают как таблицы автоматически. Если вы хотите создать таблицу по папке Delta Lake в неуправляемой области, создайте ярлык или внешнюю таблицу с расположением, которое указывает на неуправляемую папку, содержащую файлы Delta Lake в Apache Spark.
Основное различие между управляемой областью (таблицами) и неуправляемой областью (файлами) является автоматическим процессом обнаружения и регистрации таблиц. Этот процесс выполняется по любой папке, созданной только в управляемой области, но не в неуправляемой области.
В бронзовой зоне данные хранятся в исходном формате, которые могут быть таблицами или файлами. Если исходные данные из OneLake, Azure Data Lake Store 2-го поколения (ADLS Gen2), Amazon S3 или Google Cloud Storage, создайте ярлык в бронзовой зоне вместо копирования данных.
В серебряных и золотых зонах обычно хранятся данные в таблицах Delta. Однако вы также можете хранить данные в файлах Parquet или CSV. При этом необходимо явно создать ярлык или внешнюю таблицу с расположением, которое указывает на неуправляемую папку, содержащую файлы Delta Lake в Apache Spark.
В Microsoft Fabric обозреватель Lakehouse предоставляет единое графическое представление всего Lakehouse для пользователей для навигации, доступа и обновления своих данных.
Дополнительные сведения об автоматическом обнаружении таблиц см. в разделе "Автоматическое обнаружение и регистрация таблиц".
Хранилище Delta Lake
Delta Lake — это оптимизированный уровень хранения, который предоставляет основу для хранения данных и таблиц. Он поддерживает транзакции ACID для рабочих нагрузок больших данных, и по этой причине это формат хранения по умолчанию в Lakehouse Fabric.
Delta Lake обеспечивает надежность, безопасность и производительность в озерном хранилище как при потоковой обработке данных, так и при пакетных операциях. Внутри него хранятся данные в формате файла Parquet, однако она также поддерживает журналы транзакций и статистику, которые обеспечивают функции и повышение производительности по сравнению со стандартным форматом Parquet.
Формат Delta Lake обеспечивает следующие преимущества по сравнению с универсальными форматами файлов:
- Поддержка свойств ACID, особенно устойчивость для предотвращения повреждения данных.
- Быстрее считывать запросы.
- Повышенная свежесть данных.
- Поддержка рабочих нагрузок пакетной и потоковой передачи.
- Поддержка отката данных с помощью перемещения по времени Delta Lake.
- Повышено соответствие нормативным требованиям и улучшен аудит с помощью истории таблиц Delta Lake.
Фреймворк стандартизирует формат файлов хранения данных с использованием технологии Delta Lake. По умолчанию каждый механизм рабочей нагрузки в Fabric создает таблицы Delta при записи данных в новую таблицу. Дополнительные сведения см. в таблицах Lakehouse и Delta Lake.
Модель развертывания
Для реализации архитектуры медальона в Fabric можно использовать lakehouses (по одному для каждой зоны), хранилище данных или сочетание обоих. Ваше решение должно быть основано на ваших предпочтениях и опыте вашей команды. С помощью Fabric можно использовать различные аналитические механизмы, работающие на одной копии данных в OneLake.
Ниже приведены два шаблона, которые следует учитывать:
- Шаблон 1. Создание каждой зоны в виде озера. В этом случае бизнес-пользователи получают доступ к данным с помощью конечной точки аналитики SQL.
- Шаблон 2. Создайте бронзовые и серебряные зоны в виде озерных домов и золотой зоны в качестве хранилища данных. В этом случае бизнес-пользователи получают доступ к данным с помощью конечной точки хранилища данных.
Хотя вы можете создать все дата-озера в одной рабочей области Fabric, рекомендуется создать каждое дата-озеро в отдельной рабочей области. Этот подход обеспечивает больший контроль и улучшение управления на уровне зоны.
Для бронзовой зоны рекомендуется хранить данные в исходном формате или использовать Parquet или Delta Lake. По возможности сохраните данные в исходном формате. Если исходные данные созданы из OneLake, Azure Data Lake Store 2-го поколения (ADLS 2-го поколения), Amazon S3 или Google, создайте ярлык в бронзовой зоне вместо копирования данных по всему.
Для зон серебра и золота рекомендуется использовать таблицы Delta из-за дополнительных возможностей и улучшений производительности, которые они предоставляют. Структура стандартизирует формат Delta Lake и по умолчанию каждый механизм в Fabric записывает данные в этом формате. Кроме того, эти подсистемы используют оптимизацию времени записи V-Order в формате файла Parquet. Эта оптимизация позволяет вычислительным подсистемам Fabric, таким как Power BI, SQL, Apache Spark и другие, быстро считывать данные. Дополнительные сведения см. в разделе "Оптимизация таблицы Delta Lake" и "V-Order".
Наконец, сегодня многие организации сталкиваются с массовым ростом объемов данных, а также с увеличением необходимости упорядочивать и управлять данными логическим способом, обеспечивая более целевое и эффективное использование и управление ими. Это может привести к созданию и управлению децентрализованной или федеративной организацией данных с помощью управления. Для удовлетворения этой цели рекомендуется реализовать архитектуру сетки данных. Сетка данных — это архитектурный шаблон, ориентированный на создание доменов данных, которые предлагают данные в качестве продукта.
Вы можете создать архитектуру сетки данных для своего пространства данных в Fabric, создав домены данных. Вы можете создавать домены, которые сопоставляют ваши бизнес-домены, например маркетинг, продажи, инвентаризацию, персонал и другие. Затем можно реализовать архитектуру медальона, настроив зоны данных в каждом из доменов. Дополнительные сведения о доменах см. в разделе "Домены".
Общие сведения о хранилище данных таблицы Delta
В этом разделе описаны другие рекомендации, связанные с реализацией архитектуры medallion lakehouse в Fabric.
Размер файла
Как правило, платформа больших данных лучше работает, если она содержит несколько больших файлов, а не многие небольшие файлы. Снижение производительности происходит, когда подсистема вычислений имеет множество метаданных и операций с файлами для управления. Для повышения производительности запросов рекомендуется стремиться к файлам данных, размер которых составляет около 1 ГБ.
Delta Lake имеет функцию, называемую прогнозной оптимизацией. Прогнозная оптимизация автоматизирует операции обслуживания для таблиц Delta. Если эта функция включена, Delta Lake определяет таблицы, которые могут извлечь выгоду из операций обслуживания, а затем оптимизирует их хранение. Хотя эта функция должна быть частью операционной эффективности и работы по подготовке данных, Структура также может оптимизировать файлы данных при записи данных. Дополнительные сведения см. в разделе "Прогнозная оптимизация" для Delta Lake.
Историческое хранение
По умолчанию Delta Lake сохраняет журнал всех внесенных изменений, поэтому размер исторических метаданных растет со временем. На основе бизнес-требований сохраняйте исторические данные только в течение определенного периода времени, чтобы сократить затраты на хранение. Попробуйте сохранить исторические данные только за последний месяц или другой подходящий период времени.
Вы можете удалить старые исторические данные из таблицы Delta с помощью команды VACUUM. Однако по умолчанию вы не можете удалить исторические данные за последние семь дней. Это ограничение поддерживает согласованность данных. Настройте число дней по умолчанию, используя свойство delta.deletedFileRetentionDuration = "interval <interval>" таблицы. Это свойство определяет период времени удаления файла, прежде чем его можно считать кандидатом для операции вакуума.
Разделы таблиц
При хранении данных в каждой зоне рекомендуется использовать секционированную структуру папок везде, где это применимо. Этот метод повышает удобство управления данными и производительность запросов. Как правило, секционированные данные в структуре папок приводят к более быстрому поиску определенных записей данных из-за очистки и ликвидации секций.
Как правило, данные добавляются в целевую таблицу по мере поступления новых данных. Однако в некоторых случаях данные могут объединяться, так как необходимо одновременно обновлять существующие данные. В этом случае можно выполнить операцию upsert с помощью команды MERGE. Если целевая таблица секционирована, обязательно используйте фильтр секционирования для ускорения операции. Таким образом, модуль может исключить секции, которые не требуют обновления.
Доступ к данным
Вы должны планировать и контролировать, кто нуждается в доступе к определенным данным в хранилище данных (lakehouse). Вы также должны понимать различные шаблоны транзакций, которые они будут использовать при доступе к этим данным. Затем можно определить правильную схему секционирования таблиц и совместное размещение данных с помощью индексов порядка Delta Lake Z.
Связанный контент
Дополнительные сведения о реализации Lakehouse Fabric см. в следующих ресурсах.
- Руководство по комплексному сценарию Lakehouse
- Таблицы Lakehouse и Delta Lake
- Руководство по принятию решений Microsoft Fabric: выбор хранилища данных
- Потребность в оптимизации записи в Apache Spark
- Вопросы? Попробуйте попросить сообщество Fabric.
- Есть предложения? Участие в разработке идей по улучшению Структуры.