Обучение структурированной или свободной модели обработки документов в Microsoft Syntex
Следуйте инструкциям в разделе Создание модели в Syntex , чтобы создать структурированную или свободную модель обработки документов в центре содержимого. Или следуйте инструкциям в разделе Создание модели на локальном сайте SharePoint , чтобы создать модель на локальном сайте. Затем используйте эту статью для обучения модели.

Чтобы обучить структурированную или свободную модель обработки документов, выполните следующие действия.
- Шаг 1. Добавление и анализ документов
- Шаг 2. Добавление тегов к полям и таблицам
- Шаг 3. Обучение и публикация модели
- Шаг 4. Использование модели
Шаг 1. Добавление и анализ документов
После создания структурированной или свободной модели обработки документов откроется страница Выбор сведений для извлечения . Здесь перечислены все сведения, которые модель ИИ будет извлекать из документов, например Имя, Адрес или Сумма.
Примечание.
При поиске примеров файлов для использования ознакомьтесь с требованиями к входным документам модели обработки документов и советами по оптимизации.
Сначала определите поля и таблицы, которые вы хотите научить модели извлекать на странице Выберите сведения для извлечения. Подробные инструкции см. в разделе Определение полей и таблиц для извлечения.
Вы можете создать столько коллекций макетов документов, сколько хотите, которые нужно обработать модели. Подробные инструкции см. в разделе Группировка документов по коллекциям.
После создания коллекций и добавления по крайней мере пяти примеров файлов для каждого из них AI Builder в Syntex проверит отправленные документы, чтобы обнаружить поля и таблицы. Этот процесс обычно занимает несколько секунд. После завершения анализа можно продолжить добавление тегов к документам.
Шаг 2. Добавление тегов к полям и таблицам
Необходимо пометить документы, чтобы обучить модель понимать поля и данные таблицы, которые требуется извлечь. Подробные инструкции см. в разделе Добавить теги к документам.
Шаг 3. Обучение и публикация модели
После создания и обучения модели ее можно опубликовать и использовать в SharePoint. Чтобы опубликовать модель, выберите Опубликовать. Подробные инструкции см. в разделе Обучение и публикация модели обработки документов.
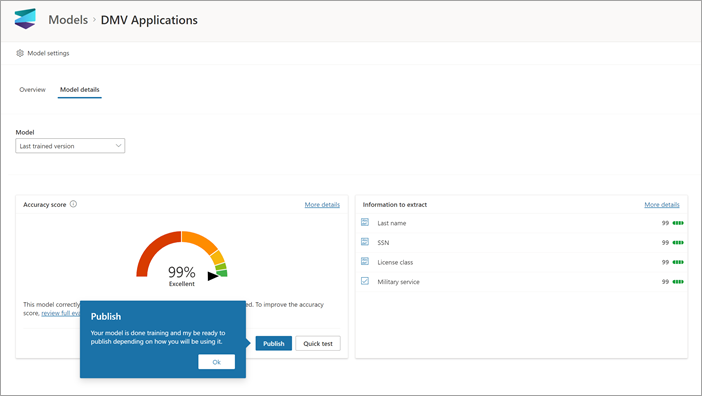
После публикации модели вы перейдете на домашнюю страницу модели. После этого вы сможете применить модель к библиотеке документов.
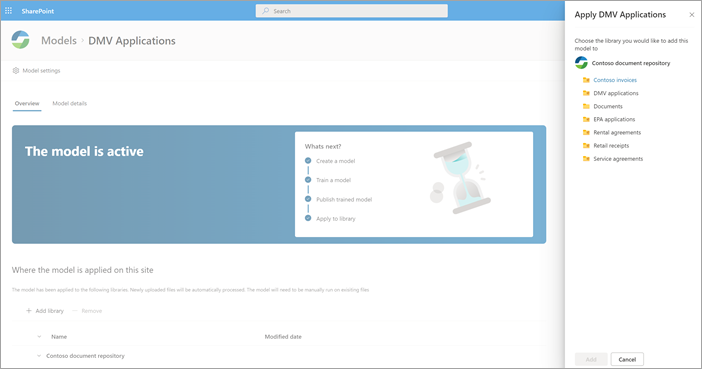
Шаг 4. Использование модели
В представлении модели библиотеки документов обратите внимание, что выбранные вами поля теперь отображаются в виде столбцов.
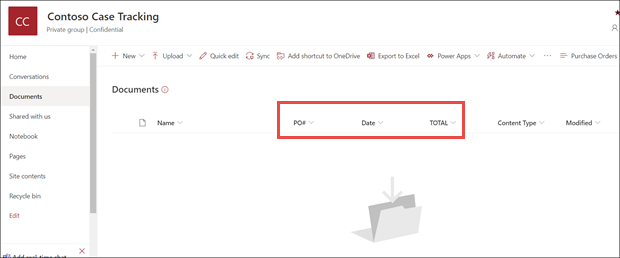
Обратите внимание, что информационная ссылка рядом с документами указывает на то, что к этой библиотеке документов применяется модель обработки форм.
Отправка файлов в вашу библиотеку документов. Все файлы, которые модель определяет как тип контента, перечисляют файлы в представлении и отображают извлеченные данные в столбцах.
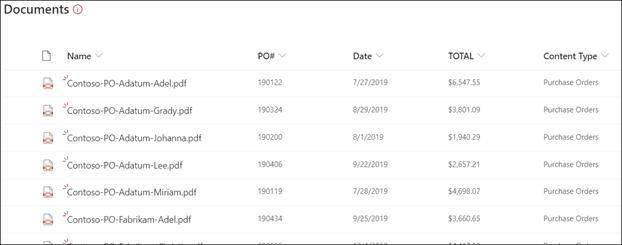
Примечание.
Если структурированная или свободная модель обработки документов и неструктурированная модель обработки документов применяются к одной библиотеке, файл классифицируется с помощью неструктурированной модели обработки документов и любых обученных средств извлечения для этой модели. Если есть пустые столбцы, которые соответствуют модели обработки документов, столбцы будут заполнены с помощью извлеченных значений.
Поле "Дата классификации"
При применении любой пользовательской модели к библиотеке документов в схему библиотеки включается поле Дата классификации . По умолчанию это поле пусто. Однако при обработке и классификации документов по модели это поле обновляется меткой даты и времени завершения.
Если модель помечена датой классификации, можно использовать функцию Отправить сообщение электронной почты после обработки syntex потока файлов , чтобы уведомить пользователей о том, что новый файл был обработан и классифицирован моделью в библиотеке документов SharePoint.
Чтобы запустить поток, выполните следующие действия:
Выберите файл, а затем выберите Интегрировать>Power Automate>Создать поток.
На панели Создание потока выберите Отправить сообщение электронной почты после обработки файла Syntex.
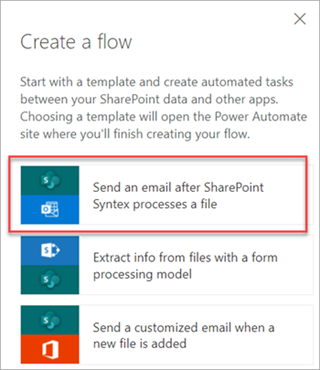
Использование потоков для извлечения сведений
Важно!
Сведения, приведенные в этом разделе, не относятся к последнему выпуску Syntex. Он остается в качестве ссылки только для моделей обработки форм, созданных в предыдущих выпусках. В последнем выпуске больше не нужно настраивать потоки для обработки существующих файлов.
Для обработки выбранного файла или пакета файлов в библиотеке, где применяется структурированная или свободная модель обработки документов, доступны два потока.
Извлечение сведений из изображения или PDF-файла с помощью модели обработки документов . Используйте для извлечения текста из выбранного изображения или PDF-файла путем запуска модели обработки документов. Поддерживает один выбранный файл одновременно и поддерживает только PDF-файлы и файлы изображений (.png, .jpg и JPEG-файлы). Чтобы запустить поток, выберите файл, а затем выберите Автоматизировать>извлечение сведений.
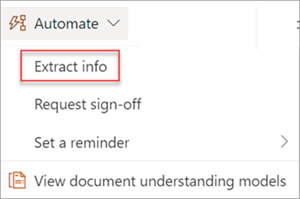
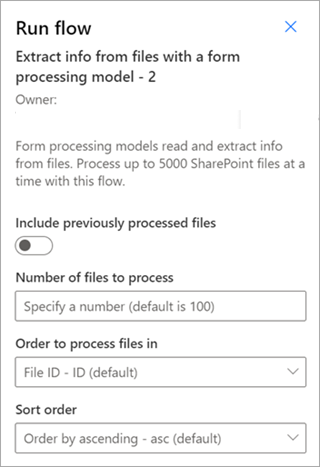
Извлечение сведений из файлов с помощью модели обработки документов . Используйте модели обработки документов для чтения и извлечения информации из пакета файлов. Одновременно обрабатывает до 5000 файлов SharePoint. При выполнении этого потока можно задать определенные параметры. Варианты действий:
- Выберите, следует ли включать ранее обработанные файлы (по умолчанию не следует включать ранее обработанные файлы).
- Выберите количество файлов для обработки (по умолчанию — 100 файлов).
- Укажите порядок обработки файлов (можно выбрать идентификатор файла, имя файла, время создания файла или время последнего изменения).
- Укажите порядок сортировки (по возрастанию или убыванию).
Примечание.
Поток Извлечения сведений из изображения или PDF-файла с помощью модели обработки документов автоматически доступен для библиотеки с связанной моделью обработки документов. Поток извлечения сведений из файлов с моделью обработки документов — это шаблон, который при необходимости необходимо добавить в библиотеку.