Прием экспортированных данных Dataverse с помощью фабрики данных Azure
После экспорта данных из Microsoft Dataverse в Azure Data Lake Storage Gen2 с Azure Synapse Link for Dataverse вы можете использовать фабрику данных Azure для создания потоков данных, преобразования данных и выполнения анализа.
Примечание
Azure Synapse Link for Dataverse ранее называлось "Экспорт в озеро данных". Служба была переименована в мае 2021 года и будет продолжать экспортировать данные в Azure Data Lake, а также в Azure Synapse Analytics.
В этой статье показано, как выполнить следующие задачи:
Установите учетную запись хранения Data Lake Storage Gen2 с данными Dataverse как источник в потоке данных фабрики данных.
Преобразуйте данные Dataverse в фабрике данных с потоком данных.
Установите учетную запись хранения Data Lake Storage Gen2 с данными Dataverse как приемник в потоке данных фабрики данных.
Запустите свой поток данных, создав конвейер.
Предварительные условия
В этом разделе описаны предварительные условия, необходимые для приема экспортированных данных Dataverse с помощью фабрики данных.
Роли Azure. Учетная запись пользователя, используемая для входа в Azure, должна быть участником роли участник или владелец или администратором подписки Azure. Чтобы просмотреть разрешения, которые у вас есть в подписке, перейдите в портал Azure, выберите свое имя пользователя в правом верхнем углу, выберите ..., затем выберите Мои разрешения. Если у вас есть доступ к нескольким подпискам, выберите подходящую. Чтобы создать дочерние ресурсы и управлять ими для фабрики данных на портале Azure — включая наборы данных, связанные сервисы, конвейеры, триггеры и среды выполнения интеграции — необходимо принадлежать к роли Участник фабрики данных на уровне группы ресурсов или выше.
Azure Synapse Link for Dataverse. В этом руководстве предполагается, что вы уже экспортировали данные Dataverse с помощью Azure Synapse Link for Dataverse. В этом примере данные таблицы учетной записи экспортируются в озеро данных.
Фабрика данных Azure. В этом руководстве предполагается, что вы уже создали фабрику данных в той же подписке и группе ресурсов, что и учетная запись хранения, содержащая экспортированные данные Dataverse.
Задание учетной записи хранения Data Lake Storage Gen2 в качестве источника
Откройте Фабрика данных Azure и выберите фабрику данных, которая находится в той же подписке и группе ресурсов, что и учетная запись хранения, содержащая экспортированные данные Dataverse. Затем выберите Создать поток данных на домашней странице.
Включите режим Отладка потока данных и выберите желаемый период существования. Это может занять до 10 минут, но вы можете выполнять следующие шаги.

Выберите Добавить источник.

В разделе Параметры источника выполните следующие действия:
- Имя выходного потока: введите желаемое имя.
- Тип источника: Выберите Встроенный.
- Встроенный тип набора данных: выберите Common Data Model.
- Связанная служба: выберите учетную запись хранения из раскрывающегося меню, затем свяжите новую службу, указав сведения о подписке и оставив все конфигурации по умолчанию.
- Выборка: если вы хотите использовать все свои данные, выберите Отключить.
В разделе Параметры источника выполните следующие действия:
Формат метаданных: выберите Model.json.
Корневое расположение: введите имя контейнера в первое поле (Контейнер) или Обзор в качестве имени контейнера и выберите ОК.
Сущность: введите имя таблицы или Обзор для таблицы.

Проверьте вкладку Проекция, чтобы убедиться, что ваша схема была успешно импортирована. Если вы не видите столбцов, выберите Параметры схемы и проверьте параметр Вывести типы смещенных столбцов. Настройте параметры форматирования в соответствии с вашим набором данных, затем выберите Применить.
Вы можете просмотреть свои данные на вкладке Предварительный просмотр данных, чтобы убедиться, что создание источника было полным и точным.
Преобразование своих данных Dataverse
После настройки экспортированных данных Dataverse в учетной записи Azure Data Lake Storage Gen2 в качестве источника в потоке данных фабрики данных, существует множество возможностей для преобразования ваших данных. Больше информации: Фабрика данных Azure
Следуйте этим инструкциям, чтобы создать ранг для каждой строки по полю доход таблицы учетной записи.
Выберите + в правом нижнем углу предыдущего преобразования, а затем найдите и выберите Ранг.
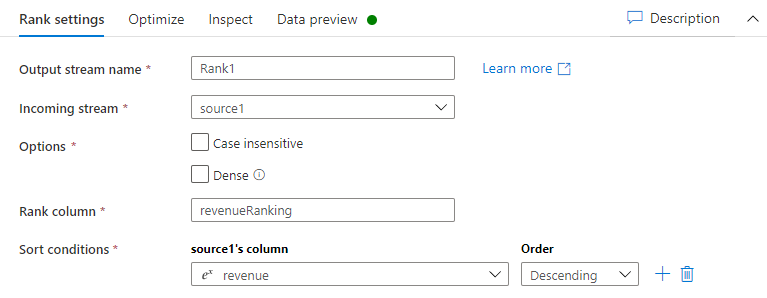
На вкладке Параметры ранга выполните следующее:
Имя выходного потока: введите желаемое имя, например Ранг1.
Входящий поток: выберите желаемое имя источника. В этом случае имя источника из предыдущего шага.
Параметры: не устанавливайте флажки для параметров.
Столбец ранга: введите имя сгенерированного столбца ранга.
Условия сортировки: выберите столбец доход и сортировку По убыванию.
Вы можете просмотреть свои данные на вкладке предварительный просмотр данных, где вы найдете новый столбец revenueRank в крайнем правом положении.
Установите учетную запись хранения Data Lake Storage Gen2 в качестве приемника
В конечном итоге вы должны установить приемник для своего потока данных. Следуйте этим инструкциям, чтобы поместить преобразованные данные в виде текстового файла с разделителями в озере данных.
Выберите + в правом нижнем углу предыдущего преобразования, а затем найдите и выберите Приемник.
На вкладке Приемник выполните одно из следующих действий.
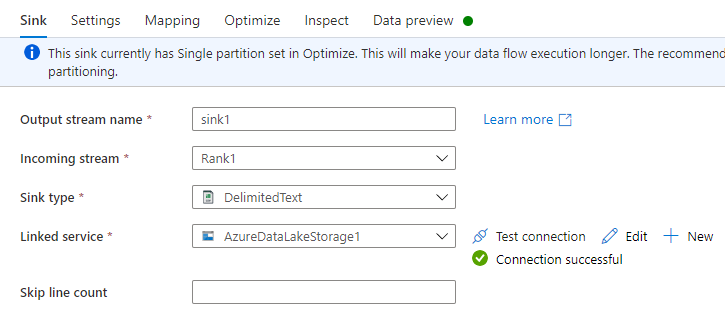
Имя выходного потока: введите желаемое имя, например, Sink1.
Входящий поток: выберите желаемое имя источника. В этом случае имя источника из предыдущего шага.
Тип приемника: выберите DelimitedText.
Связанная служба: выберите контейнер хранения Data Lake Storage 2-го поколения, в котором хранятся данные, экспортированные с помощью службы Azure Synapse Link for Dataverse.
На вкладке Параметры можно выполнить следующие действия:
Путь к папке: введите имя контейнера в первое поле (Файловая система) или Обзор в качестве имени контейнера и выберите ОК.
Параметр имени файла: выберите вывод в один файл.
Вывод в один файл: введите имя файла, например ADFOutput
Оставьте все остальные параметры по умолчанию.
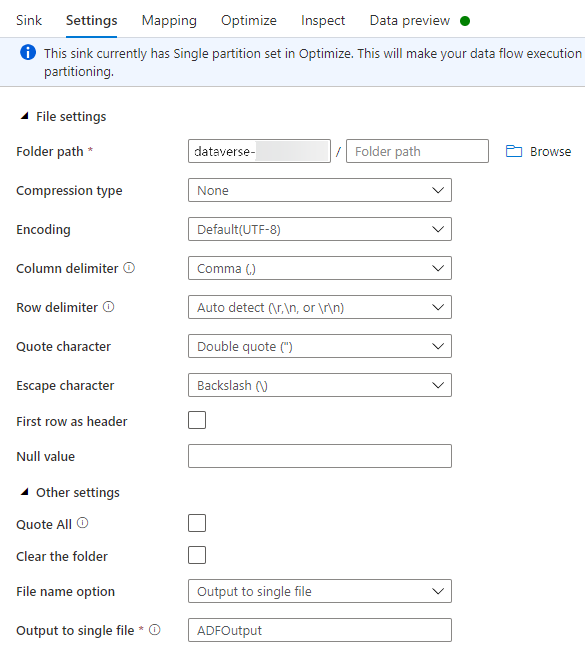
На вкладке Оптимизировать установите Параметр раздела как Один раздел.
Вы можете просмотреть свои данные на вкладке Предварительный просмотр данных.
Запуск своего потока данных
На левой панели в разделе Ресурсы фабрики выберите +, затем выберите Конвейер.

В разделе Действия выберите Переместить и преобразовать, затем перетащите Поток данных в рабочую область.
Выберите Использовать существующий поток данных, затем выберите поток данных, созданный на предыдущих шагах.
Выберите Отладка на панели команд.
Позвольте потоку данных работать, пока нижнее представление не покажет, что он был завершен. Это может занять несколько минут.
Перейдите в конечный целевой контейнер хранения и найдите преобразованный файл данных таблицы.
См. также
Настройка Azure Synapse Link for Dataverse с Azure Data Lake
Анализ данных Dataverse в Azure Data Lake Storage Gen2 с помощью Power BI
Примечание
Каковы ваши предпочтения в отношении языка документации? Пройдите краткий опрос (обратите внимание, что этот опрос представлен на английском языке).
Опрос займет около семи минут. Личные данные не собираются (заявление о конфиденциальности).