Автоматические агрегаты
Автоматические агрегаты используют состояние машинного обучения (ML) для непрерывной оптимизации семантических моделей DirectQuery для максимальной производительности запросов отчетов. Автоматические агрегаты создаются на основе существующей пользовательской инфраструктуры агрегатов, впервые появившихся с составными моделями для Power BI. В отличие от определяемых пользователем агрегатов автоматические агрегаты не требуют обширных навыков моделирования данных и оптимизации запросов для настройки и обслуживания. Автоматические агрегаты являются самообучением и самооптимизацией. Они позволяют владельцам моделей любого уровня навыков повысить производительность запросов, обеспечивая более быстрые визуализации отчетов для больших моделей.
С автоматическими агрегатами:
- Визуализации отчетов быстрее. Оптимальный процент запросов отчетов возвращается автоматически поддерживаемым кэшем агрегирования в памяти вместо внутренних систем источников данных. Запросы outlier, которые не возвращаются кэшем в памяти, передаются непосредственно источнику данных с помощью DirectQuery.
- Сбалансированная архитектура. По сравнению с чистым режимом DirectQuery большинство результатов запроса возвращаются подсистемой запросов Power BI и кэшом агрегатов в памяти. Нагрузка на обработку запросов на системы источников данных во время пиковых отчетов может значительно сократиться, что означает увеличение масштабируемости в серверной части источника данных.
- Простая настройка. Владельцы моделей могут включить автоматическое обучение агрегатов и запланировать одно или несколько обновлений для модели. При первом обучении и обновлении автоматические агрегаты начинают создавать платформу агрегирования и оптимальные агрегаты. Система автоматически настраивает себя с течением времени.
- Тонкой настройке. С помощью простого и интуитивно понятного пользовательского интерфейса в параметрах модели можно оценить повышение производительности для другого процента запросов, возвращаемых из кэша агрегирования в памяти, и внести корректировки для еще большего повышения. Элемент управления с одной панелью слайдов позволяет легко настроить среду.
Requirements
Поддерживаемые планы
Автоматические агрегаты поддерживаются для Power BI Premium для каждой емкости, Premium на пользователя и моделей Power BI Embedded.
Поддерживаемые источники данных
Для следующих источников данных поддерживаются автоматические агрегаты:
- База данных SQL Azure
- Выделенный пул SQL Azure Synapse
- SQL Server 2019 или более поздней версии
- Google BigQuery
- Снежинка
- Databricks
- Amazon Redshift
Поддерживаемые режимы
Для моделей режима DirectQuery поддерживаются автоматические агрегаты. Поддерживаются составные модели с таблицами импорта и подключениями DirectQuery. Автоматические агрегаты поддерживаются только для подключения DirectQuery.
Разрешения
Чтобы включить и настроить автоматические агрегаты, необходимо быть владельцем модели. Администраторы рабочей области могут взять на себя роль владельца, чтобы настроить параметры автоматической статистической обработки.
Настройка автоматических агрегатов
Автоматические агрегаты настраиваются в Параметры модели. Настройка проста. Включите автоматическое обучение агрегатов и запланируйте одно или несколько обновлений. Прежде чем настраивать автоматические агрегаты для модели, обязательно ознакомьтесь с этой статьей. Он предоставляет хорошее представление о том, как работают автоматические агрегаты и помочь вам решить, подходит ли автоматическая агрегирование для вашей среды. Когда вы будете готовы к пошаговые инструкции по включению автоматического обучения агрегирования, настройке расписания обновления и настройке для вашей среды, см . статью "Настройка автоматических агрегатов".
Льготы
При использовании DirectQuery каждый раз, когда пользователь модели открывает отчет или взаимодействует с визуализацией отчета, запросы анализа данных (DAX) передаются в обработчик запросов, а затем в серверный источник данных в виде запросов SQL. Источник данных должен вычислять и возвращать результаты для каждого запроса. По сравнению с моделями режима импорта, хранящимися в памяти, круговые пути источника данных DirectQuery могут быть как временными, так и процессными, часто вызывая медленное время отклика запросов в визуализациях отчетов.
При включении модели DirectQuery автоматические агрегаты могут повысить производительность запросов отчета, избегая обходных путей запроса источника данных. Предварительно агрегированные результаты запроса автоматически возвращаются кэшом агрегатов в памяти, а не отправляются и возвращаются источником данных. Объем предварительно агрегированных данных в кэше агрегатов в памяти составляет небольшую долю объема данных, хранящихся в фактических и подробных таблицах в источнике данных. Результатом является не только повышение производительности запросов отчетов, но и снижение нагрузки на серверные системы источников данных. С автоматическими агрегатами только небольшая часть отчетов и нерегламентированных запросов, требующих агрегирования, не включенных в кэш в памяти, передаются в внутренний источник данных, как и в чистом режиме DirectQuery.
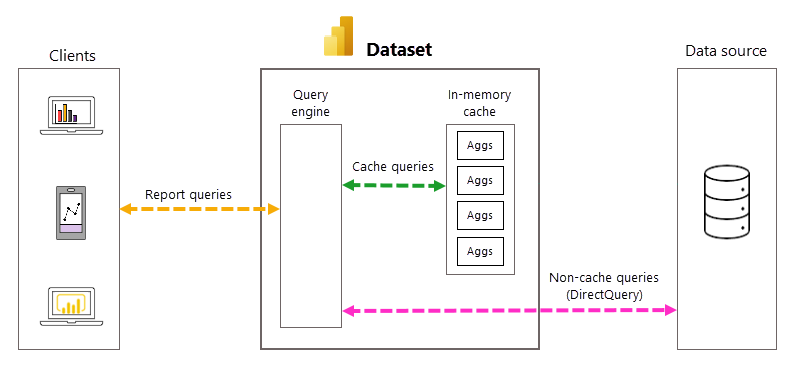
Автоматическое управление запросами и агрегатами
Хотя автоматические агрегаты устраняют необходимость создания пользовательских таблиц агрегирования и значительно упрощают реализацию предварительно агрегированного решения данных, более глубокое знакомство с базовыми процессами и зависимостями полезно в понимании того, как работают автоматические агрегаты. Power BI использует следующее для создания автоматических агрегатов и управления ими.
Данные журнала
Power BI отслеживает запросы модели и пользовательских отчетов в журнале запросов. Для каждой модели Power BI поддерживает семь дней данных журнала запросов. Данные журнала запросов развертываются каждый день. Журнал запросов является безопасным и не видимым для пользователей или через конечную точку XMLA.
Учебные операции
В рамках первой запланированной операции обновления модели для выбранной частоты (день или неделя) Power BI сначала инициирует обучающую операцию, которая оценивает журнал запросов, чтобы обеспечить агрегирование в кэше агрегатов в памяти, адаптируясь к изменению шаблонов запросов. Таблицы агрегирования в памяти создаются, обновляются или удаляются, а специальные запросы отправляются в источник данных, чтобы определить агрегаты для включения в кэш. Однако вычисляемые статистические данные не загружаются в кэш в памяти во время обучения. Он загружается во время последующей операции обновления.
Например, если вы выберете частоту дня и расписание обновляется в 4:00 УТРА, 9:00 УТРА, 2:00 и 7:00, только обновление 4:00AM каждый день будет включать как операцию обучения , так и операцию обновления. Последующие обновления 9:00 УТРА, 2:00 и 7:00 вечера, запланированные обновления в течение этого дня, являются только операциями обновления, которые обновляют существующие агрегаты в кэше.
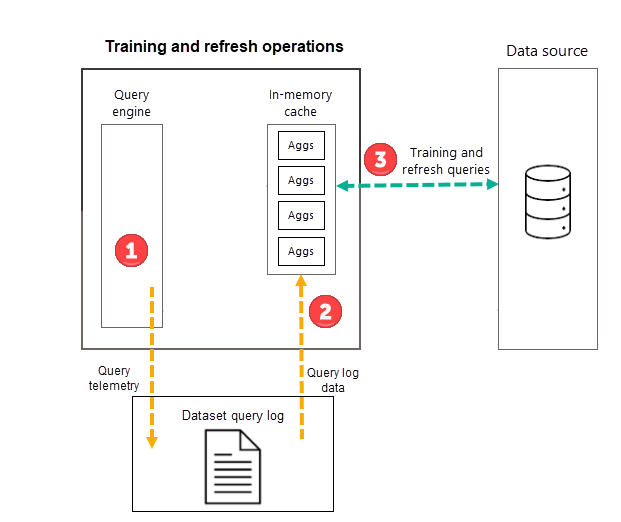
Хотя учебные операции оценивают прошлые запросы из журнала запросов, результаты достаточно точны, чтобы обеспечить покрытие будущих запросов. Однако нет никакой гарантии, что будущие запросы будут возвращены кэшом агрегатов в памяти, так как эти новые запросы могут отличаться от тех, которые получены из журнала запросов. Эти запросы, не возвращаемые кэшем агрегирования в памяти, передаются в источник данных с помощью DirectQuery. В зависимости от частоты и ранжирования этих новых запросов агрегаты для них могут быть включены в кэш агрегатов в памяти с помощью следующей операции обучения.
Операция обучения имеет 60-минутное ограничение времени. Если обучение не может обработать весь журнал запросов в течение ограниченного времени, уведомление регистрируется в журнале обновления модели и обучение возобновляется при следующем запуске. Учебный цикл завершается и заменяет существующие автоматические агрегаты при обработке всего журнала запросов.
Операции обновления
Как описано ранее, после завершения операции обучения в рамках первого запланированного обновления для выбранной частоты Power BI выполняет операцию обновления, которая запрашивает и загружает новые и обновленные агрегации данных в кэш агрегатов в памяти и удаляет все агрегаты, которые больше не рангируются достаточно высоко (как определено алгоритмом обучения). Все последующие обновления для выбранной частоты дня или недели — это только операции обновления, запрашивающие источник данных для обновления существующих агрегированных данных в кэше. Используя наш предыдущий пример, запланированные обновления 9:00AM, 2:00PM и 7:00PM запланированные обновления в течение этого дня являются только операциями обновления.
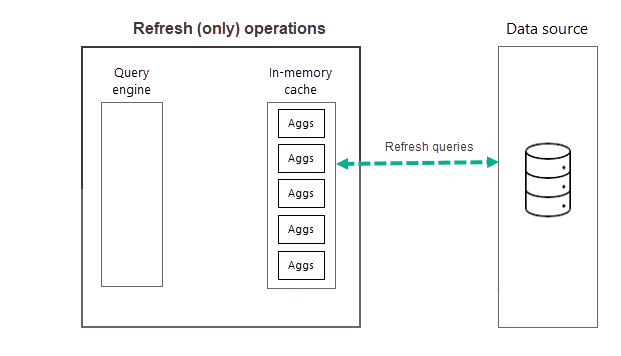
Регулярно запланированные обновления в течение дня (или недели) гарантируют, что агрегирование данных в кэше более актуально с данными в серверном источнике данных. С помощью Параметры модели можно запланировать до 48 обновлений в день, чтобы убедиться, что запросы отчетов, возвращаемые кэшем агрегатов, получают результаты на основе последних обновленных данных из внутреннего источника данных.
Внимание
Операции обучения и обновления являются процессом и ресурсоемким для служба Power BI и систем источников данных. Увеличение процента запросов, использующих агрегаты, означает, что больше агрегатов необходимо запрашивать и вычислять из источников данных во время обучения и обновления, повышая вероятность чрезмерного использования системных ресурсов и потенциально вызывая тайм-аут. Дополнительные сведения см. в разделе "Подробные сведения о настройке".
Обучение по запросу
Как упоминание ранее, цикл обучения может не завершиться в течение одного цикла обновления данных. Если вы не хотите ждать до следующего запланированного цикла обновления, включающего обучение, можно также активировать автоматическое обучение по запросу, выбрав "Обучение и обновление сейчас" в модели Параметры. С помощью обучения и обновления теперь активируется как операция обучения, так и операция обновления. Проверьте журнал обновления модели, чтобы узнать, завершена ли текущая операция перед выполнением другой операции обучения по запросу и обновления при необходимости.
Журнал обновлений
Каждая операция обновления записывается в журнал обновления модели. Отображаются важные сведения о каждом обновлении, включая количество агрегирования памяти в кэше, которое используется для настроенного процента запросов. Чтобы просмотреть журнал обновления, на странице Параметры модели выберите журнал обновления. Если вы хотите выполнить детализацию немного дальше, выберите " Показать сведения".
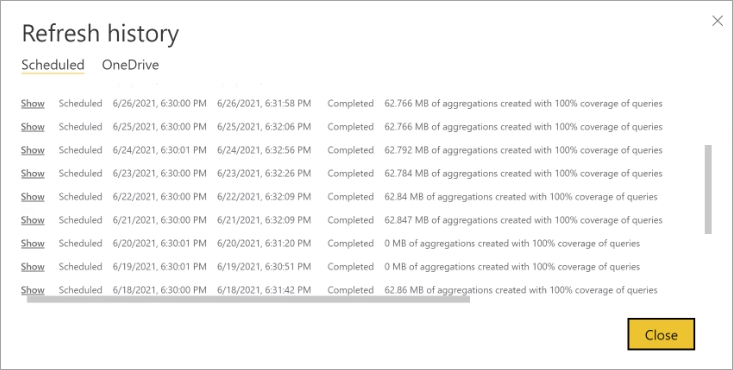
Регулярно проверка журнал обновления, вы можете убедиться, что запланированные операции обновления выполняются в течение допустимого периода. Убедитесь, что операции обновления успешно завершаются до начала следующего запланированного обновления.
Сбои обучения и обновления
Хотя Power BI выполняет операции обучения и обновления в рамках первого запланированного обновления в течение выбранного дня или недели, эти операции реализуются в виде отдельных транзакций. Если операция обучения не может полностью обработать журнал запросов в пределах времени, Power BI будет продолжать обновлять существующие агрегаты (и обычные таблицы в составной модели) с помощью предыдущего состояния обучения. В этом случае журнал обновления будет указывать на успешное обновление, и обучение будет возобновлять обработку журнала запросов при следующем запуске обучения. Производительность запросов может быть менее оптимизирована, если шаблоны запросов клиентского отчета изменились и агрегаты еще не корректирулись, но достигнутый уровень производительности по-прежнему должен быть гораздо лучше, чем чистая модель DirectQuery без каких-либо агрегатов.
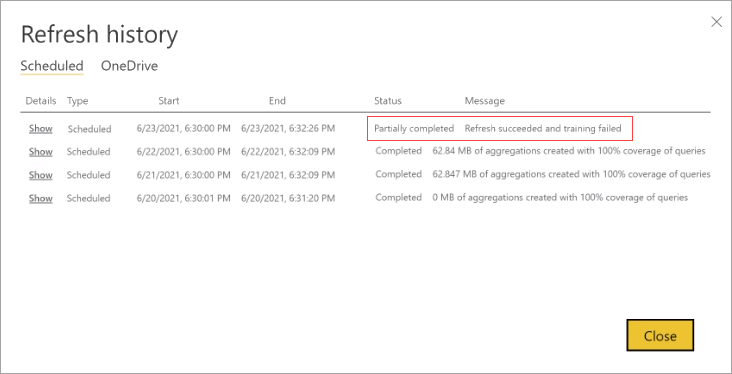
Если для завершения обработки журнала запросов требуется слишком много циклов, рекомендуется уменьшить процент запросов, использующих кэш агрегирования в памяти в Параметры модели. Это уменьшит количество агрегатов, созданных в кэше, но позволить больше времени для выполнения операций обучения и обновления. Дополнительные сведения см. в разделе "Подробные сведения о настройке".
Если обучение завершается успешно, но обновление завершается ошибкой, все обновление помечается как неудачное, так как результат является недоступным кэшом агрегатов в памяти.
При планировании обновления можно указать Уведомления по электронной почте, если возникают сбои обновления.
Определяемые пользователем и автоматические агрегаты
Определяемые пользователем агрегаты в Power BI можно настроить вручную на основе скрытых статистических таблиц в модели. Настройка определяемых пользователем агрегатов часто сложна, требуя большего уровня навыков моделирования данных и оптимизации запросов. С другой стороны, автоматические агрегаты устраняют эту сложность в рамках системы, управляемой ИИ. В отличие от определяемых пользователем агрегатов, которые остаются статическими, Power BI постоянно сохраняет журналы запросов и из этих журналов определяет шаблоны запросов на основе алгоритмов прогнозного моделирования машинного обучения (ML). Предварительно агрегированные данные вычисляются и хранятся в памяти на основе анализа шаблонов запросов. С автоматическими агрегатами модели являются самообучением и самооптимизацией. По мере изменения шаблонов запросов к клиентскому отчету автоматические агрегаты настраиваются, приоритеты и кэширование этих агрегатов чаще всего используются.
Так как автоматические агрегаты создаются на основе существующей пользовательской инфраструктуры агрегатов, можно использовать определяемые пользователем и автоматические агрегаты в одной модели. Опытные моделиаторы данных могут определять агрегаты для таблиц с помощью DirectQuery, импорта (с добавочным обновлением или без него) или режимов двойного хранения, а также использовать более автоматические агрегаты для запросов через подключения DirectQuery, которые не попадают в определяемые пользователем таблицы агрегирования. Эта гибкость обеспечивает сбалансированные архитектуры, которые могут снизить нагрузку запросов и избежать узких мест.
Агрегаты, созданные в кэше в памяти алгоритмом обучения автоматических агрегатов, определяются как System агрегаты. Алгоритм обучения создает и удаляет только эти System агрегаты, так как запросы отчетов анализируются и корректируются для поддержания оптимальных агрегатов для модели. Определяемые пользователем и автоматические агрегаты обновляются с помощью обновления. Только эти агрегаты, созданные автоматическими агрегатами и помеченные как системные агрегаты, включаются в автоматическую обработку агрегатов.
Кэширование запросов и автоматическое агрегирование
Power BI Premium также поддерживает кэширование запросов в Power BI Premium/Embedded для поддержания результатов запроса. Кэширование запросов отличается от автоматических агрегатов. При кэшировании запросов Power BI Premium использует свою локальную службу кэширования для реализации кэширования, а автоматические агрегаты реализуются на уровне модели. При кэшировании запросов служба кэширует запросы только для начальной загрузки страницы отчета, поэтому производительность запросов не улучшается при взаимодействии пользователей с отчетом. В отличие от этого, автоматические агрегаты оптимизируют большинство запросов отчетов путем предварительного кэширования агрегированных результатов запроса, включая эти запросы, созданные при взаимодействии пользователей с отчетами. Кэширование запросов и автоматические агрегаты могут быть включены для модели, но это, скорее всего, не обязательно.
Мониторинг с помощью Log Analytics
Azure Log Analytics (LA) — это служба в Azure Monitor, которую Power BI может использовать для сохранения журналов действий. С помощью набора Azure Monitor можно собирать, анализировать и действовать с данными телеметрии из azure и локальных сред. Он предлагает долгосрочное хранение, нерегламентированный интерфейс запроса и доступ API для разрешения экспорта и интеграции данных с другими системами. Дополнительные сведения см. в статье Об использовании Azure Log Analytics в Power BI.
Если Power BI настроена с учетной записью Azure LA, как описано в разделе "Настройка Azure Log Analytics для Power BI", можно проанализировать скорость успешного выполнения автоматических агрегатов. Помимо прочего, можно определить, отвечают ли запросы отчета из кэша в памяти.
Чтобы использовать эту возможность, скачайте шаблон PBIT и подключите его к учетной записи log analytics, как описано в этой записи блога Power BI. В отчете можно просматривать данные на трех разных уровнях: представление сводки, представление уровня запросов DAX и представление уровня SQL-запросов.
На следующем рисунке показана страница сводки для всех запросов. Как видно, помеченная диаграмма показывает процент общих запросов, которые были удовлетворены агрегатами и теми, которые должны были использовать источник данных.
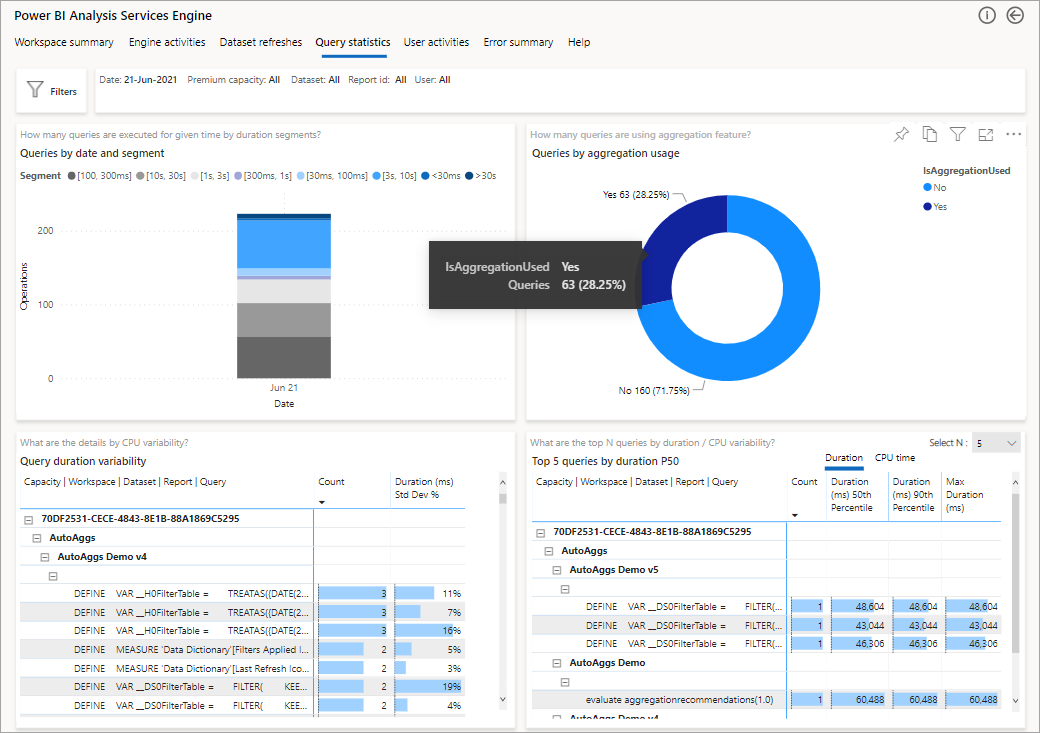
Следующий шаг для более глубокого анализа заключается в использовании агрегатов на уровне запроса DAX. Щелкните правой кнопкой мыши запрос DAX из списка (слева) >Детализация по>журналу запросов.
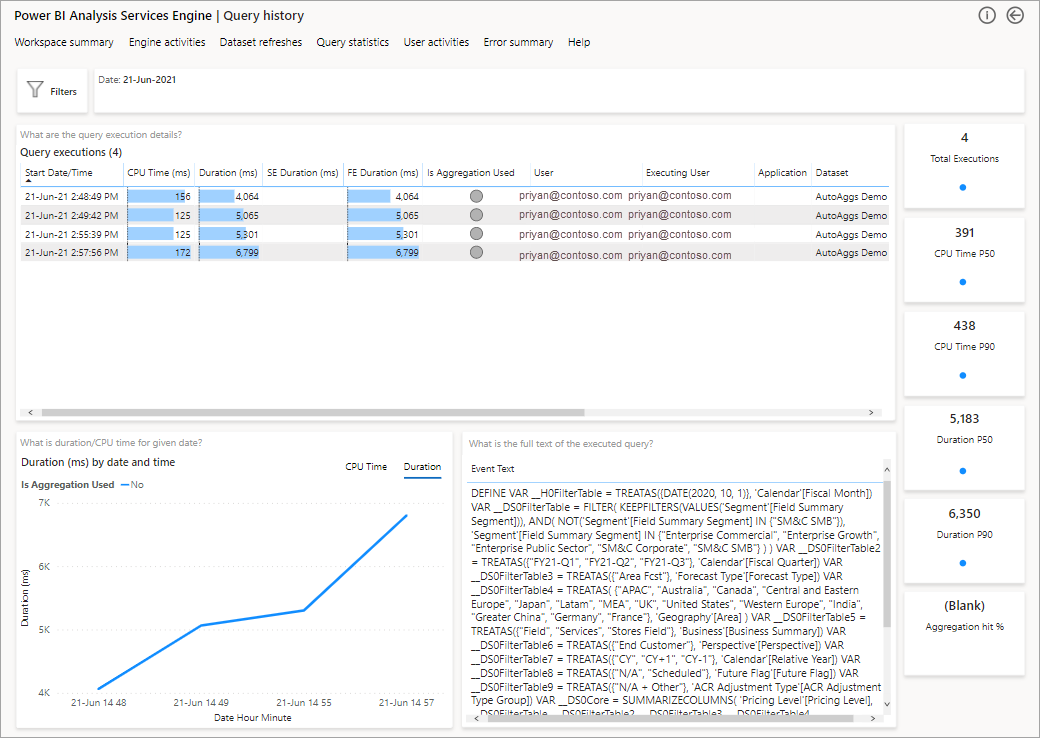
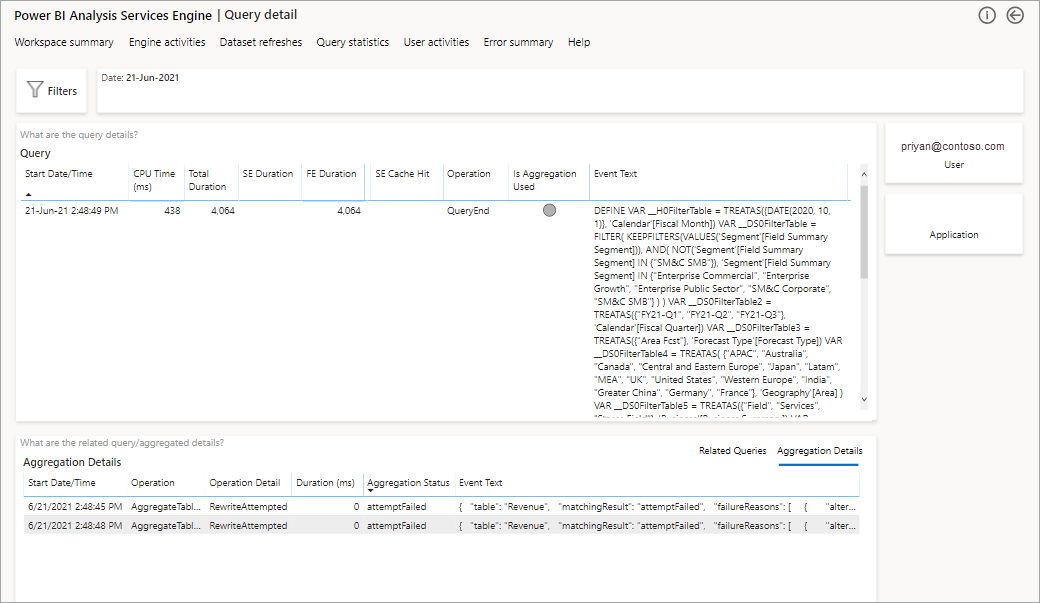
Это позволит вам получить список всех соответствующих запросов. Детализация до следующего уровня, чтобы отобразить дополнительные сведения об агрегации.
Управление жизненным циклом приложения
От разработки до тестирования и от тестирования до рабочей среды модели с автоматическими агрегатами включены специальные требования для решений ALM.
Конвейеры развертывания
С помощью конвейеров развертывания Power BI может скопировать модели с конфигурацией модели с текущей стадии на целевой этап. Однако автоматическое агрегирование должно быть сброшено на целевом этапе, так как параметры не передаются из текущего на целевой этап. Вы также можете программно развертывать содержимое с помощью интерфейсов REST API конвейеров развертывания. Дополнительные сведения об этом процессе см. в статье "Автоматизация конвейера развертывания" с помощью API и DevOps.
Пользовательские решения ALM
Если вы используете пользовательское решение ALM на основе конечных точек XMLA, помните, что ваше решение может копировать созданные системой и созданные пользователем таблицы агрегирования в рамках метаданных модели. Однако необходимо включить автоматические агрегаты после каждого шага развертывания на целевом этапе вручную. Power BI сохранит конфигурацию при перезаписи существующей модели.
Примечание.
Если вы отправляете или повторно публикуете модель в составе файла Power BI Desktop (PBIX), созданные системой таблицы агрегирования теряются, так как Power BI заменяет существующую модель всеми ее метаданными и данными в целевой рабочей области.
Изменение модели
После изменения модели с автоматическими агрегатами, включенными с помощью конечных точек XMLA, таких как добавление или удаление таблиц, Power BI сохраняет все существующие агрегаты, которые могут быть и удаляют те, которые больше не нужны или важны. Производительность запросов может повлиять до запуска следующего этапа обучения.
Элементы метаданных
Модели с включенными автоматическими агрегатами содержат уникальные таблицы агрегирования, созданные системой. Таблицы агрегирования не видны пользователям в средствах создания отчетов. Они отображаются через конечную точку XMLA с помощью средств с клиентскими библиотеками служб Analysis Services версии 19.22.5 и выше. При работе с моделями с включенными автоматическими агрегатами обязательно обновите средства моделирования данных и администрирования до последней версии клиентских библиотек. Для SQL Server Management Studio (SSMS) выполните обновление до SSMS версии 18.9.2 или более поздней. Более ранние версии SSMS не могут перечислять таблицы или скрипты из этих моделей.
Автоматические статистические таблицы определяются свойством SystemManaged таблицы, которое является новым для табличной объектной модели (TOM) в клиентских библиотеках служб Analysis Services версии 19.22.5 и более поздних версий. В следующем фрагменте кода показано свойство, заданное SystemManagedtrue для таблиц автоматической агрегирования и false для обычных таблиц.
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.AnalysisServices.Tabular;
namespace AutoAggs
{
class Program
{
static void Main(string[] args)
{
string workspaceUri = "<Specify the URL of the workspace where your model resides>";
string datasetName = "<Specify the name of your dataset>";
Server sourceWorkspace = new Server();
sourceWorkspace.Connect(workspaceUri);
Database dataset = sourceWorkspace.Databases.GetByName(datasetName);
// Enumerate system-managed tables.
IEnumerable<Table> aggregationsTables = dataset.Model.Tables.Where(tbl => tbl.SystemManaged == true);
if (aggregationsTables.Any())
{
Console.WriteLine("The following auto aggs tables exist in this dataset:");
foreach (Table table in aggregationsTables)
{
Console.WriteLine($"\t{table.Name}");
}
}
else
{
Console.WriteLine($"This dataset has no auto aggs tables.");
}
Console.WriteLine("\n\rPress [Enter] to exit the sample app...");
Console.ReadLine();
}
}
}
При выполнении этого фрагмента выходные данные автоматически агрегирования таблиц, включенных в модель в консоли.
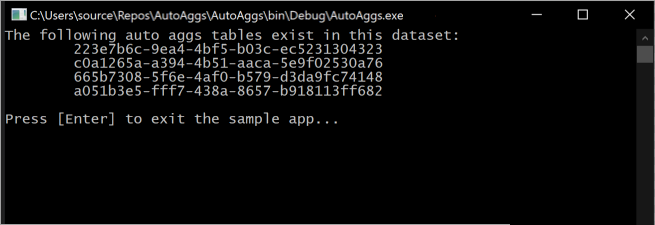
Имейте в виду, что таблицы агрегирования постоянно меняются, так как операции обучения определяют оптимальные агрегаты для включения в кэш агрегатов в памяти.
Важно!
Power BI полностью управляет объектами таблицы, созданными системой, автоматически агрегированием. Не удаляйте и не изменяйте эти таблицы самостоятельно. Это может привести к снижению производительности.
Power BI поддерживает конфигурацию модели за пределами модели. Наличие таблицы агрегирования, управляемой системой, в модели не обязательно означает, что модель фактически включена для автоматического обучения агрегатов. Другими словами, если вы создаете полное определение модели для модели с включенными автоматическими агрегатами и создаете новую копию модели (с другим именем/ рабочей областью или емкостью), новая результирующая модель не включена для автоматического обучения агрегирования. Вам по-прежнему необходимо включить автоматическое обучение агрегатов для новой модели в Параметры модели.
Рекомендации и ограничения
При использовании автоматических агрегатов помните следующее:
- Агрегаты не поддерживают динамические параметры запросов M.
- Запросы SQL, созданные на начальном этапе обучения, могут создать значительную нагрузку для хранилища данных. Если обучение завершается неполным и вы можете проверить на стороне хранилища данных, что запросы сталкиваются с временем ожидания, рассмотрите возможность временного масштабирования хранилища данных в соответствии с требованиями обучения.
- Агрегаты, хранящиеся в кэше агрегатов в памяти, могут не вычисляться на последних данных в источнике данных. В отличие от чистого DirectQuery и более таких, как обычные таблицы импорта, между обновлениями в источнике данных и агрегированием данных, хранящимися в кэше агрегатов в памяти. Хотя всегда будет некоторая степень задержки, она может быть устранена с помощью эффективного расписания обновления.
- Чтобы оптимизировать производительность, задайте для всех таблиц измерений двойной режим и оставьте таблицы фактов в режиме DirectQuery.
- Автоматические агрегаты недоступны в Power BI Pro, Службах Azure Analysis Services или СЛУЖБАх SQL Server Analysis Services.
- Power BI не поддерживает скачивание моделей с включенными автоматическими агрегатами. Если вы добавили или опубликовали файл Power BI Desktop (PBIX) в Power BI, а затем включили автоматические агрегаты, вы больше не сможете скачать PBIX-файл. Убедитесь, что копия PBIX-файла хранится локально.
- Автоматические агрегаты с внешними таблицами в Azure Synapse Analytics не поддерживаются. Вы можете перечислить внешние таблицы в Synapse с помощью следующего SQL-запроса:
SELECT SCHEMA_NAME(schema_id) AS schema_name, name AS table_name FROM sys.external_tables - Автоматические агрегаты доступны только для моделей с помощью расширенных метаданных. Если вы хотите включить автоматические агрегаты для более старой модели, обновите модель до расширенных метаданных. Дополнительные сведения см. в разделе "Использование расширенных метаданных модели".
- Не включите автоматические агрегаты, если источник данных DirectQuery настроен для единого входа и использует динамические представления данных или элементы управления безопасностью для ограничения доступа к данным, к которым пользователь может получить доступ. Автоматические агрегаты не знают об этих элементах управления уровня источника данных, что делает невозможным обеспечить предоставление правильных данных на основе каждого пользователя. Обучение записывает предупреждение в журнал обновления, которое оно обнаружило источник данных, настроенный для единого входа, и пропустил таблицы, использующие этот источник данных. Если это возможно, отключите единый вход для этих источников данных, чтобы воспользоваться всеми преимуществами оптимизированных статистических агрегатов производительности запросов.
- Не включите автоматические агрегаты, если модель содержит только гибридные таблицы, чтобы избежать ненужных затрат на обработку. Гибридная таблица использует как секции импорта, так и секцию DirectQuery. Распространенный сценарий — добавочное обновление с данными в режиме реального времени, в которых секция DirectQuery извлекает транзакции из источника данных, который произошел после последнего обновления данных. Однако Power BI импортирует агрегаты во время обновления. Автоматические агрегаты не могут включать транзакции, которые произошли после последнего обновления данных. Обучение записывает предупреждение в журнал обновления, которое оно обнаружило и пропустил гибридные таблицы.
- Вычисляемые столбцы не считаются автоматическими агрегатами. Если вы используете вычисляемый столбец в режиме DirectQuery, например с помощью
COMBINEVALUESфункции DAX для создания связи на основе нескольких столбцов из двух таблиц DirectQuery, соответствующие запросы отчета не попадют в кэш агрегатов в памяти. - Автоматические агрегаты доступны только в служба Power BI. Power BI Desktop не создает системные статистические таблицы.
- Если вы изменяете метаданные модели с включенными автоматическими агрегатами, производительность запросов может снизиться до запуска следующего процесса обучения. Рекомендуется удалить автоматические агрегаты, внести изменения, а затем переобучить.
- Не изменяйте или не удаляйте таблицы агрегирования, созданные системой, если у вас нет автоматических агрегатов и очистки модели. Система отвечает за управление этими объектами.
Сообщество
Power BI имеет активное сообщество, где MVPs, бизнес-специалисты и одноранговые специалисты делятся опытом в группах обсуждений, видео, блогах и многое другое. При обучении автоматическим агрегатам обязательно проверка эти другие ресурсы:
Связанный контент
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по