Примечание
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Агрегаты в Power BI могут повысить производительность запросов в больших семантических моделях DirectQuery. С помощью агрегатов данные кэшируются на агрегированном уровне в памяти. Агрегации в Power BI можно настроить вручную в модели данных, как описано в этой статье. Для подписок Premium автоматически активируйте функцию автоматической агрегации в параметрах модели.
Создание таблиц агрегирования
В зависимости от типа источника данных таблица агрегирования может быть создана в источнике данных в виде таблицы или представления собственного запроса. Для максимальной производительности создайте таблицу агрегирования в виде таблицы импорта, созданной в Power Query. Затем вы используете диалоговое окно "Управление агрегатами" в Power BI Desktop, чтобы определить агрегаты для столбцов агрегирования с сводных данных, таблицей сведений и свойствами столбцов сведений.
Многомерные источники данных, такие как хранилища данных и витрины данных, могут использовать агрегации на основе отношений. Источники больших данных на основе Hadoop часто строят агрегаты на основе столбцов GroupBy. В этой статье описываются типичные различия в моделировании данных Power BI для каждого типа источника данных.
Управление агрегациями
В области данных любого представления Power BI Desktop щелкните правой кнопкой мыши таблицу агрегирования и выберите Управление агрегатами.
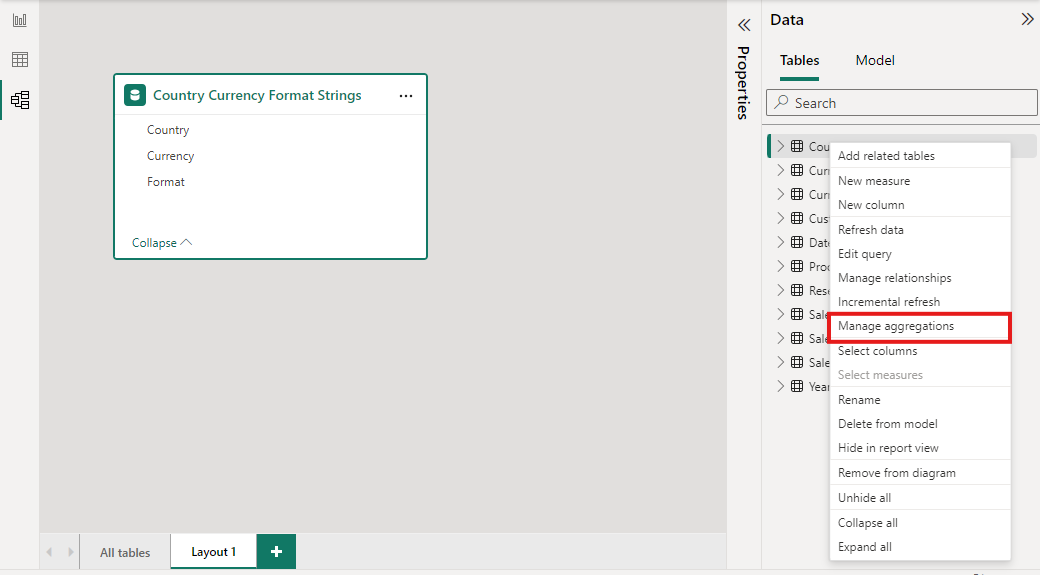
В диалоговом окне управления агрегатами отображается строка для каждого столбца таблицы, где можно указать поведение агрегирования. В следующем примере запросы к таблице сведений о Sales перенаправляются во внутреннюю таблицу агрегации Sales Agg.
В этом примере агрегирования на основе связей записи GroupBy являются необязательными. За исключением DISTINCTCOUNT, они не влияют на агрегирование и в основном предназначены для удобства чтения. Без записей GroupBy агрегаты все равно будут срабатывать на основе связей. Это отличается от примера больших данных далее в этой статье, где требуются записи GroupBy.
Проверки
Диалоговое окно Управление агрегатами применяет проверки:
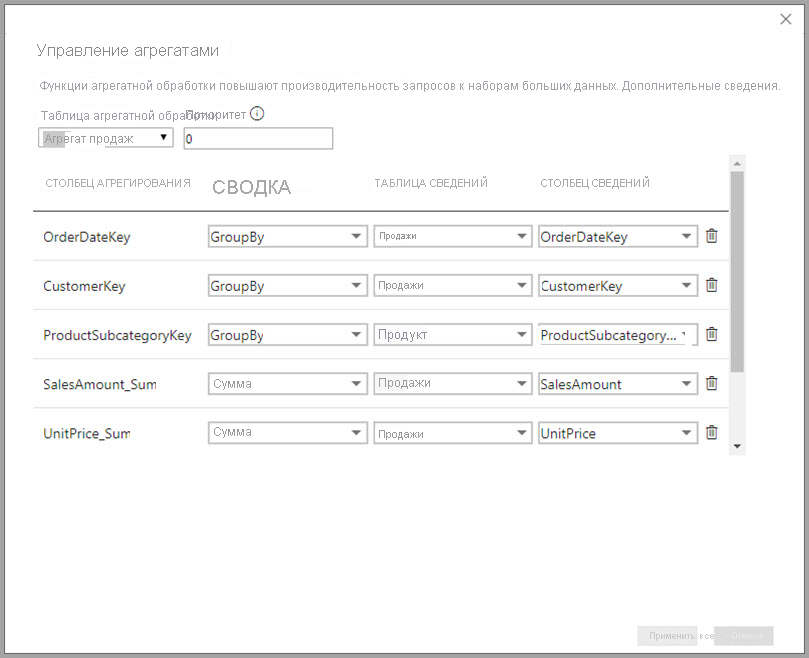
- Столбец подробных данных должен иметь тот же тип данных, что и столбец агрегирования, за исключением случаев использования функций Count и строк таблицы Count в контексте функций сводки. Строки таблицы count и Count доступны только для целых столбцов агрегирования и не требуют соответствующего типа данных.
- Цепное агрегирование, охватывающее три или более таблиц, не допускается. Например, агрегации в таблице A не могут ссылаться на таблицу B, которая имеет агрегации, ссылающиеся на таблицу C.
- Повторяющиеся агрегаты, в которых две записи используют одну и ту же функцию сводки и ссылаются на одну и ту же таблицу сведений и столбец сведений , не допускаются.
- Таблица сведений должна использовать режим хранения DirectQuery, а не импорт.
- Группировка по столбцу внешнего ключа, используемого неактивной связью, и использование функции USERELATIONSHIP для агрегации данных не поддерживается.
- Агрегаты на основе столбцов GroupBy могут использовать связи между таблицами агрегирования, но создание связей между таблицами агрегирования не поддерживается в Power BI Desktop. При необходимости, вы можете создавать связи между таблицами агрегирования с помощью стороннего инструмента или решения на основе скриптов через конечные точки XMLA (XML for Analysis).
Большинство проверок применяются путем отключения раскрывающихся значений и отображения пояснительных текста в подсказке.
Таблицы агрегирования скрыты
Пользователи с доступом только для чтения к модели не могут запрашивать таблицы агрегирования. Доступ только для чтения позволяет избежать проблем безопасности при использовании безопасности на уровне строк (RLS). Потребители и запросы ссылаются на таблицу сведений, а не таблицу агрегирования и не нужно знать о таблице агрегирования.
По этой причине таблицы агрегирования скрыты из представления отчета. Если таблица еще не скрыта, диалоговое окно Управление агрегированиями сделает ее скрытой при выборе Применить все.
Режимы хранения
Функция агрегирования взаимодействует с режимами хранения на уровне таблицы. Таблицы Power BI могут использовать DirectQuery, Import, или Dual режимы хранения. DirectQuery запрашивает базу данных напрямую, а режим Import кэширует данные в памяти и отправляет запросы к кэшированным данным. Все источники данных DirectQuery и импорта Power BI, не являющиеся многомерными, могут работать с агрегатами.
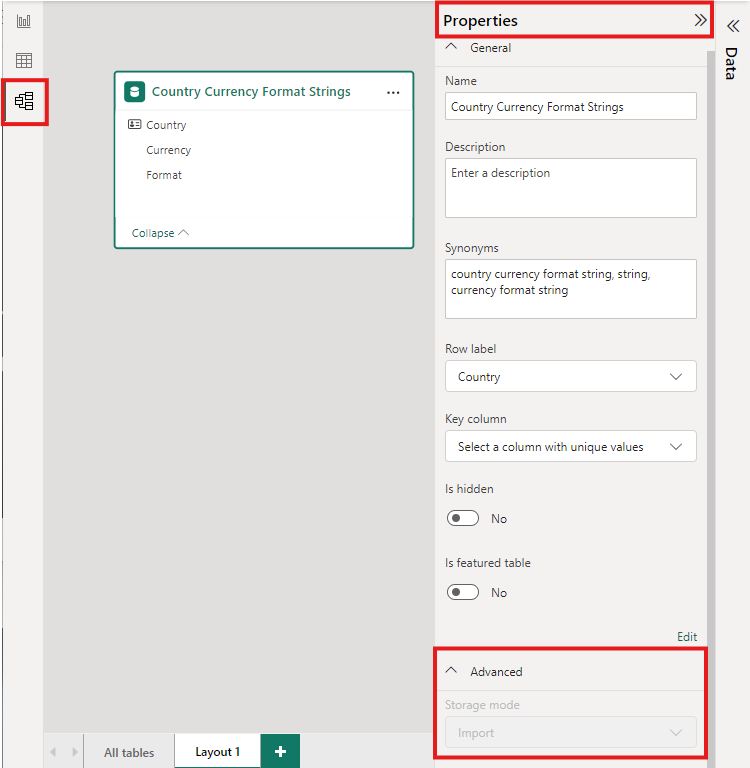
Чтобы задать режим хранения агрегированной таблицы для импорта, чтобы ускорить запросы, выберите агрегированную таблицу в представлении модели Power BI Desktop. В области свойств разверните узел Advanced, в раскрывающемся списке в режиме храненияи выберите Импорт. Изменение импорта необратимо.
Дополнительные сведения о режимах хранения таблиц см. в статье Управление режимом хранения в Power BI Desktop.
RLS для агрегаций
Чтобы правильно работать для агрегирования, выражения RLS должны фильтровать таблицу агрегирования и таблицу сведений.
В следующем примере выражение RLS в таблице Geography работает для агрегирования, так как Geography находится на стороне фильтрации связей с таблицей Sales и таблицей Sales Agg. Запросы, которые попали в таблицу агрегирования, и запросы, к которым не был успешно применён RLS.
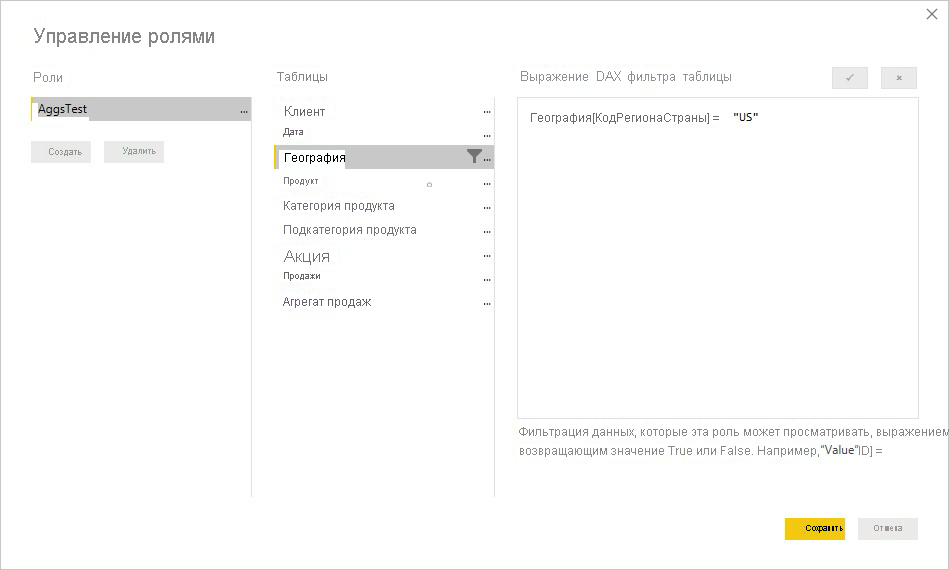
Выражение RLS в таблице Product фильтрует только подробную таблицу Sales, а не агрегированную таблицу Sales Agg. Так как таблица агрегирования является другим представлением данных в таблице сведений, небезопасно отвечать на запросы из таблицы агрегирования, если фильтр RLS не может быть применен. Фильтрация только таблицы сведений не рекомендуется, так как запросы пользователей из этой роли не получают преимущества от агрегирования.
Выражение RLS, которое фильтрует только таблицу агрегирования Sales Agg, а не таблицу деталей продаж Sales, не разрешается.

Для агрегатов на основе столбцов GroupByможно использовать выражение RLS, примененное к детальной таблице, для фильтрации таблицы агрегации, так как все столбцы GroupBy в таблице агрегации покрываются детальной таблицей. С другой стороны, фильтр RLS в агрегированной таблице не может быть применен к таблице сведений, и поэтому это не допускается.
Агрегирование на основе связей
Модели измерений обычно используют агрегации на основе связей. Модели Power BI из хранилищ данных и киосков данных похожи на схемы star/snowflake с связями между таблицами измерений и таблицами фактов.
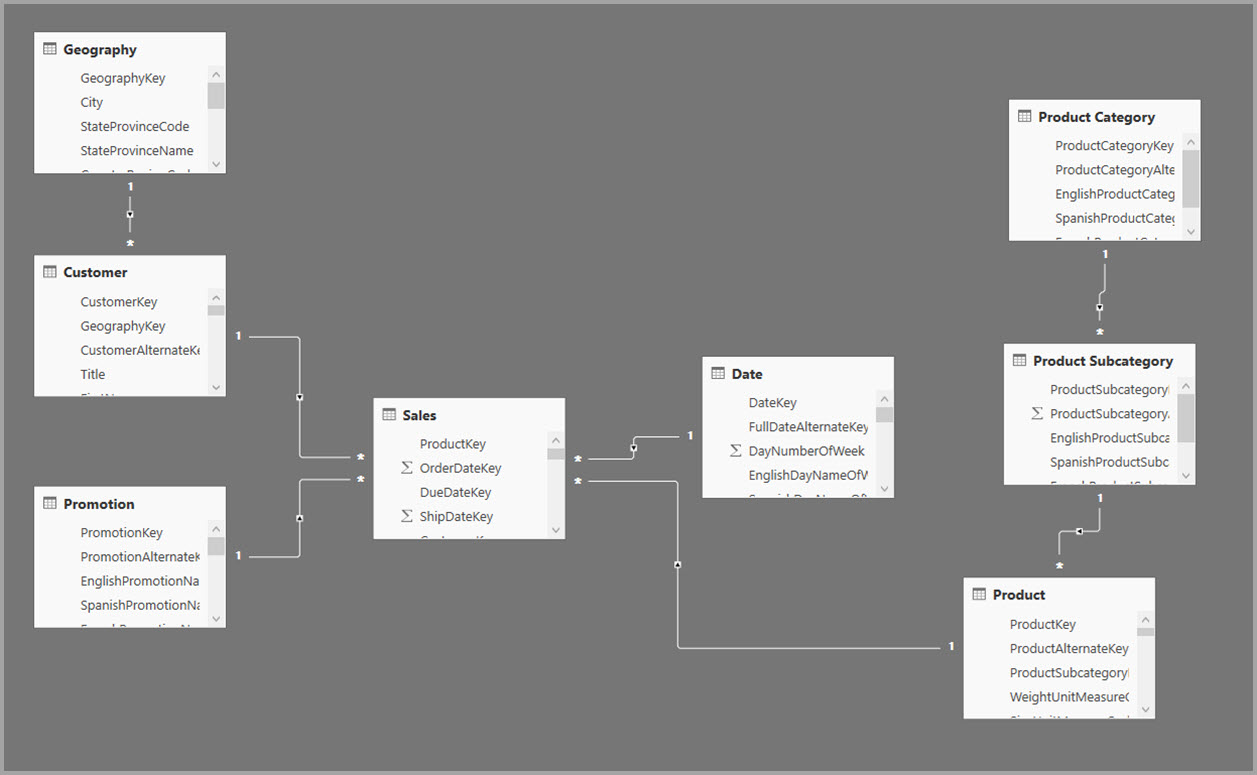
В следующем примере модель получает данные из одного источника данных. Таблицы используют режим хранения DirectQuery. Таблица фактов Sales содержит миллиарды строк. Установка режима хранения sales импорта для кэширования будет потреблять значительные затраты на память и ресурсы.
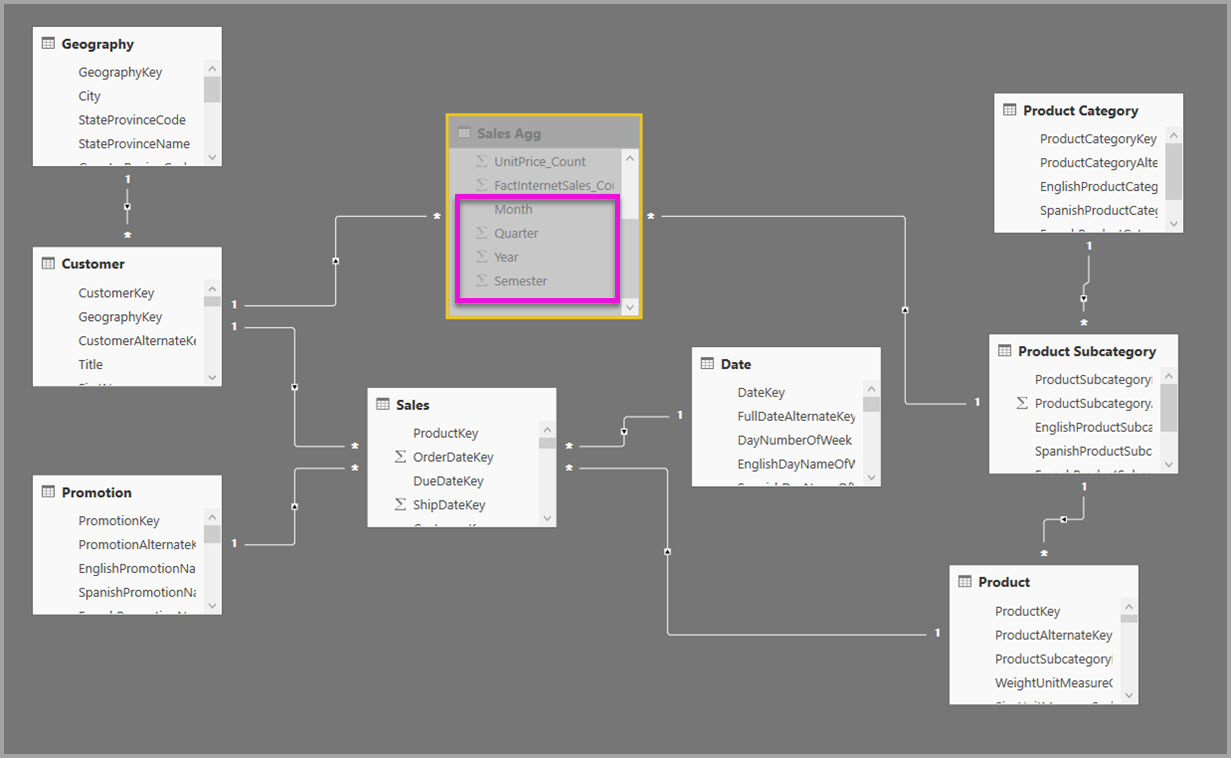
Вместо этого создайте таблицу агрегирования Sales Agg. В таблице Sales Agg количество строк равно сумме SalesAmount, сгруппированных по CustomerKey, DateKeyи ProductSubcategoryKey. Таблица sales Agg имеет более высокую степень детализации, чем sales, поэтому вместо миллиардов, она может содержать миллионы строк, которые проще управлять.
Если в следующих таблицах измерений чаще всего используются запросы с высокой бизнес-ценностью, они могут фильтровать Sales Agg, используя одно ко многим или отношениях "многие ко одному".
- География
- Клиент
- Дата
- Подкатегория продукта
- Категория продукта
На следующем рисунке показана эта модель.
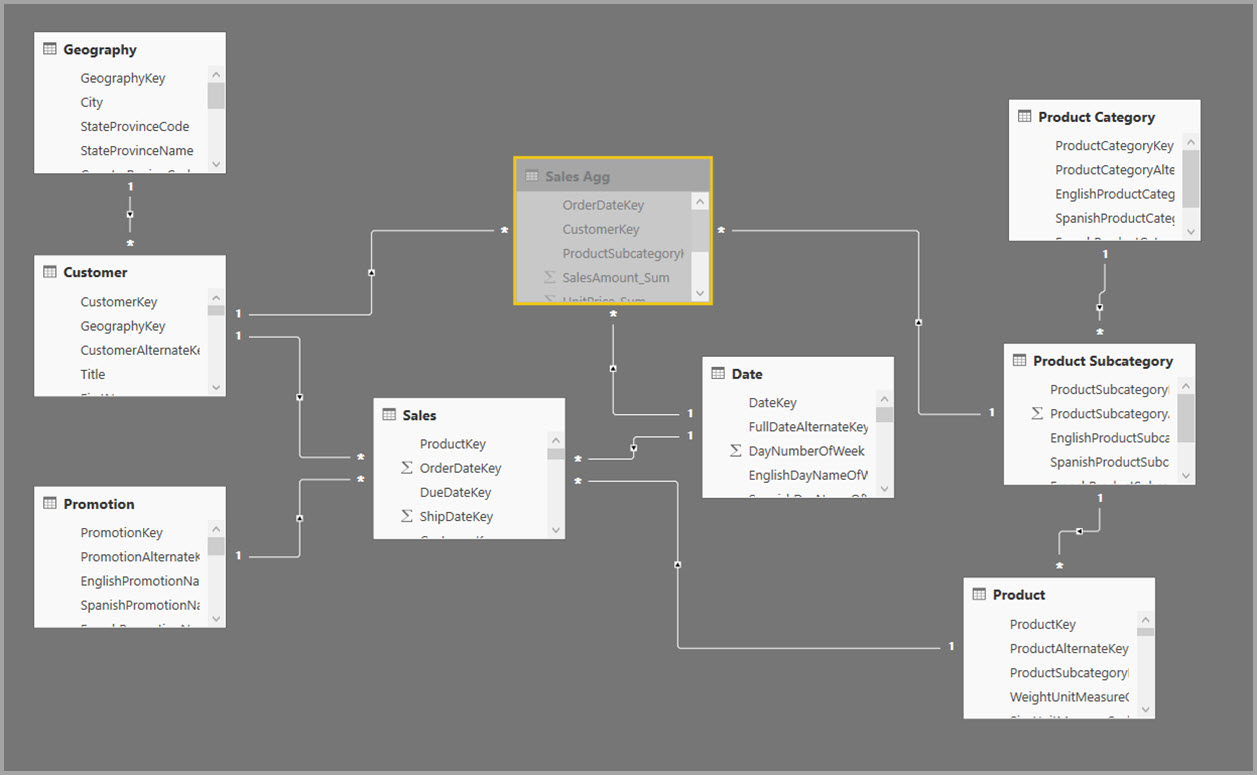
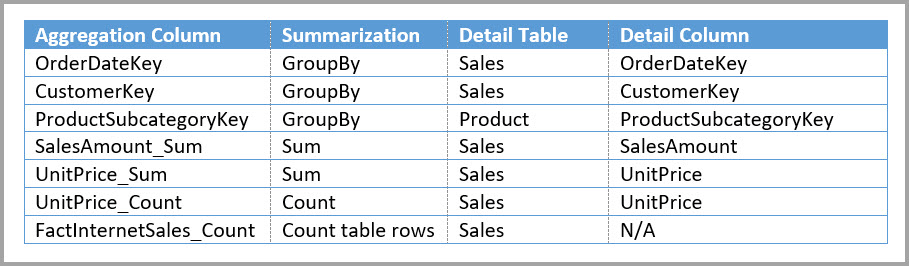
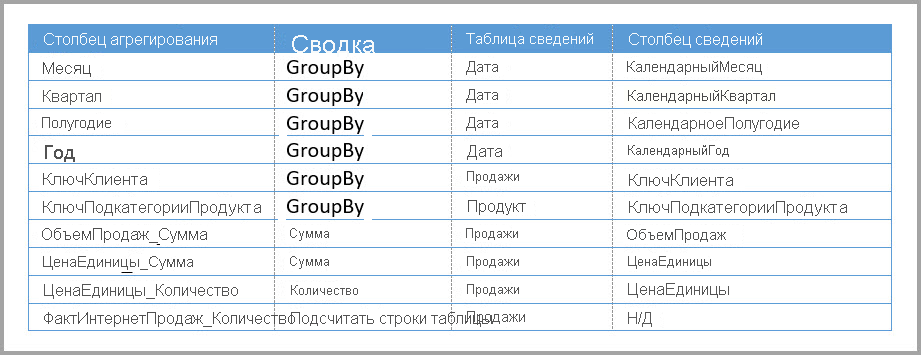
В следующей таблице показаны агрегации для таблицы Sales Agg.
Примечание.
Таблица Sales Agg , как и любая таблица, имеет гибкость загрузки различными способами. Агрегирование можно выполнить в исходной базе данных с помощью процессов ETL/ELT или выражения M , применяемого к таблице. Агрегированная таблица может использовать режим импорта хранилища, с добавочного обновления для семантических моделейили использовать DirectQuery и оптимизировать для быстрых запросов с помощью индексов columnstore. Эта гибкость позволяет архитектурам быть сбалансированными и способными распределять нагрузку запросов, чтобы избежать узких мест.
Изменение режима хранения агрегированной таблицы Sales Agg на Import открывает диалоговое окно, указывающее, что связанные таблицы измерений можно задать для режима хранения Dual.
диалоговое окно Storage mode dialogрежима хранения
Storage mode dialogрежима хранения
Если для связанных таблиц измерений задано значение "Dual", они могут работать как "Импорт", так и "DirectQuery" в зависимости от подзапроса. В примере:
- Запросы, которые агрегируют метрики из таблицы импорта Sales Agg и группируют по атрибутам из связанных Dual таблиц, могут быть возвращены из кэша в памяти.
- Запросы, которые агрегируют метрики из таблицы DirectQuery Sales и группируются по атрибутам из связанных двух таблиц, можно вернуть в режиме DirectQuery. Логика запроса, включая операцию GroupBy, передается в исходную базу данных.
Дополнительные сведения о режиме двойного хранения см. в разделе Управление режимом хранения в Power BI Desktop.
Обычные и ограниченные связи
Агрегация результатов на основе связей требует регулярных связей.
Регулярные связи включают следующие сочетания режима хранения, в которых обе таблицы находятся из одного источника:
| Таблица на различные стороны | Таблица на стороне 1 |
|---|---|
| Двойной | Двойной |
| Импорт | Импорт или двойной режим |
| Прямой запрос | DirectQuery или Dual |
Единственный случай, когда связь между источниками считается регулярной - это если для обеих таблиц установлен режим 'Импорт'. Отношения "многие ко многим" всегда считаются ограниченными.
Сведения о попаданиях агрегирования источника, которые не зависят от связей, см. Агрегирования на основе столбцов GroupBy.
Примеры агрегирования запросов на основе связей
Следующий запрос участвует в агрегировании, так как столбцы в таблице даты находятся на уровне детализации, который может влиять на агрегацию. В столбце SalesAmount используется агрегация Sum.

Следующий запрос не попадает в агрегат. Несмотря на запрос суммы SalesAmount, запрос выполняет операцию GroupBy для столбца в таблице Product, который не соответствует детализации, необходимой для выполнения агрегирования. Если вы наблюдаете связи в модели, подкатегория продукта может иметь несколько строк Product. Запрос не сможет определить, к какому продукту следует агрегироваться. В этом случае запрос возвращается к DirectQuery и отправляет SQL-запрос в источник данных.
запрос 
Агрегации нужны не только для простых подсчётов, выполняющих сумму. Сложные вычисления также могут извлечь выгоду. Концептуально сложное вычисление разбивается на подзапросы для каждой суммы, min, max и count. Каждый подзапрос оценивается, чтобы определить, может ли он быть учтен в агрегации. Эта логика не является верной во всех случаях вследствие оптимизации плана запросов, но в общем случае она должна быть применима. В следующем примере выполняется агрегирование:

Функция COUNTROWS может выиграть благодаря агрегациям. Следующий запрос задействует агрегирование, поскольку для таблицы Sales определено агрегирование под названием "Подсчет строк таблицы" .

Функция AVERAGE может получать преимущества от агрегаций. Следующий запрос попадает в агрегат, так как СРЕДНЕЕ внутренне свертывается в СУММУ, делённую на КОЛИЧЕСТВО. Так как столбец UnitPrice содержит агрегаты, определенные как для SUM, так и для COUNT, срабатывает агрегирование.

В некоторых случаях функция DISTINCTCOUNT может воспользоваться агрегациями. Следующий запрос попадает в агрегирование, так как в таблице агрегирования имеется запись GroupBy для CustomerKey, которая сохраняет уникальность CustomerKey в таблице агрегирования. Этот метод по-прежнему может повлиять на порог производительности, когда более двух-пяти миллионов различающихся значений могут повлиять на производительность запросов. Однако это может быть полезно в сценариях, когда в таблице подробных сведений есть миллиарды строк, но два до пяти миллионов разных значений в столбце. В этом случае ФУНКЦИЯ DISTINCTCOUNT может выполняться быстрее, чем сканировать таблицу с миллиардами строк, даже если она была кэширована в память.

Функции временного интеллекта в выражениях анализа данных (DAX) учитывают агрегирование. Следующий запрос задействует агрегатную функцию, так как функция DATESYTD создает таблицу значений CalendarDay, а таблица агрегирования имеет уровень детализации, покрывающий столбцы группировки в таблице даты Date. Это пример табличного фильтра для функции CALCULATE, которая может работать с агрегациями.

Агрегирование на основе столбцов GroupBy
Модели больших данных на основе Hadoop имеют разные характеристики, отличные от трехмерных моделей. Чтобы избежать соединения между большими таблицами, модели больших данных часто не используют связи; вместо этого, они денормализуют, перемещая атрибуты измерений в таблицы фактов. Для интерактивного анализа такие модели большого объема данных можно открыть с помощью агрегаций на основе столбцов GroupBy.
В следующей таблице содержится числовой столбец Движение, который необходимо агрегировать. Все остальные столбцы являются атрибутами для группировки данных. Таблица содержит данные Интернета вещей и большое количество строк. Режим хранения — DirectQuery. Запросы к источнику данных, которые агрегируют данные по всей модели, медленные из-за огромного объема.

Чтобы включить интерактивный анализ для этой модели, можно добавить таблицу агрегирования, которая группирует большинство атрибутов, но исключает атрибуты высокой кратности, такие как долгота и широта. Это значительно уменьшает количество строк и имеет достаточный размер, чтобы удобно поместиться в кэшируемой памяти.
таблица 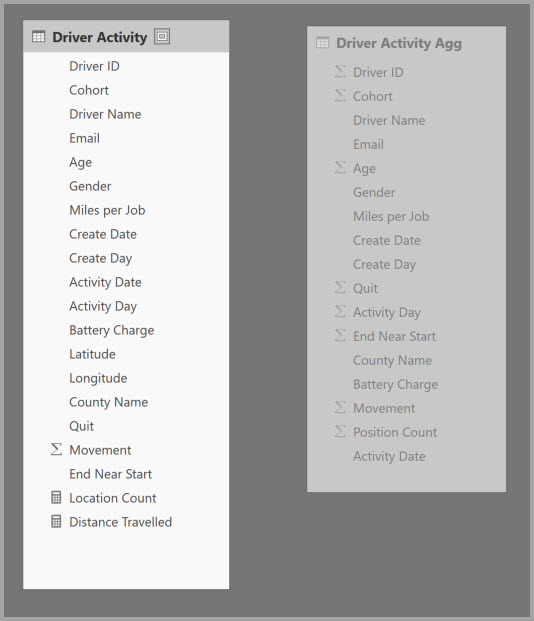
Вы определяете сопоставления агрегирования для таблицы агрегирования активности драйвера в диалоговом окне Управление агрегированием.
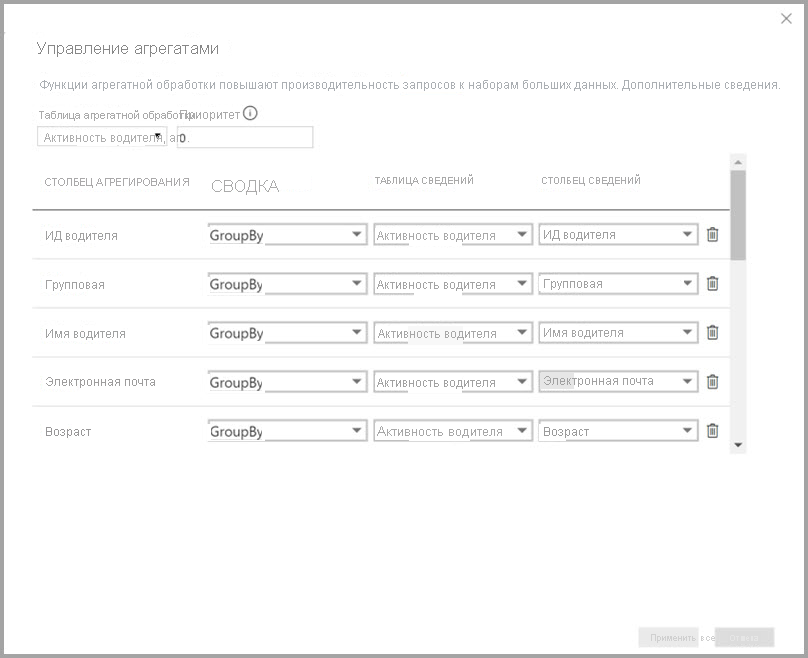
В агрегатах, основанных на столбцах GroupBy, записи GroupBy не являются необязательными. Без них объединения не срабатывают. Это отличается от использования агрегатов на основе связей, в которых записи GroupBy являются необязательными.
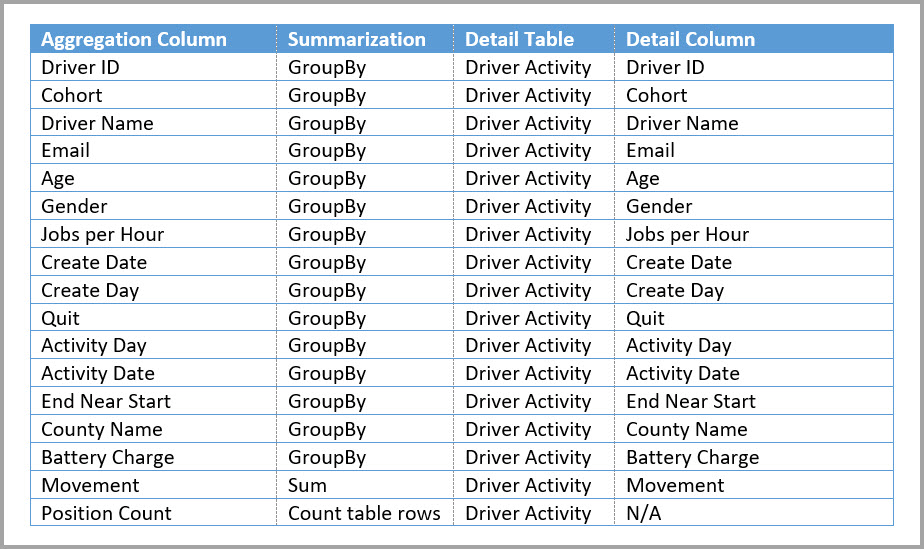
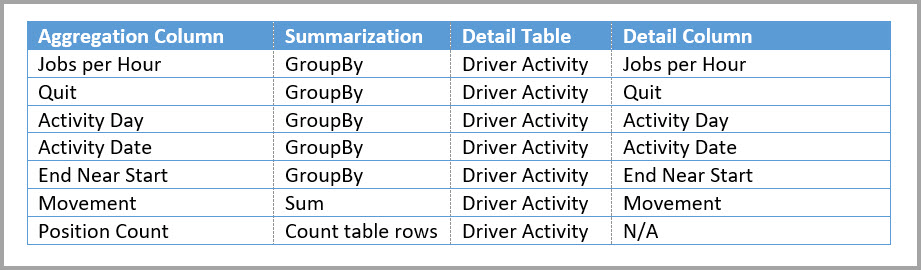
В следующей таблице показаны агрегации для таблицы Driver Activity Agg.
Вы можете задать режим хранения данных для таблицы агрегированной активности драйвера в формате Импорт.
Пример запроса на агрегирование с использованием GroupBy
Следующий запрос обращается к агрегации, поскольку столбец даты активности включён в таблицу агрегации. Функция COUNTROWS использует подсчитанные строки таблицы.

Особенно для моделей, содержащих атрибуты фильтра в фактических таблицах, рекомендуется использовать агрегирования для подсчета строк таблицы . Power BI может отправлять запросы в модель с помощью COUNTROWS в тех случаях, когда он явно не запрашивается пользователем. Например, в диалоговом окне фильтра отображается количество строк для каждого значения.
Объединенные методы агрегирования
Вы можете объединить методы связей и столбцов GroupBy для агрегирования. Агрегаты на основе связей могут требовать разделения денормализованных таблиц измерений на несколько таблиц. Если это является дорогостоящим или непрактичным для определенных таблиц измерений, можно реплицировать необходимые атрибуты в таблице агрегирования для этих измерений и использовать связи для других.
Например, следующая модель реплицирует месяц, квартал, семестри год в таблице Sales Agg. Нет связи между Sales Agg и таблицей Дата, но существуют связи с Клиент и Product Subcategory. Режим хранения Sales Agg — импорт.
В следующей таблице показаны записи, заданные в диалоговом окне Управление агрегатами для таблицы Sales Agg. Записи группировки по, в которых дата является таблицей сведений, необходимы для выполнения агрегаций в запросах, которые группируются по атрибутам даты . Как и в предыдущем примере, записи GroupBy для CustomerKey и ProductSubcategoryKey не влияют на агрегирование, за исключением "DISTINCTCOUNT", ввиду существующих связей.
Примеры объединенных статистических запросов
Следующий запрос задействует агрегацию, так как таблица агрегации охватывает CalendarMonth, а CategoryName доступна через связи "один ко многим". SalesAmount использует агрегирование СУММ.
пример запроса 
Следующий запрос не попадает в агрегат, так как таблица агрегирования не охватывает CalendarDay.

Следующий запрос аналитики времени не попадает в агрегат, так как функция DATEYTD создает таблицу значений CalendarDay, а таблица агрегирования не охватывает CalendarDay.

Приоритет агрегирования
Приоритет агрегирования позволяет учитывать несколько таблиц агрегирования одним вложенным запросом.
В следующем примере показана составная модель с несколькими источниками:
- Таблица DirectQuery driver Activity содержит более триллионов строк данных Интернета вещей, полученных из системы больших данных. Он служит детализацией запросов для просмотра отдельных операций чтения Интернета вещей в управляемых контекстах фильтра.
- Таблица агрегирования активности драйвера — это промежуточная таблица в режиме DirectQuery. Он содержит более миллиарда строк в Azure Synapse Analytics (прежнее название — хранилище данных SQL) и оптимизирован в источнике с помощью индексов columnstore.
- Таблица импорта действий драйвера Agg2 имеет высокую степень детализации, так как атрибуты группы являются небольшими и низкими кратностью. Количество строк может быть не более тысяч, поэтому оно может легко поместиться в кэш в памяти. Эти атрибуты используются важной информационной панелью для руководителей, поэтому запросы, ссылающиеся на них, должны выполняться максимально быстро.
Примечание.
Таблицы агрегирования DirectQuery, использующие другой источник данных из таблицы сведений, поддерживаются только в том случае, если таблица агрегирования выполняется из источника SQL Server, SQL Azure или Azure Synapse Analytics (прежнее название — хранилище данных SQL).
Объем памяти этой модели относительно мал, но он разблокирует огромную модель. Она представляет сбалансированную архитектуру, так как она распределяет нагрузку запросов между компонентами архитектуры, используя их на основе их сильных сторон.
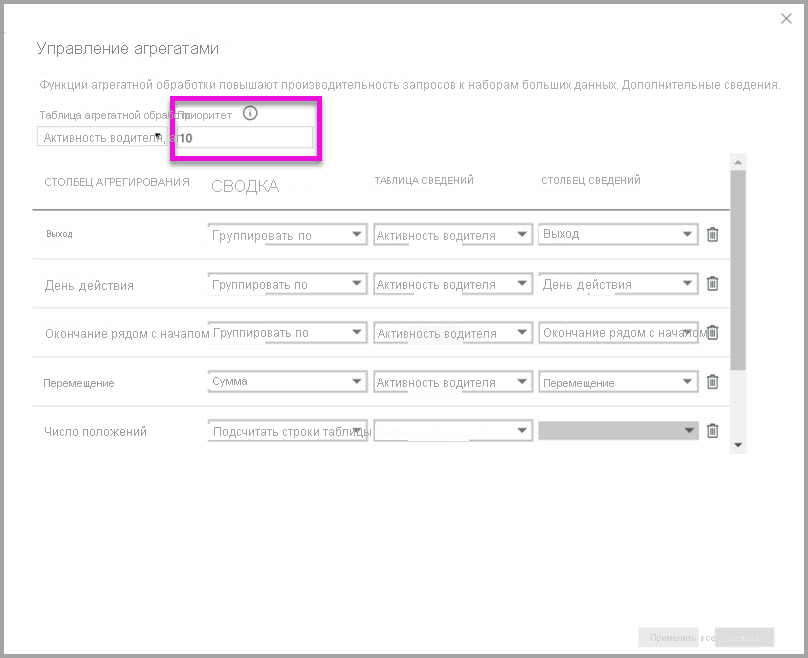
таблицы 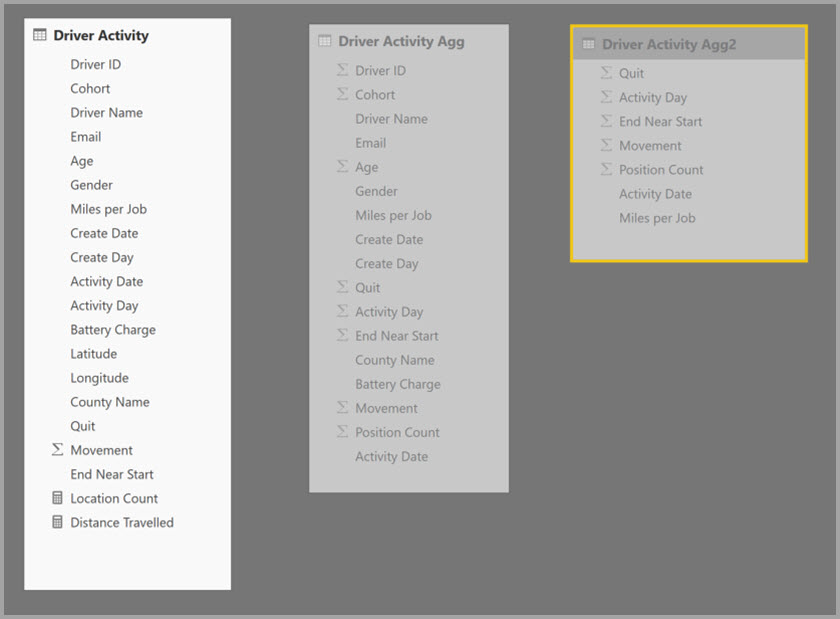
Диалоговое окно управляемых агрегаций для активности драйвера Agg2 задает полю приоритет значение 10, что выше, чем для активности драйвера. Более высокий параметр приоритета означает, что запросы, использующие агрегаты, сначала рассматривают Активность драйвера Agg2. Вложенные запросы, которые не соответствуют детализации, на которую может ответить Деятельность драйвера Agg2, могут рассмотреть использование Деятельность драйвера вместо этого. Запросы подробных сведений, которые не могут быть обработаны ни одной из таблиц агрегирования, могут направляться в Активность драйвера.
Таблица, указанная в столбце таблицы сведений, - это Driver Activity, а не Driver Activity Agg, поскольку агрегирование в цепочке не допускается.
В следующей таблице показаны агрегации для таблицы Активность драйвера Agg2.
Определение того, попадают ли запросы или нет в агрегации
Sql Profiler может определить, возвращаются ли запросы из подсистемы хранилища кэша в памяти или отправляются в источник данных DirectQuery. Вы можете использовать тот же процесс, чтобы определить, используются ли агрегации. Для получения более подробной информации см. Запросы, которые попадают в кэш или промахиваются.
SQL Profiler также предоставляет расширенное событие Query Processing\Aggregate Table Rewrite Query.
В следующем фрагменте JSON показан пример выходных данных события при использовании агрегирования.
- РезультатСопоставления показывает, что вложенный запрос использовал агрегирование.
- dataRequest отображаются столбцы GroupBy и агрегированные столбцы, используемые вложенным запросом.
- сопоставления отображает столбцы в таблице агрегирования, к которым были сопоставлены.

Держите кэши в синхронизации
Агрегаты, которые объединяют режимы DirectQuery, Import и/или Dual storage, могут возвращать разные данные, если кэш в памяти не синхронизирован с исходными данными. Например, выполнение запроса не пытается маскировать проблемы с данными, отфильтровав результаты DirectQuery для сопоставления кэшированных значений. При необходимости существуют установленные методы для обработки таких проблем в источнике. Оптимизации производительности следует использовать только таким образом, чтобы не компрометировать вашу способность соответствовать бизнес-требованиям. Это ваша ответственность за то, чтобы знать потоки данных и разрабатывать их соответствующим образом.
Рекомендации и ограничения
Агрегации не поддерживают динамические параметры запросов M .
Начиная с августа 2022 г. из-за изменений в функциональности Power BI игнорирует таблицы агрегирования режима импорта с включенными источниками данных с поддержкой единого входа из-за потенциальных рисков безопасности. Чтобы обеспечить оптимальную производительность запросов с агрегациями, рекомендуется отключить единый вход для этих источников данных.
Сообщество
Power BI имеет активное сообщество, где MVPs, бизнес-специалисты и одноранговые специалисты делятся опытом в группах обсуждений, видео, блогах и многое другое. При изучении агрегаций обязательно ознакомьтесь со следующими дополнительными ресурсами.