Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Значения кластера автоматически создают группы с аналогичными значениями с помощью нечеткого алгоритма сопоставления, а затем сопоставляют значение каждого столбца с оптимальной группой. Это преобразование полезно при работе с данными с различными вариациями одного и того же значения, и необходимо объединить значения в согласованные группы.
Рассмотрим пример таблицы с столбцом идентификаторов , который содержит набор идентификаторов и столбец Person , содержащий набор различных орфографических и прописных версий имен Miguel, Майка, Уильяма и Билла.
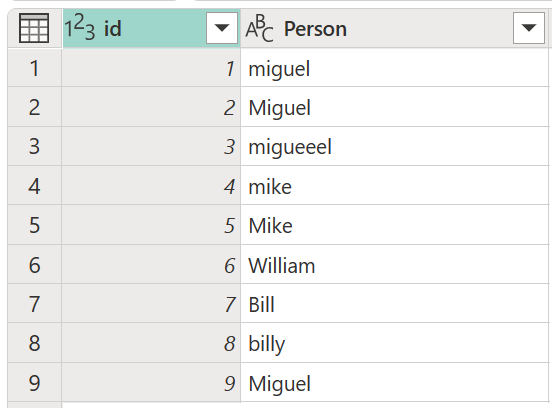
В этом примере результатом, который вы ищете, является таблица с новым столбцом, который показывает правильные группы значений из столбца Person , а не все различные варианты одинаковых слов.
Замечание
Функция значений кластера доступна только для Power Query Online.
Создайте столбец кластера
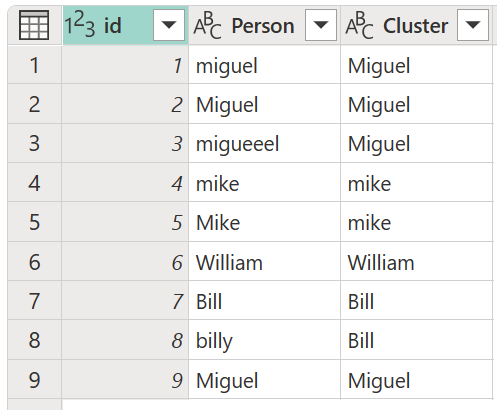
Для кластерных значений сначала выберите столбец Person , перейдите на вкладку "Добавить столбец " на ленте, а затем выберите параметр "Значения кластера ".
![]()
В диалоговом окне "Значения кластера " подтвердите столбец, из которого нужно создать кластеры, и введите новое имя столбца. В этом случае присвойте имя новому кластеру столбцов.
Результат этой операции показан на следующем рисунке.
Замечание
Для каждого кластера значений Power Query выбирает наиболее частый экземпляр из выбранного столбца в качестве канонического экземпляра. Если несколько вхождений встречаются с одинаковой частотой, Power Query выбирает первое.
Использование параметров нечетких кластеров
Следующие параметры доступны для кластеризации значений в новом столбце:
- Порог сходства (необязательно) — этот параметр указывает, насколько похожи два значения должны быть сгруппированы. Минимальный параметр нуля (0) приводит к группировке всех значений. Максимальное значение 1 позволяет сгруппировать только значения, которые совпадают точно. Значение по умолчанию — 0.8.
- Игнорировать случай: если сравниваются текстовые строки, регистр игнорируется. Этот параметр включен по умолчанию.
- Группировка посредством объединения текстовых частей: алгоритм пытается объединить текстовые части (например, объединение "Микро" и "софт" в "Майкрософт") для группирования значений.
- Отображение показателей сходства: показывает оценки сходства между входными значениями и вычисляемых репрезентативных значений после нечеткого кластеризации.
- Таблица преобразования (необязательно) — можно выбрать таблицу преобразования, которая сопоставляет значения (например, сопоставление MSFT с Корпорацией Майкрософт), чтобы сгруппировать их вместе.
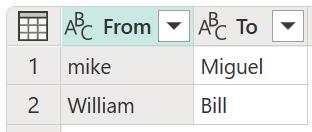
В этом примере новая таблица преобразования с именем "Моя таблица преобразования " используется для демонстрации того, как можно сопоставить значения. Эта таблица преобразования содержит два столбца:
- Из: текстовая строка, которую нужно искать в вашей таблице.
- Чтобы: текстовая строка, используемая для замены текстовой строки в столбце From .
Это важно
Важно, чтобы в таблице преобразования были одинаковые столбцы и имена столбцов, как показано на предыдущем рисунке (они должны быть названы "From" и "To"), в противном случае Power Query не распознает эту таблицу как таблицу преобразования, и преобразование не будет происходить.
С помощью созданного ранее запроса дважды щелкните шаг "Кластеризованные значения ", а затем в диалоговом окне "Значения кластера " разверните параметры нечеткого кластера. В разделе "Нечеткие параметры кластера" включите параметр "Показать оценки сходства ". Для таблицы преобразования (необязательно) выберите запрос, имеющий таблицу преобразования.
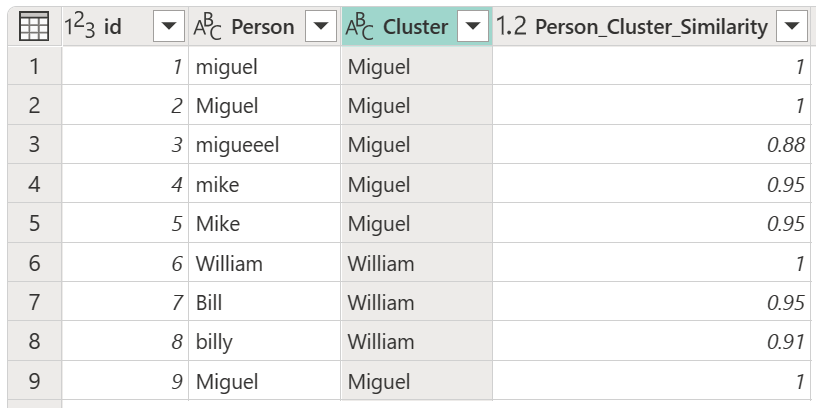
После выбора таблицы преобразования и включения параметра "Показать оценки сходства " нажмите кнопку "ОК". Результат этой операции дает таблицу, содержащую те же столбцы идентификатора и человека , что и исходная таблица, но также содержит два новых столбца с именем Cluster и Person_Cluster_Similarity. Столбец Кластер содержит правильно написанные и записанные с заглавной буквы варианты имени Miguel для версий Miguel и Майк, и имени William для версий Bill, Billy и William. Столбец Person_Cluster_Similarity содержит оценки сходства для каждого из имен.
Принципы таблицы преобразований
Вы можете заметить, что таблица преобразования в предыдущем разделе показывает, что экземпляры Майка изменяются на Мигеля и экземпляры Уильяма изменяются на Билла. Однако в результирующей таблице экземпляры Билла и "билли" вместо этого были изменены на Уильяма. В таблице преобразования, вместо прямого пути от From к To, таблица симметрична во время кластеризации, что означает, что "Майк" эквивалентен "Miguel", и наоборот. Результат эквивалентов, заданных в таблице преобразования, зависит от следующих правил:
- Если имеется большинство идентичных значений, эти значения имеют приоритет над неидентическими значениями.
- Если большинство значений отсутствует, то значение, которое отображается в первую очередь, имеет приоритет.
Например, в исходной таблице, используемой в этой статье, версии имени Мигель (как «miguel», так и «Miguel») в столбце Person составляют большинство экземпляров имени Мигель и Майк. Кроме того, имя Мигель с заглавной буквы составляет основную часть имени Мигель. Таким образом, связывание Miguel и его производных и Майка и его производных в таблице преобразования приводит к тому, что имя Miguel используется в столбце кластера .
Тем не менее, для имен Уильяма, Билла и "билли", не существует большинства значений, так как все три являются уникальными. Так как Уильям появляется первым, Уильям используется в столбце кластера . Если "billy" появился бы в таблице первым, то "billy" использовался бы в столбце кластера. Кроме того, поскольку отсутствует преобладающее значение, используется регистр, применяемый к отдельным именам. То есть, если Уильям первый, Уильям с заглавной буквой "W" используется в качестве значения результата; если "билли" первый, используется "билли" с строчной буквой "b".