Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Такие функции Power Query, как нечеткое слияние, значения кластера и нечеткое группирование , используют те же механизмы для работы с нечетким сопоставлением.
В этой статье рассматривается множество сценариев, демонстрирующих, как воспользоваться вариантами, которые нечеткие совпадения имеют, с целью сделать "нечетким" ясным.
Замечание
Хотя параметр "Значения кластера" доступен только в Power Query Online, механизмы, показанные в этом разделе, также применяются к нечеткому слиянию и нечеткой группировке.
Настройка порога сходства
Лучший сценарий применения алгоритма нечеткого сопоставления заключается в том, что все текстовые строки в столбце содержат только строки, которые необходимо сравнить, и никакие дополнительные компоненты. Например, сравнение Apples с доходностью более высоких показателей сходства, чем по сравнению с 4ppl3sApples.My favorite fruit, by far, is Apples. I simply love them!
Так как слово Apples во второй строке является лишь небольшой частью всей текстовой строки, это сравнение дает более низкую оценку сходства.
Например, следующий набор данных состоит из ответов из опроса, который имел только один вопрос: "Что такое ваш любимый фрукт?"
| Фрукт |
|---|
| Черника |
| Голубые ягоды просто лучшие |
| Клубника |
| Клубника = <3 |
| Apples |
| 'sples |
| 4ppl3s |
| Бананы |
| fav фрукты бананы |
| Банас |
| Мой любимый фрукт, по крайней мере, apples. Я просто люблю их! |
Опрос предоставил одно текстовое поле для ввода значения и не было проверки.
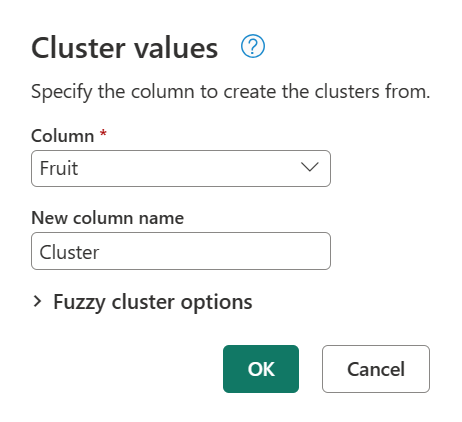
Теперь вы будете выполнять кластеризацию значений. Чтобы сделать это, загрузите предыдущую таблицу фруктов в Power Query, выберите столбец и выберите параметр "Значения кластера " на вкладке "Добавить столбец " на ленте.
![]()
Откроется диалоговое окно "Значения кластера ", где можно указать имя нового столбца. Назовите новый кластер столбцов и нажмите кнопку "ОК".
По умолчанию Power Query использует порог сходства 0,8 (или 80%). Минимальное значение 0.00 приводит ко всем значениям с любым уровнем сходства друг с другом, а максимальное значение 1.00 допускает только точные совпадения. Нечеткое "точное совпадение" может игнорировать различия, такие как регистр, порядок слов и пунктуация. Результат предыдущей операции дает следующую таблицу с новым столбцом кластера .
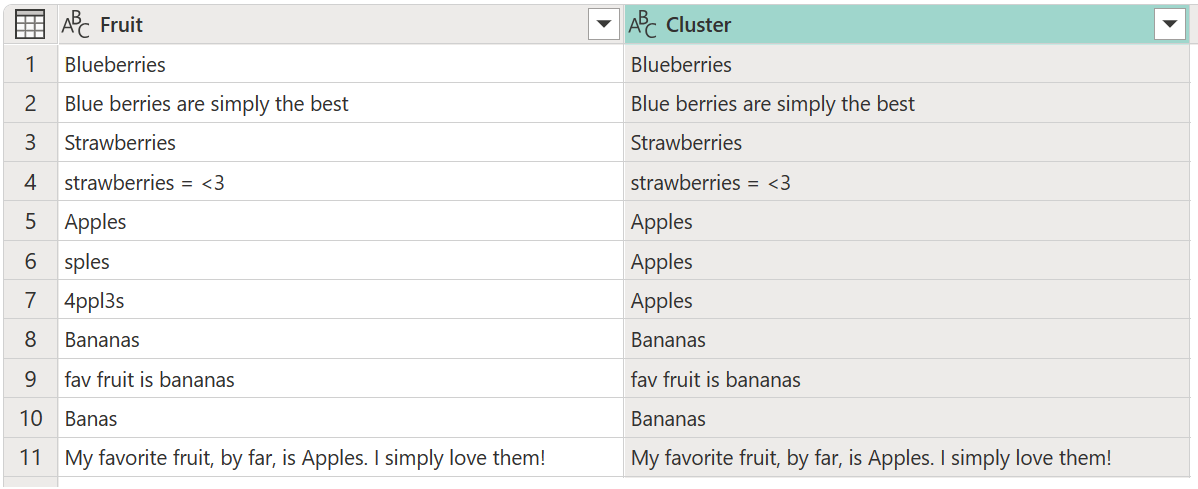
Пока кластеризация выполнена, это не дает ожидаемые результаты для всех строк. Номер строки 2 (2) по-прежнему имеет значение Blue berries are simply the best, но оно должно быть кластеризовано Blueberriesи что-то подобное происходит с текстовыми строками Strawberries = <3, fav fruit is bananasи My favorite fruit, by far, is Apples. I simply love them!.
Чтобы определить причину этого кластеризации, дважды щелкните кластеризованные значения на панели "Примененные шаги ", чтобы вернуть диалоговое окно "Значения кластера ". В этом диалоговом окне разверните параметры нечеткого кластера. Включите параметр "Показать оценки сходства " и нажмите кнопку "ОК".
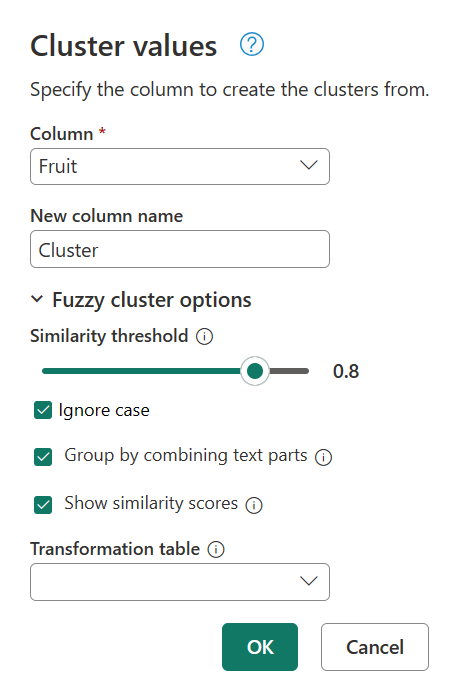
Включение параметра "Показать оценки сходства" создает новый столбец в таблице. В этом столбце показано точное значение сходства между определенным кластером и исходным значением.

При более внимательной проверке Power Query не удалось найти другие значения в пороге сходства для текстовых Blue berries are simply the bestстрок,Strawberries = <3fav fruit is bananas иMy favorite fruit, by far, is Apples. I simply love them!.
Вернитесь в диалоговое окно "Значения кластера " еще раз, дважды щелкнув кластеризованные значения на панели "Примененные шаги ". Измените порог сходства от 0,8 до 0,6, а затем нажмите кнопку "ОК".
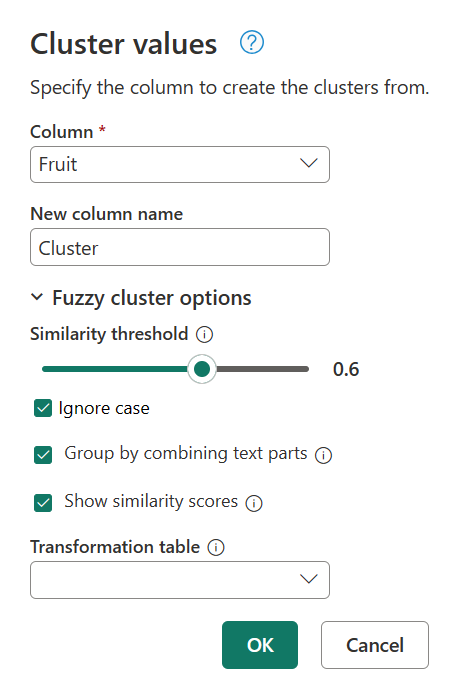
Это изменение приближает вас к результату, который вы ищете, за исключением текстовой строки My favorite fruit, by far, is Apples. I simply love them!. При изменении порогового значения сходства с 0,8 до 0,6 Power Query теперь смог использовать значения с оценкой сходства, начинающейся с 0,6 до 1.

Замечание
Power Query всегда использует значение, ближайшее к порогу, для определения кластеров. Пороговое значение определяет нижнее ограничение оценки сходства, приемлемое для назначения значения кластеру.
Вы можете повторить попытку, изменив оценку сходства с 0,6 на меньшее число, пока не получите результаты, которые вы ищете. В этом случае измените оценку сходства на 0,5. Это изменение дает точный результат, который вы ожидаете с помощью текстовой строки My favorite fruit, by far, is Apples. I simply love them! , назначенной кластеру Apples.

Замечание
В настоящее время только функция значений кластера в Power Query Online предоставляет новый столбец с оценкой сходства.
Специальные рекомендации для таблицы преобразования
Таблица преобразования помогает сопоставлять значения из столбца с новыми значениями перед выполнением нечеткого алгоритма сопоставления.
Некоторые примеры использования таблицы преобразования:
- Таблица преобразования в значениях кластера
- Таблица преобразования в нечетких запросах слияния
- Таблица преобразования в группе по
Это важно
Если используется таблица преобразования, максимальная оценка сходства значений из таблицы преобразования составляет 0,95. Этот преднамеренный штраф 0,05 имеет значение, чтобы отличить исходное значение от такого столбца не равно значениям, с которым оно было по сравнению с момента преобразования.
В сценариях, в которых сначала требуется сопоставить значения, а затем выполнить нечеткое сопоставление без штрафа 0,05, рекомендуется заменить значения из столбца, а затем выполнить нечеткое сопоставление.