API для работы с таблицами и SQL в кластерах Apache Flink® на HDInsight на AKS
Важно!
Сервис Azure HDInsight на AKS был прекращен 31 января 2025 г. Узнайте больше об этом объявлении.
Необходимо перенести рабочие нагрузки в Microsoft Fabric или эквивалентный продукт Azure, чтобы избежать резкого завершения рабочих нагрузок.
Важно!
Эта функция сейчас доступна в предварительной версии. Дополнительные условия использования для предварительных версий Microsoft Azure включают дополнительные юридические термины, применимые к функциям Azure, которые находятся в бета-версии, в предварительной версии или в противном случае еще не выпущены в общую доступность. Сведения об этой конкретной предварительной версии см. в Azure HDInsight в предварительной версии AKS. Для вопросов или предложений функций отправьте запрос на AskHDInsight с подробными сведениями и подписывайтесь на обновления в Azure HDInsight Community.
Apache Flink предоставляет два реляционных API - API таблиц и SQL для единого потока и пакетной обработки. API таблиц — это API запросов, интегрированный с языком, который позволяет интуитивно создавать запросы из реляционных операторов, таких как выборка, фильтрация и связывание. Поддержка SQL Flink основана на Apache Calcite, которая реализует стандарт SQL.
Интерфейсы API таблиц и SQL легко интегрируются друг с другом и API DataStream Flink. Вы можете легко переключаться между всеми API и библиотеками, которые опираются на них.
Как и другие подсистемы SQL, запросы Flink работают в верхней части таблиц. Она отличается от традиционной базы данных, так как Flink не управляет неактивных данных локально; вместо этого запросы работают непрерывно над внешними таблицами.
Конвейеры обработки данных Flink начинаются с исходных таблиц и заканчиваются целевыми таблицами. Исходные таблицы производят строки, обрабатываемые во время выполнения запроса; они являются таблицами, на которые ссылается предложение FROM запроса. Соединители могут быть типа HDInsight Kafka, HDInsight HBase, Azure Event Hubs, баз данных, файловых систем или любой другой системы, коннектор которой присутствует в classpath.
См. эту статью о том, как использовать CLI из Secure Shell на портале Azure. Ниже приведены некоторые краткие примеры начала работы.
Запуск клиента SQL
./bin/sql-client.shПередать файл инициализации SQL для запуска одновременно с SQL-клиентом
./sql-client.sh -i /path/to/init_file.sqlНастройка конфигурации в sql-client
SET execution.runtime-mode = streaming; SET sql-client.execution.result-mode = table; SET sql-client.execution.max-table-result.rows = 10000;
Flink SQL поддерживает следующие инструкции CREATE
- СОЗДАТЬ ТАБЛИЦУ
- СОЗДАТЬ БАЗУ ДАННЫХ
- СОЗДАТЬ КАТАЛОГ
Ниже приведен пример синтаксиса для определения исходной таблицы с помощью соединителя jdbc для подключения к MSSQL с идентификатором, именем в виде столбцов в инструкции CREATE TABLE
CREATE TABLE student_information (
id BIGINT,
name STRING,
address STRING,
grade STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:sqlserver://servername.database.windows.net;database=dbname;encrypt=true;trustServerCertificate=true;create=false;loginTimeout=30',
'table-name' = 'students',
'username' = 'username',
'password' = 'password'
);
CREATE DATABASE (создать базу данных):
CREATE DATABASE students;
СОЗДАТЬ КАТАЛОГ:
CREATE CATALOG myhive WITH ('type'='hive');
Непрерывные запросы можно запускать в верхней части этих таблиц
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Запись в таблицу приемника из исходной таблицы:
INSERT INTO grade_counts
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Инструкции JAR используются для добавления пользовательских jar-файлов в classpath, удаления пользовательских jar-файлов из classpath или отображения добавленных jar-файлов в classpath во время выполнения.
Flink SQL поддерживает следующие инструкции JAR:
- ДОБАВЛЕНИЕ JAR-файла
- ПОКАЗАТЬ JARS
- УДАЛЕНИЕ JAR-ФАЙЛА
Flink SQL> ADD JAR '/path/hello.jar';
[INFO] Execute statement succeed.
Flink SQL> ADD JAR 'hdfs:///udf/common-udf.jar';
[INFO] Execute statement succeed.
Flink SQL> SHOW JARS;
+----------------------------+
| jars |
+----------------------------+
| /path/hello.jar |
| hdfs:///udf/common-udf.jar |
+----------------------------+
Flink SQL> REMOVE JAR '/path/hello.jar';
[INFO] The specified jar is removed from session classloader.
Каталоги предоставляют метаданные, такие как базы данных, таблицы, секции, представления и функции и сведения, необходимые для доступа к данным, хранящимся в базе данных или других внешних системах.
В HDInsight в AKS Flink мы поддерживаем два варианта каталога:
GenericInMemoryCatalog
GenericInMemoryCatalog является реализацией каталога в оперативной памяти. Все объекты доступны только для времени существования сеанса SQL.
HiveCatalog
HiveCatalog служит двумя целями; в качестве постоянного хранилища для чистых метаданных Flink и в качестве интерфейса для чтения и записи существующих метаданных Hive.
Примечание
HDInsight в кластерах AKS поставляется с интегрированным вариантом хранилища метаданных Hive для Apache Flink. Вы можете выбрать хранилище метаданных Hive во время создания кластера
См. эту статью по использованию интерфейса командной строки и началу работы с клиентом Flink SQL из Secure Shell на портале Azure.
Запуск сеанса
sql-client.sh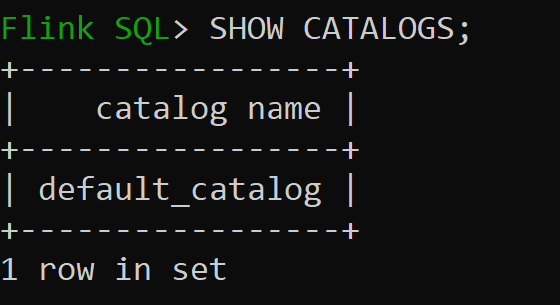
Default_catalog — это каталог по умолчанию в памяти
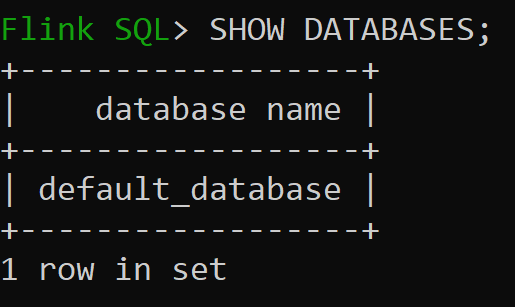
Давайте теперь проверяем базу данных по умолчанию каталога в памяти
Давайте создадим каталог Hive версии 3.1.2 и используйте его
CREATE CATALOG myhive WITH ('type'='hive'); USE CATALOG myhive;Примечание
HDInsight в AKS поддерживает Hive 3.1.2 и Hadoop 3.3.2. Расположение
hive-conf-dirустановлено как/opt/hive-confДавайте создадим базу данных в каталоге Hive и сделаем её используемой по умолчанию для сеанса (если не изменено вручную).
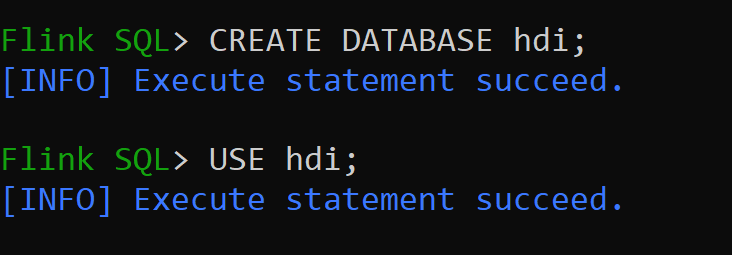
Следуйте инструкциям из по созданию и регистрации баз данных Flink в каталоге
Давайте создадим таблицу Flink с коннектором типа Hive без раздела
CREATE TABLE hive_table(x int, days STRING) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');Вставить данные в hive_table
INSERT INTO hive_table SELECT 2, '10'; INSERT INTO hive_table SELECT 3, '20';Чтение данных из таблицы "hive_table"
Flink SQL> SELECT * FROM hive_table; 2023-07-24 09:46:22,225 INFO org.apache.hadoop.mapred.FileInputFormat[] - Total input files to process : 3 +----+-------------+--------------------------------+ | op | x | days | +----+-------------+--------------------------------+ | +I | 3 | 20 | | +I | 2 | 10 | | +I | 1 | 5 | +----+-------------+--------------------------------+ Received a total of 3 rowsПримечание
Каталог хранилища Hive находится в указанном контейнере учетной записи хранения, выбранной во время создания кластера Apache Flink, можно найти в каталоге hive/warehouse/
Давайте создадим таблицу Flink типа соединителя hive с разделом.
CREATE TABLE partitioned_hive_table(x int, days STRING) PARTITIONED BY (days) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');
Важно!
В Apache Flink существует известное ограничение. Для разбиений выбираются последние 'n' столбцов, независимо от определяемого пользователем столбца разбиения. FLINK-32596 Ключ секции будет неправильным, когда используется диалект Flink для создания таблицы Hive.
- API таблиц Apache Flink & SQL
- Имена проектов Apache, Apache Flink, Flink и связанных с ним проектов с открытым кодом являются товарными знакамиApache Software Foundation (ASF).