Мониторинг состояния Кластеров больших данных с помощью Azure Data Studio
В этой статье показано, как просмотреть состояние кластера больших данных с помощью Azure Data Studio.
Важно!
Поддержка надстройки "Кластеры больших данных" Microsoft SQL Server 2019 будет прекращена. Мы прекратим поддержку Кластеров больших данных SQL Server 2019 28 февраля 2025 г. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на платформе, и программное обеспечение будет продолжать поддерживаться с помощью накопительных обновлений SQL Server до этого времени. Дополнительные сведения см. в записи блога объявлений и в статье о параметрах больших данных на платформе Microsoft SQL Server.
Использование Azure Data Studio
После скачивания последней сборки предварительной оценкиAzure Data Studio вы можете просматривать конечные точки служб и состояние кластера больших данных с помощью панели мониторинга кластера больших данных SQL Server. Некоторые из приведенных ниже функций появились в сборке предварительной оценки Azure Data Studio впервые.
Сначала создайте подключение к кластеру больших данных в Azure Data Studio. Дополнительные сведения см. в статье Подключение к кластеру больших данных SQL Server с помощью Azure Data Studio.
Щелкните правой кнопкой мыши конечную точку кластера больших данных и выберите пункт "Управление".
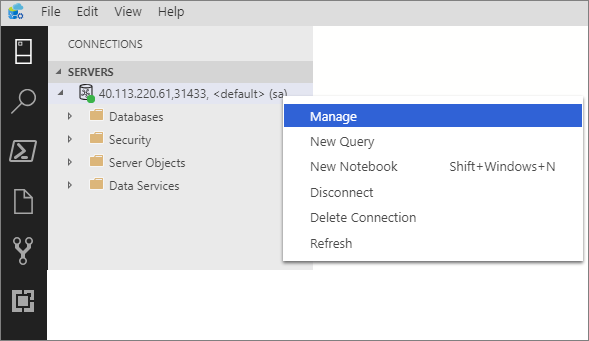
Перейдите на вкладку SQL Server Big Data Cluster (Кластер больших данных SQL Server), чтобы открыть панель мониторинга кластера больших данных.
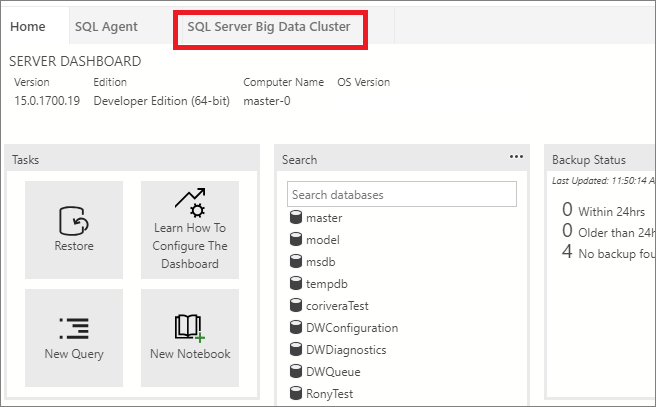
Конечные точки служб
Важно иметь возможность легко обращаться к различным службам в кластере больших данных. Панель мониторинга кластера больших данных предоставляет таблицу конечных точек служб, позволяющую просматривать и копировать конечные точки служб.
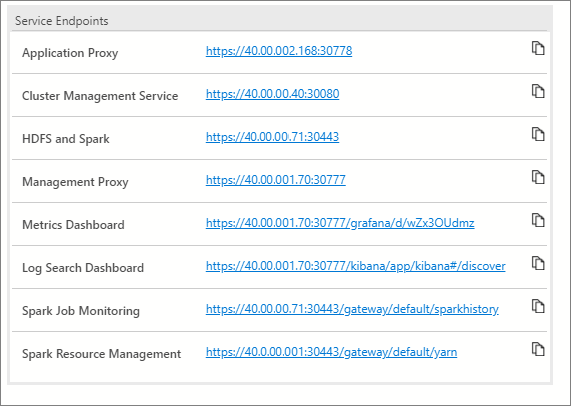
Эти службы выводят список конечных точек, которые можно копировать и вставлять, когда требуется конечная точка для подключения к таким службам. Например, можно выбрать значок копирования справа от конечной точки, а затем вставить его в текстовое окно, запрашивающее эту конечную точку. Конечная точка службы управления кластерами нужна для запуска записной книжки состояния кластера.
Панели мониторинга
Таблица конечных точек служб также предоставляет несколько панелей мониторинга для наблюдения.
- Метрики (Grafana)
- Журналы (Kibana)
- Мониторинг заданий Spark
- Управление ресурсами Spark
Вы можете напрямую выбрать эти ссылки. При доступе к этим панелям мониторинга вам придется пройти проверку подлинности. Для панелей мониторинга метрик и журналов укажите учетные данные администратора контроллера, которые задаются во время развертывания с помощью переменных среды AZDATA_USERNAME и AZDATA_PASSWORD. Панели мониторинга Spark будут использовать учетные данные шлюза (Knox): либо удостоверение AD в кластере, интегрированном с AD, либо пользователя AZDATA_USERNAME и переменную среды AZDATA_PASSWORD, если в кластере используется обычная проверка подлинности.
Начиная с SQL Server 2019 (15.x) CU 5 при развертывании нового кластера с базовой проверкой подлинности всех конечных точек, включая использование AZDATA_USERNAME шлюза и AZDATA_PASSWORD. Конечные точки в кластерах, которые обновлены до накопительного пакета обновления 5, продолжают использовать root в качестве имени пользователя для подключения к конечной точке шлюза. Это изменение не применяется к развертываниям, в которых используется проверка подлинности с помощью Active Directory. Подробные сведения см. в заметках о выпуске в разделе Учетные данные для доступа к службам через конечную точку шлюза.
Записная книжка состояния кластера
Вы также можете просмотреть состояние кластера больших данных, запустив записную книжку состояния кластера. Чтобы запустить записную книжку, выберите задачу "Состояние кластера".
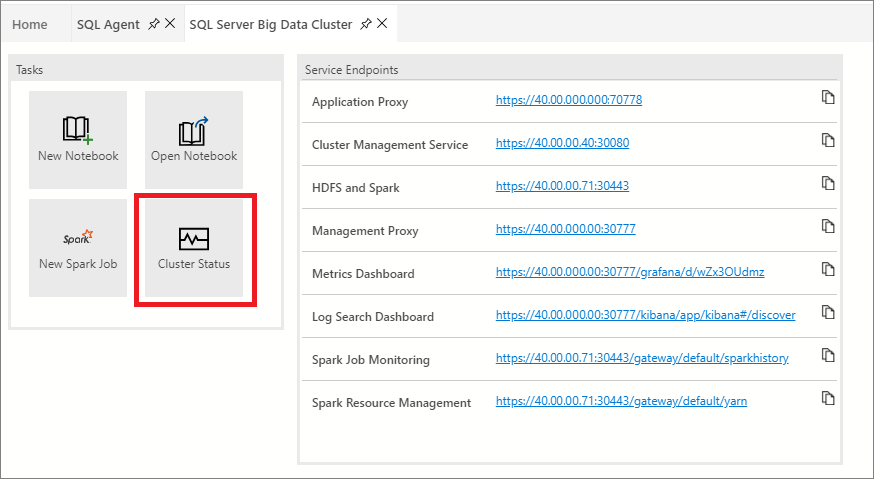
Перед началом работы вам потребуется следующее.
- Имя кластера больших данных
- Имя пользователя контроллера
- Пароль контроллера
- Конечные точки контроллера
Имя кластера больших данных по умолчанию — mssql-cluster, если только оно не было настроено во время развертывания. Конечную точку контроллера можно найти на панели мониторинга кластера больших данных в таблице конечных точек служб. Конечная точка указана как Служба управления кластерами. Если вы не знаете учетные данные, обратитесь к администратору, развернувшему ваш кластер.
Выберите "Запустить ячейки " на верхней панели инструментов.
Следуйте указаниям в запросе на ввод учетных данных. Нажмите клавишу ВВОД после ввода всех учетных данных для имени кластера больших данных, имени пользователя контроллера и пароля контроллера.
Примечание.
Если у вас нет файла конфигурации, настроенного для больших данных, вам будет предложено указать конечную точку контроллера. Введите или вставьте ее, а затем нажмите клавишу ВВОД для продолжения.
Если подключение выполнено успешно, в оставшейся части записной книжки отображаются выходные данные каждого компонента в кластере больших данных. При повторном запуске определенной ячейки кода наведите указатель мыши на ячейку кода и щелкните значок запуска .
Связанный контент
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по