Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Область применения:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Кластеры больших данных Microsoft SQL Server 2019 прекращены. Поддержка кластеров больших данных SQL Server 2019 закончилась с 28 февраля 2025 г. Дополнительные сведения см. в записи блога объявлений и параметрах больших данных на платформе Microsoft SQL Server.
Так как кластеры больших данных SQL Server доступны в Kubernetes в качестве контейнерных приложений, а также используют такие функции, как наборы с отслеживанием состояния и постоянное хранилище, эта инфраструктура имеет встроенные механизмы мониторинга работоспособности, обнаружения сбоев и отработки отказа, которые используются компонентами кластера для поддержания работоспособности служб. Для повышения надежности можно также настроить главный экземпляр SQL Server и (или) узел имен HDFS и общие службы Spark для развертывания с дополнительными репликами в конфигурации высокой доступности. Мониторинг, обнаружение сбоев и автоматическая отработка отказа управляются службой управления кластерами больших данных, а именно центральной службой управления. Эта служба предоставляется без вмешательства пользователя — включая настройку группы доступности, настройки конечных точек зеркалирования баз данных, добавление баз данных в группу доступности и координацию отказоустойчивости и плана по обновлению.
На следующем рисунке показано, как группа доступности развертывается в кластере больших данных SQL Server:
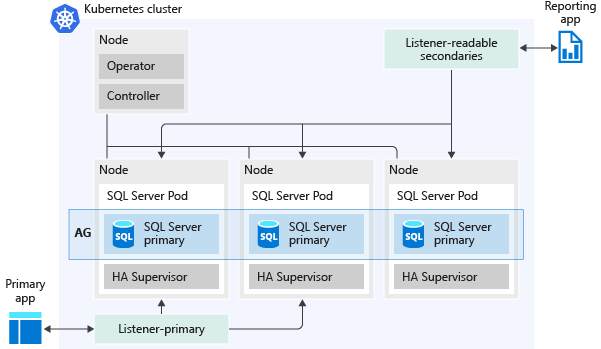
Ниже приведены некоторые возможности, которые предоставляют группы доступности.
Если параметры высокой доступности указаны в файле конфигурации развертывания, создается отдельная группа
containedagдоступности. По умолчаниюcontainedagимеет три реплики, включая основную. Все операции CRUD для группы доступности управляются внутренне, включая создание группы доступности или присоединение реплик к созданной группе доступности. Дополнительные группы доступности нельзя создать в главном экземпляре SQL Server в кластере больших данных.Все базы данных автоматически добавляются в группу доступности, включая все пользовательские и системные базы данных, такие как
masterиmsdb. Эта возможность предоставляет целостное представление для реплик группы доступности. Дополнительные базы данных модели —model_replicatedmasterиmodel_msdb— используются для заполнения реплицированной части системных баз данных. Помимо этих баз данных, при подключении непосредственно к инстанции вы увидите базы данныхcontainedag_masterиcontainedag_msdb. Базы данныхcontainedagпредставляютmasterиmsdbв составе группы доступности.Important
Базы данных, созданные на экземпляре в результате рабочего процесса, например присоединение базы данных, автоматически не добавляются в группу доступности. Администраторы кластеров больших данных SQL Server должны сделать это вручную. Сведения о том, как включить временную конечную точку в базе данных master экземпляра SQL Server, см. в статье "Подключение к экземпляру SQL Server". До выпуска SQL Server 2019 CU2 базы данных, созданные в результате инструкции восстановления, имели то же поведение, а базы данных должны были добавляться вручную в содержащуюся группу доступности.
Базы данных конфигурации PolyBase не включены в группу доступности, так как они включают метаданные уровня экземпляра, относящиеся к каждой реплике.
Внешняя конечная точка автоматически подготавливается для подключения к базам данных в группе доступности. Конечная точка
master-svc-externalвыполняет роль прослушивателя группы доступности.Вторая внешняя конечная точка подготовлена для подключений только для чтения к вторичным репликам для масштабирования рабочих нагрузок чтения.
Deploy
Чтобы развернуть основной сервер SQL Server в группе доступности:
- Включите функцию
hadr - Укажите количество реплик для ГД (минимум 3)
- Настройка сведений о второй внешней конечной точке, созданной для подключений к вторичным репликам только для чтения
Можно использовать либо встроенные профили конфигурации aks-dev-test-ha, либо kubeadm-prod, чтобы начать настройку вашего кластера больших данных. Эти профили включают параметры, необходимые для ресурсов, которые можно настроить для дополнительной высокой доступности. Например, ниже приведен раздел в bdc.json файле конфигурации, который относится к включению групп доступности для главного экземпляра SQL Server.
{
...
"spec": {
"type": "Master",
"replicas": 3,
"endpoints": [
{
"name": "Master",
"serviceType": "LoadBalancer",
"port": 31433
},
{
"name": "MasterSecondary",
"serviceType": "LoadBalancer",
"port": 31436
}
],
"settings": {
"sql": {
"hadr.enabled": "true"
}
}
}
...
}
В следующих шагах показано, как начать работу с aks-dev-test-ha профиля и настроить конфигурацию развертывания кластера больших данных. Для развертывания в kubeadm кластере применяются аналогичные действия, но убедитесь, что вы используете NodePort для serviceType в разделе endpoints.
Клонируйте ваш целевой профиль
azdata bdc config init --source aks-dev-test-ha --target custom-aks-haПри необходимости внесите изменения в пользовательский профиль.
Запуск развертывания кластера с помощью профиля конфигурации кластера, созданного выше
azdata bdc create --config-profile custom-aks-ha --accept-eula yes
Подключение к базам данных SQL Server в группе доступности
В зависимости от типа рабочей нагрузки, которую требуется запустить в главном экземпляре SQL Server, можно подключиться либо к основному для рабочих нагрузок чтения и записи, либо к базам данных в вторичных репликах для типа рабочих нагрузок только для чтения. Ниже приведена структура для каждого типа подключения:
Подключение к базам данных в первичной реплике
Для подключений к первичной реплике используйте sql-server-master конечную точку. Эта конечная точка также является слушателем для группы доступности. При использовании этой конечной точки все подключения находятся в контексте баз данных в группе доступности. Например, подключение по умолчанию с помощью этой конечной точки приведет к подключению к master базе данных в группе доступности, а не к базе данных экземпляра master SQL Server. Выполните следующую команду, чтобы найти конечную точку:
azdata bdc endpoint list -e sql-server-master -o table
Description Endpoint Name Protocol
------------------------------------ ------------------- ----------------- ----------
SQL Server Master Instance Front-End 11.11.111.111,11111 sql-server-master tds
Note
События переключения на резервный ресурс могут возникать во время выполнения распределенного запроса, который обращается к данным из удаленных источников данных, таких как HDFS или данный пул. Приложения лучше проектировать с логикой повторных попыток установления соединения на случай отключений, вызванных отработкой отказа.
Подключение к базам данных на вторичных репликах
Для подключений только для чтения к базам данных во вторичных репликах используйте конечную точку sql-server-master-readonly . Эта конечная точка действует как балансировщик нагрузки между всеми вторичными репликами. При использовании этой конечной точки все подключения находятся в контексте баз данных в группе доступности. Например, подключение по умолчанию с помощью этой конечной точки приведет к подключению к master базе данных в группе доступности, а не к базе данных экземпляра master SQL Server.
azdata bdc endpoint list -e sql-server-master-readonly -o table
Description Endpoint Name Protocol
--------------------------------------------- ------------------ -------------------------- ----------
SQL Server Master Readable Secondary Replicas 11.11.111.11,11111 sql-server-master-readonly tds
Подключение к экземпляру SQL Server
Для некоторых операций, таких как настройка конфигураций уровня сервера или добавление базы данных в группу доступности, необходимо подключиться к экземпляру SQL Server. До SQL Server 2019 CU2 операции, такие как sp_configureRESTORE DATABASE или любые группы доступности DDL, потребуют этого типа подключения. По умолчанию кластер больших данных не включает конечную точку, которая обеспечивает подключение экземпляра, и эту конечную точку необходимо предоставить вручную.
Important
Конечная точка, предоставленная для подключений экземпляра SQL Server, поддерживает только проверку подлинности SQL, даже в кластерах, где включен Active Directory. По умолчанию во время развертывания кластера больших данных sa вход отключен, и создается новый sysadmin логин, основанный на значениях, указанных во время развертывания для переменных среды AZDATA_USERNAME и AZDATA_PASSWORD.
Important
DDL изолированной группы доступности является исключительно самоуправляемой в BDC. Попытка любого внешнего пользователя удалить автономную доступность или конечную точку зеркального отображения базы данных не поддерживается и может привести к неустранимому состоянию Big Data Clusters.
Ниже приведен пример, показывающий, как предоставить эту конечную точку, а затем добавить базу данных, созданную с помощью рабочего процесса восстановления, в группу доступности. Аналогичные инструкции по настройке подключения к главному экземпляру SQL Server применяются, когда вы хотите изменить конфигурации сервера с помощью sp_configure.
Note
Начиная с SQL Server 2019 CU2 базы данных, созданные в результате рабочего процесса восстановления, автоматически добавляются в содержащуюся группу доступности.
Определите pod, на котором размещена первичная реплика, подключившись к конечной точке
sql-server-masterи выполните следующую команду.SELECT @@SERVERNAMEСоздайте новый сервис Kubernetes для предоставления внешнего конечного узла.
Для кластера выполните команду
kubeadm, указанную ниже. ЗаменитеpodNameна имя сервера, возвращенного на предыдущем шаге;serviceNameна предпочтительное имя для создаваемой службы Kubernetes; иnamespaceName* на имя кластера больших данных.kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortДля запуска кластера aks выполните ту же команду, за исключением того, что будет создана
LoadBalancerслужба. For example:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancerНиже приведен пример выполнения этой команды в aks, где модуль pod, на котором размещен основной объект:
master-0kubectl -n mssql-cluster expose pod master-0 --port=1533 --name=master-sql-0 --type=LoadBalancerПолучите IP-адрес созданной службы Kubernetes:
kubectl get services -n <namespaceName>
Important
Рекомендуется очистить, удалив службу Kubernetes, созданную выше, выполнив следующую команду:
kubectl delete svc master-sql-0 -n mssql-cluster
Добавьте базу данных в группу доступности.
Чтобы база данных была добавлена в группу доступности, она должна выполняться в полной модели восстановления, а резервная копия журнала должна быть выполнена. Используйте IP-адрес из службы Kubernetes, созданной выше, и подключитесь к экземпляру SQL Server, а затем выполните инструкции T-SQL, как показано ниже.
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>В следующем примере добавляется база данных с именем
sales, которая была восстановлена на экземпляре.ALTER DATABASE sales SET RECOVERY FULL; BACKUP DATABASE sales TO DISK='/var/opt/mssql/data/sales.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE sales
Known limitations
Это известные проблемы и ограничения с ограниченными группами доступности для основного сервера SQL Server в кластере больших данных.
- При развертывании кластера больших данных необходимо создать конфигурацию высокого уровня доступности. Вы не можете включить конфигурацию высокого уровня доступности с группами доступности после развертывания. В настоящее время включена только настройка для реплик с синхронной фиксацией.
Warning
Обновление режима синхронизации до асинхронной фиксации для любой из реплик в фиксации кворума приведет к недопустимой конфигурации для обеспечения высокой доступности. Работа в этой конфигурации связана с риском потери данных, поскольку в случае сбоя, затрагивающего основную реплику, не происходит автоматического переключения на резервную копию, и пользователь должен принять риск потери данных при ручном переключении.
- Чтобы успешно восстановить базу данных с включенным TDE из резервной копии, созданной на другом сервере, необходимо убедиться, что необходимые сертификаты восстанавливаются как на главном экземпляре SQL Server, так и на мастер-сервере группы доступности. См. здесь пример резервного копирования и восстановления сертификатов.
- Некоторые операции, такие как установка параметров конфигурации сервера, требуют подключения к базе данных экземпляра SQL Server
sp_configure, а не к группе доступностиmaster. Не удается использовать соответствующую первичную конечную точку. Следуйте инструкциям, чтобы открыть конечную точку и подключиться к экземпляру SQL Server, и выполнитеsp_configure. Вы можете использовать только проверку подлинности SQL при ручной настройке конечной точки для подключения к базе данных экземпляраmasterSQL Server. - Хотя содержащаяся база данных msdb включена в группу доступности, а задания агента SQL реплицируются по всему расписанию, задания выполняются только по расписанию в первичной реплике.
- Функция репликации не поддерживается для содержащихся групп доступности. Экземпляры SQL Server, находящиеся в составе группы доступности в заключении (contained AG), не могут функционировать как распространитель или издатель ни на уровне экземпляра, ни на уровне самой группы доступности в заключении.
- Добавление групп файлов при создании базы данных не поддерживается. В качестве обходного решения можно сначала создать базу данных, а затем выдать инструкцию ALTER DATABASE, чтобы добавить все группы файлов.
- До SQL Server 2019 CU2 базы данных, созданные в результате рабочих процессов, отличных
CREATE DATABASEот рабочих процессов, которыеRESTORE DATABASECREATE DATABASE FROM SNAPSHOTне добавляются в группу доступности автоматически. Подключитесь к узлу и добавьте базу данных в группу доступности вручную. - Компонент Service Broker и Database Mail в настоящее время не поддерживаются в кластерах больших данных, развернутых с высоким уровнем доступности.
Next steps
- Дополнительные сведения об использовании файлов конфигурации в развертываниях кластера больших данных см. в статье о развертывании SQL Server Кластеры больших данных в Kubernetes.
- Дополнительные сведения о функциях групп доступности для SQL Server см. в разделе "Общие сведения о группах доступности AlwaysOn" (SQL Server).