Развертывание кластера больших данных SQL Server с высокой доступностью
Область применения: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Внимание
Поддержка надстройки "Кластеры больших данных" Microsoft SQL Server 2019 будет прекращена. Мы прекратим поддержку Кластеров больших данных SQL Server 2019 28 февраля 2025 г. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на платформе, и программное обеспечение будет продолжать поддерживаться с помощью накопительных обновлений SQL Server до этого времени. Дополнительные сведения см. в записи блога объявлений и в статье о параметрах больших данных на платформе Microsoft SQL Server.
Так как кластеры больших данных SQL Server существуют в Kubernetes как контейнерные приложения и используют такие функции, как наборы с отслеживанием состояния и постоянное хранилище, в этой инфраструктуре имеются механизмы встроенного мониторинга работоспособности, обнаружения сбоев и отработки отказа, которые компоненты кластера используют для поддержания работоспособности служб. Чтобы повысить надежность, можно также настроить главный экземпляр SQL Server и (или) узел имен HDFS и общие службы Spark для развертывания с дополнительными репликами в конфигурации высокой доступности. Мониторинг, обнаружение сбоев и автоматическая отработка отказа управляются службой управления кластером больших данных, которая называется службой контроля. Эта служба обеспечивает все действия без участия пользователя: от настройки группы доступности и конечных точек зеркального отображения баз данных до добавления баз данных в группу доступности или координации отработки отказа и обновления.
На следующем рисунке показано, как группа доступности развертывается в кластере больших данных SQL Server.
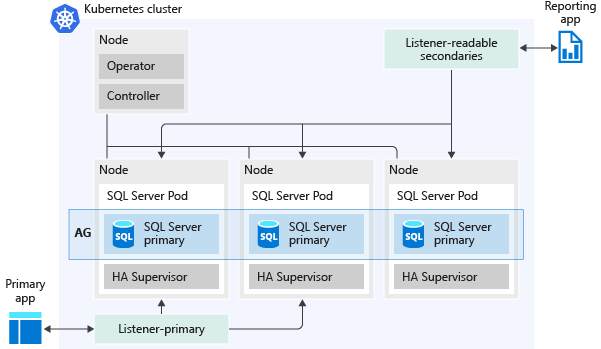
Ниже приведены некоторые возможности, которые обеспечивают группы доступности.
Если параметры высокой доступности заданы в файле конфигурации развертывания, создается отдельная группа доступности с именем
containedag. По умолчанию группа доступностиcontainedagимеет три реплики, включая первичную. Все операции CRUD для группы доступности управляются внутренним образом, в том числе создание группы доступности или присоединение реплик к созданной группе доступности. В главном экземпляре SQL Server в кластере больших данных невозможно создать дополнительные группы доступности.Все базы данных автоматически добавляются в группу доступности, в том числе все пользовательские и системные базы данных, такие как
masterиmsdb. Эта возможность обеспечивает представление единой системы во всех репликах группы доступности. Дополнительные шаблоны баз данных —model_replicatedmasterиmodel_msdb— используются для заполнения реплицированной части системных баз данных. Если вы подключаетесь непосредственно к экземпляру, то помимо этих баз данных вы увидите базы данныхcontainedag_masterиcontainedag_msdb. Базы данныхcontainedagпредставляютmasterиmsdbв группе доступности.Внимание
Базы данных, созданные на экземпляре в результате рабочего процесса, например присоединения базы данных, не добавляются автоматически в группу доступности. Администраторы Кластеров больших данных SQL Server должны сделать это вручную. Сведения о том, как включить временную конечную точку в базу данных master экземпляра SQL Server, см. в разделе Подключение к экземпляру SQL Server. До выпуска накопительного обновления 2 (CU2) для SQL Server 2019 базы данных, созданные в результате выполнения инструкции RESTORE, точно так же требовали добавления в автономную группу доступности вручную.
Базы данных конфигурации PolyBase не включаются в группу доступности, так как в них имеются метаданные уровня экземпляра для каждой реплики.
Внешняя конечная точка автоматически подготавливается для подключения к базам данных в группе доступности. Эта конечная точка
master-svc-externalвыполняет роль прослушивателя группы доступности.Вторая внешняя конечная точка подготавливается для подключений только для чтения к вторичным репликам в целях горизонтального увеличения масштаба рабочих нагрузок чтения.
Развернуть
Для развертывания главного экземпляра SQL Server в группе доступности необходимо выполнить следующие действия.
- Включить функцию
hadr. - Указать число реплик для группы доступности (минимальное значение — 3).
- Настроить сведения о второй внешней конечной точке, созданной для подключений только для чтения к вторичным репликам.
Чтобы начать настройку кластера больших данных, можно использовать встроенные профили конфигурации aks-dev-test-ha или kubeadm-prod. Эти профили включают необходимые для ресурсов параметры, которые можно дополнительно настроить для высокого уровня доступности. Например, ниже приведен раздел файла конфигурации bdc.json, относящийся к включению групп доступности для главного экземпляра SQL Server.
{
...
"spec": {
"type": "Master",
"replicas": 3,
"endpoints": [
{
"name": "Master",
"serviceType": "LoadBalancer",
"port": 31433
},
{
"name": "MasterSecondary",
"serviceType": "LoadBalancer",
"port": 31436
}
],
"settings": {
"sql": {
"hadr.enabled": "true"
}
}
}
...
}
Ниже приведен пример последовательных действий по настройке конфигурации развертывания кластера больших данных, начиная с профиля aks-dev-test-ha. Для развертывания в кластере kubeadm выполняются аналогичные действия, но необходимо использовать NodePort для serviceType в разделе endpoints.
Клонируйте целевой профиль.
azdata bdc config init --source aks-dev-test-ha --target custom-aks-haПри необходимости внесите нужные изменения в пользовательский профиль.
Начните развертывание кластера с использованием созданного ранее профиля конфигурации.
azdata bdc create --config-profile custom-aks-ha --accept-eula yes
Подключитесь к базам данных SQL Server в группе доступности.
В зависимости от типа рабочей нагрузки, которую требуется выполнять в главном экземпляре SQL Server, можно подключаться к базам данных в первичной реплике (для рабочих нагрузок чтения и записи) или к базам данных во вторичных репликах (для рабочих нагрузок только чтения). Далее приводятся общие сведения по каждому типу подключения.
Подключение к базам данных в первичной реплике
Для подключений к первичной реплике используйте конечную точку sql-server-master. Эта конечная точка также является прослушивателем для группы доступности. При использовании этой конечной точки все подключения находятся в контексте баз данных в группе доступности. Например, при подключении по умолчанию с использованием этой конечной точки установится подключение к базе данных master в группе доступности, а не к базе данных master экземпляра SQL Server. Чтобы найти эту конечную точку, выполните следующую команду:
azdata bdc endpoint list -e sql-server-master -o table
Description Endpoint Name Protocol
------------------------------------ ------------------- ----------------- ----------
SQL Server Master Instance Front-End 11.11.111.111,11111 sql-server-master tds
Примечание.
Во время выполнения распределенного запроса с доступом к данным из удаленных источников, таких как HDFS или пул данных, могут происходить события отработки отказа. Рекомендуется разрабатывать приложения с логикой повторного подключения в случае отключения, вызванного отработкой отказа.
Подключение к базам данных во вторичных репликах
Для подключений только для чтения к базам данных во вторичных репликах используйте конечную точку sql-server-master-readonly. Эта конечная точка действует как подсистема балансировки нагрузки по всем вторичным репликам. При использовании этой конечной точки все подключения находятся в контексте баз данных в группе доступности. Например, при подключении по умолчанию с использованием этой конечной точки установится подключение к базе данных master в группе доступности, а не к базе данных master экземпляра SQL Server.
azdata bdc endpoint list -e sql-server-master-readonly -o table
Description Endpoint Name Protocol
--------------------------------------------- ------------------ -------------------------- ----------
SQL Server Master Readable Secondary Replicas 11.11.111.11,11111 sql-server-master-readonly tds
Подключение к экземпляру SQL Server
Для выполнения некоторых операций, таких как установка конфигураций на уровне сервера или добавление базы данных в группу доступности вручную, необходимо подключаться к экземпляру SQL Server. До выпуска кумулятивного обновления 2 (CU2) для SQL Server 2019 данный тип подключения требовался для таких операций, как sp_configure, RESTORE DATABASE и любых операций DDL в группах доступности. По умолчанию кластер больших данных не включает конечную точку, которая разрешает подключение к экземпляру, так что эту конечную точку вы должны предоставить вручную.
Внимание
Конечная точка, предоставленная только для подключений к экземпляру SQL Server, поддерживает проверку подлинности SQL даже в тех кластерах, где включена проверка подлинности Active Directory. По умолчанию во время развертывания кластера больших данных имя для входа sa отключено, а новое имя для входа sysadmin подготавливается на основе значений, предоставленных для переменных среды AZDATA_USERNAME и AZDATA_PASSWORD во время развертывания.
Внимание
Управление операциями DDL в автономных группах доступности в BDC осуществляется исключительно самостоятельно. Попытки (внешнего пользователя) удалить автономную группу доступности или конечную точку зеркального отображения базы данных не поддерживаются и могут привести к неустранимому состоянию BDC.
Ниже приведен пример действий для предоставления такой конечной точки и последующего добавления базы данных, созданной с помощью рабочего процесса восстановления, в группу доступности. Используйте те же инструкции по настройке подключения к главному экземпляру SQL Server, если требуется изменить конфигурации сервера с помощью sp_configure.
Примечание.
Начиная с SQL Server 2019 с кумулятивным обновлением 2 (CU2) базы данных, созданные в результате процесса восстановления, автоматически добавляются в автономную группу доступности.
Определите pod, в котором размещена первичная реплика. Для этого подключитесь к конечной точке
sql-server-masterи выполните следующую команду:SELECT @@SERVERNAMEПредоставьте внешнюю конечную точку путем создания новой службы Kubernetes.
Для кластера
kubeadmвыполните приведенную ниже команду. ЗаменитеpodNameименем сервера, возвращенного на предыдущем шаге,serviceName— предпочтительным именем для созданной службы Kubernetes, аnamespaceName* — именем кластера больших данных.kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortДля запуска кластера AKS выполните ту же команду, но укажите тип создаваемой службы
LoadBalancer. Например:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancerНиже приведен пример выполнения этой команды для AKS, когда первичная реплика размещается в pod
master-0.kubectl -n mssql-cluster expose pod master-0 --port=1533 --name=master-sql-0 --type=LoadBalancerПолучите IP-адрес созданной службы Kubernetes:
kubectl get services -n <namespaceName>
Внимание
Рекомендуется выполнить очистку, удалив созданную выше службу Kubernetes с помощью следующей команды:
kubectl delete svc master-sql-0 -n mssql-cluster
Добавьте базу данных в группу доступности.
Чтобы база данных была добавлена в группу доступности, она должна выполняться в полной модели восстановления, а резервная копия журнала должна быть выполнена. Используйте IP-адрес из службы Kubernetes, созданной выше, и подключитесь к экземпляру SQL Server, а затем выполните инструкции T-SQL, как показано ниже.
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>В следующем примере добавляется база данных с именем
sales, которая была восстановлена в экземпляре.ALTER DATABASE sales SET RECOVERY FULL; BACKUP DATABASE sales TO DISK='/var/opt/mssql/data/sales.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE sales
Известные ограничения
Ниже перечислены известные проблемы и ограничения, связанные с группами доступности для автономной базы данных master экземпляра SQL Server в кластере больших данных:
- Конфигурация высокой доступности должна быть создана во время развертывания кластера больших данных. Нельзя включить конфигурацию высокой доступности с группами доступности после развертывания. Сейчас включена конфигурация только для синхронных реплик фиксации.
Предупреждение
Обновление режима синхронизации до асинхронной фиксации для любой реплики в фиксации кворума приведет к недопустимой конфигурации для обеспечения высокой доступности. Выполнение с использованием этой конфигурации может привести к потере данных, так как в случае событий сбоя, влияющих на первичную реплику, автоматическая отработка отказа не срабатывает, и пользователь должен учитывать возможность потери данных при отработке отказа вручную.
- Чтобы успешно восстановить базу данных с включенной TDE из резервной копии, созданной на другом сервере, убедитесь, что необходимые сертификаты восстановлены как на главном экземпляре SQL Server, так и в главной автономной базе данных группы доступности. Пример резервного копирования и восстановления сертификатов см. здесь.
- Для выполнения некоторых операций, таких как установка серверных конфигураций с помощью команды
sp_configure, требуется подключение к базе данныхmasterэкземпляра SQL Server, а не к базе данныхmasterгруппы доступности. Нельзя использовать соответствующую основную конечную точку. Выполните эти инструкции, чтобы предоставить конечную точку, подключиться к экземпляру SQL Server и выполнитьsp_configure. При ручном предоставлении конечной точки для подключения к базе данныхmasterэкземпляра SQL Server можно использовать только проверку подлинности SQL. - Хотя автономная база данных msdb включена в группу доступности, а задания Агента SQL реплицируются в этой группе, задания в первичной реплике выполняются по расписанию.
- Функция репликации не поддерживается для автономных групп доступности. Экземпляры SQL Server, включенные в автономную группу доступности, не могут выполнять роль распространителя или издателя на уровне экземпляра или автономной группы доступности.
- Добавление групп файлов при создании базы данных не поддерживается. В качестве обходного решения можно сначала создать базу данных, а затем выполнить инструкцию ALTER DATABASE, чтобы добавить файловые группы.
- До выпуска кумулятивного обновления 2 (CU2) для SQL Server 2019 базы данных, созданные в результате выполнения рабочих процессов, отличных от
CREATE DATABASEиRESTORE DATABASE(например,CREATE DATABASE FROM SNAPSHOT), не добавлялись в группу доступности автоматически. Подключитесь к экземпляру и вручную добавьте базу данных в группу доступности. - В настоящее время Service Broker и Database Mail не поддерживаются в кластерах больших данных, развернутых с высоким уровнем доступности.
Следующие шаги
- Дополнительные сведения об использовании файлов конфигурации в развертываниях кластера больших данных см. в статье о развертывании SQL Server Кластеры больших данных в Kubernetes.
- Дополнительные сведения о функциях групп доступности для SQL Server см. в статье Обзор групп доступности Always On (SQL Server).
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по