Развертывание кластера больших данных SQL Server с помощью записной книжки Azure Data Studio
Область применения:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Важно!
Поддержка надстройки "Кластеры больших данных" Microsoft SQL Server 2019 будет прекращена. Мы прекратим поддержку Кластеров больших данных SQL Server 2019 28 февраля 2025 г. Все существующие пользователи SQL Server 2019 с Software Assurance будут полностью поддерживаться на платформе, а программное обеспечение будет по-прежнему поддерживаться с помощью SQL Server накопительных обновлений до этого времени. Дополнительные сведения см. в записи блога объявлений и в статье о параметрах больших данных на платформе Microsoft SQL Server.
SQL Server предоставляет для Azure Data Studio расширение, которое содержит записные книжки для развертывания. Записная книжка для развертывания содержит документацию и код, которые можно использовать в Azure Data Studio для создания кластеров больших данных SQL Server.
Записные книжки, которые изначально были реализованы как проект с открытым кодом, теперь интегрированы в Azure Data Studio. Вы можете использовать разметку Markdown для текста в текстовых ячейках и одно из доступных ядер для написания кода в ячейках кода.
Вы можете развернуть Кластеры больших данных SQL Server с помощью записных книжек.
Предварительные требования
Для запуска записной книжки требуются следующие компоненты:
Наряду с перечисленным выше для развертывания кластера больших данных требуется следующее:
Запуск записной книжки
Запустите Azure Data Studio.
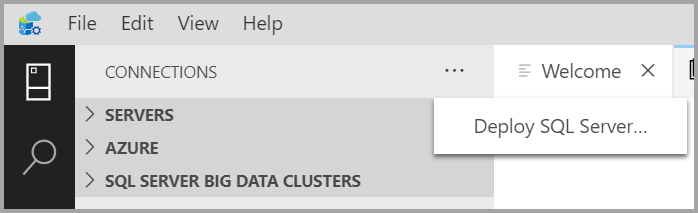
На вкладке Подключения нажмите на многоточие ( ... ) и выберите параметр Развернуть SQL Server... .
В параметрах развертывания выберите Кластер больших данных SQL Server.
В разделеПараметрыцелевого объекта развертывания выберите новый кластер Azure Kubernetes или существующий кластер службы Azure Kubernetes.
Подтвердите соглашение о конфиденциальности и условия лицензии.
Это диалоговое окно также проверяет, существуют ли на узле средства, необходимые для выбранного типа развертывания SQL. Кнопка Выбрать активируется только после того, как проверка инструментов будет выполнена успешно.
Нажмите кнопку Выбрать. Это действие запускает процесс развертывания.
Настройка шаблона конфигурации развертывания
Чтобы настроить параметры профиля развертывания, выполните приведенные ниже инструкции.
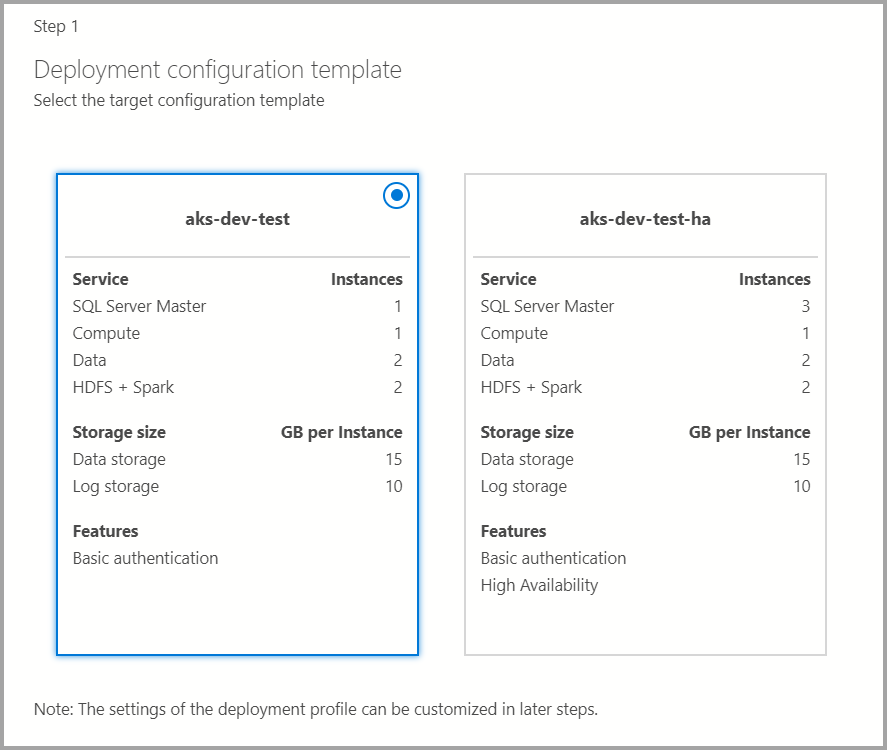
Целевой шаблон конфигурации
Выберите целевой шаблон конфигурации из доступных шаблонов. Доступность профилей зависит от типа целевого объекта развертывания, выбранного в предыдущем диалоговом окне.
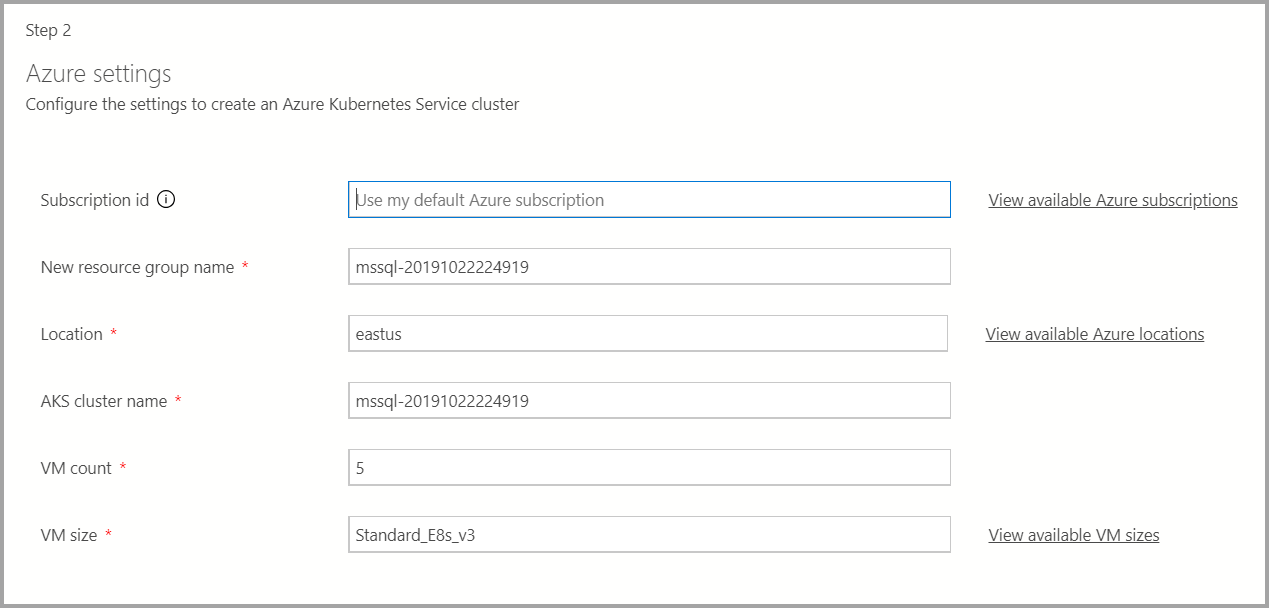
Параметры Azure
Если целевым объектом развертывания является новый экземпляр Службы Azure Kubernetes (AKS), для создания кластера AKS потребуются дополнительные данные, включая идентификатор подписки Azure, группу ресурсов, имя кластера AKS, число виртуальных машин, размер и пр.
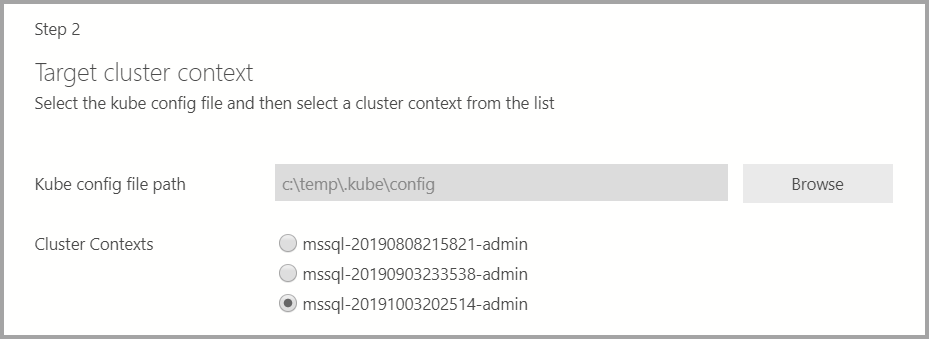
Если целевым объектом развертывания является существующий кластер Kubernetes, мастер запрашивает путь к файлу конфигурации KUBE, чтобы импортировать параметры кластера Kubernetes. Убедитесь, что выбран тот контекст кластера, в котором можно развернуть кластер больших данных SQL Server 2019.
Параметры кластера, Docker и Active Directory
Укажите имя кластера, имя пользователя и пароль администратора для кластера больших данных. Та же учетная запись используется для контроллера и SQL Server.
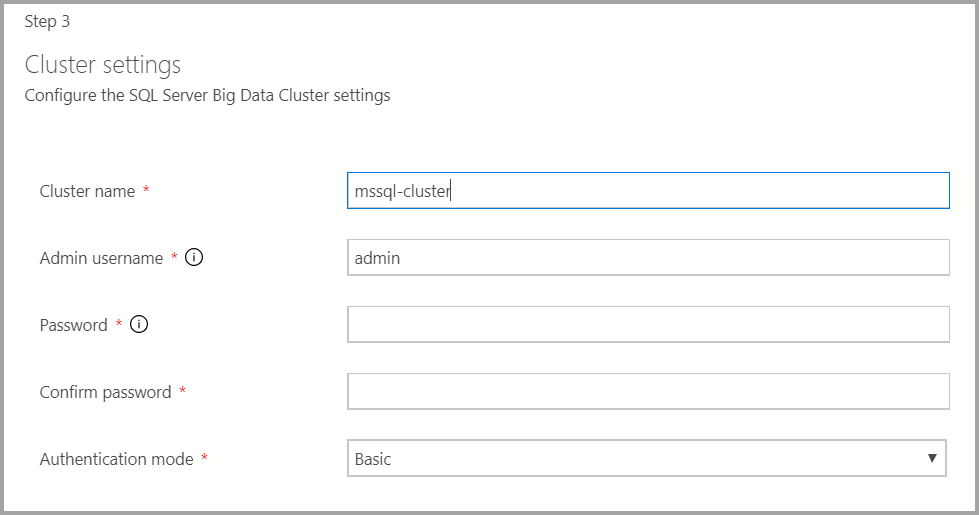
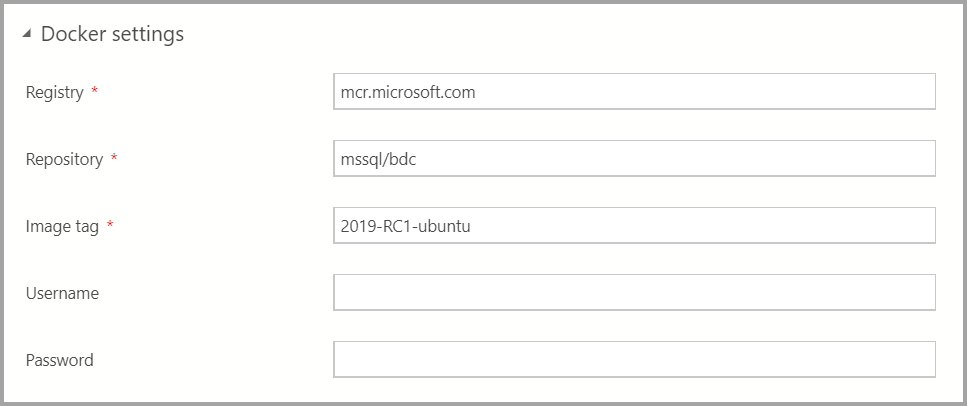
Введите нужные параметры Docker.
Важно!
Убедитесь, что в поле тега указан последний образ: 2019-CU13-ubuntu-20.04
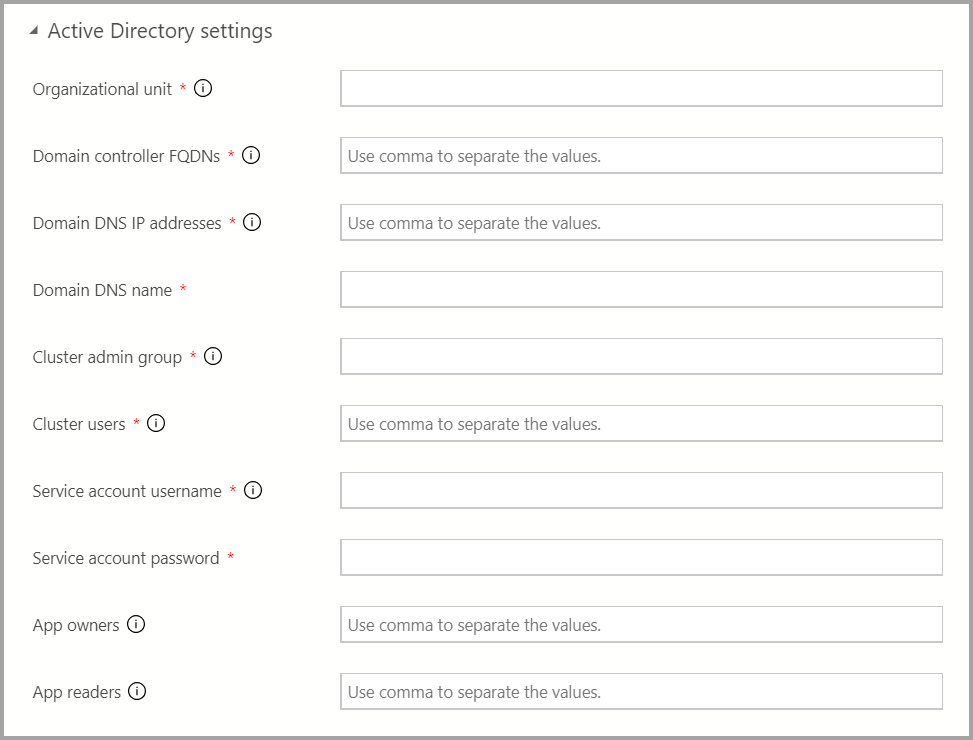
Если доступна проверка подлинности AD, укажите параметры AD.
Параметры службы
На этом экране отображаются входные данные для различных параметров, таких как Масштабирование, Конечные точки, Хранилище и Дополнительные параметры хранилища. Укажите соответствующие значения и щелкните Далее.
Настройки масштабирования
Введите количество экземпляров каждого компонента в кластере больших данных.
Экземпляр Spark можно добавить вместе с HDFS. Он добавляется в пул носителей или используется отдельно в пуле Spark.
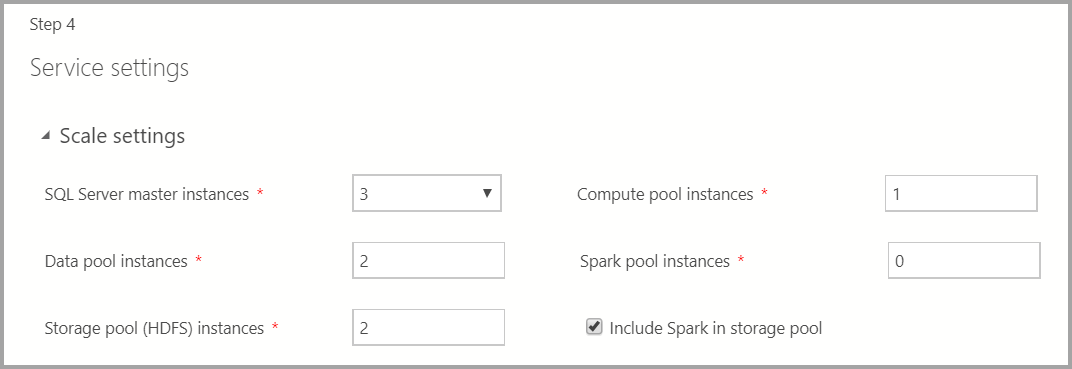
Дополнительные сведения о каждом из этих компонентов см. в разделе о главном экземпляре, пуле данных, пуле носителей или пуле вычислений.
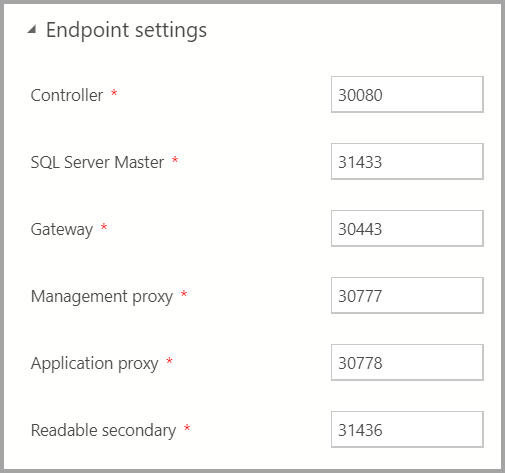
Параметры конечных точек
Конечные точки по умолчанию задаются автоматически. Однако при необходимости их можно изменить.
Параметры хранилища
Параметры хранилища включают класс хранения и размер утверждения для данных и журналов. Данные параметры можно применять к хранилищу, данным и главному пулу SQL Server.

Дополнительные параметры хранилища
Дополнительные параметры хранилища можно добавить в разделе Дополнительные параметры хранилища
Пул носителей (HDFS)
Пул данных
SQL Server Master

Сводка
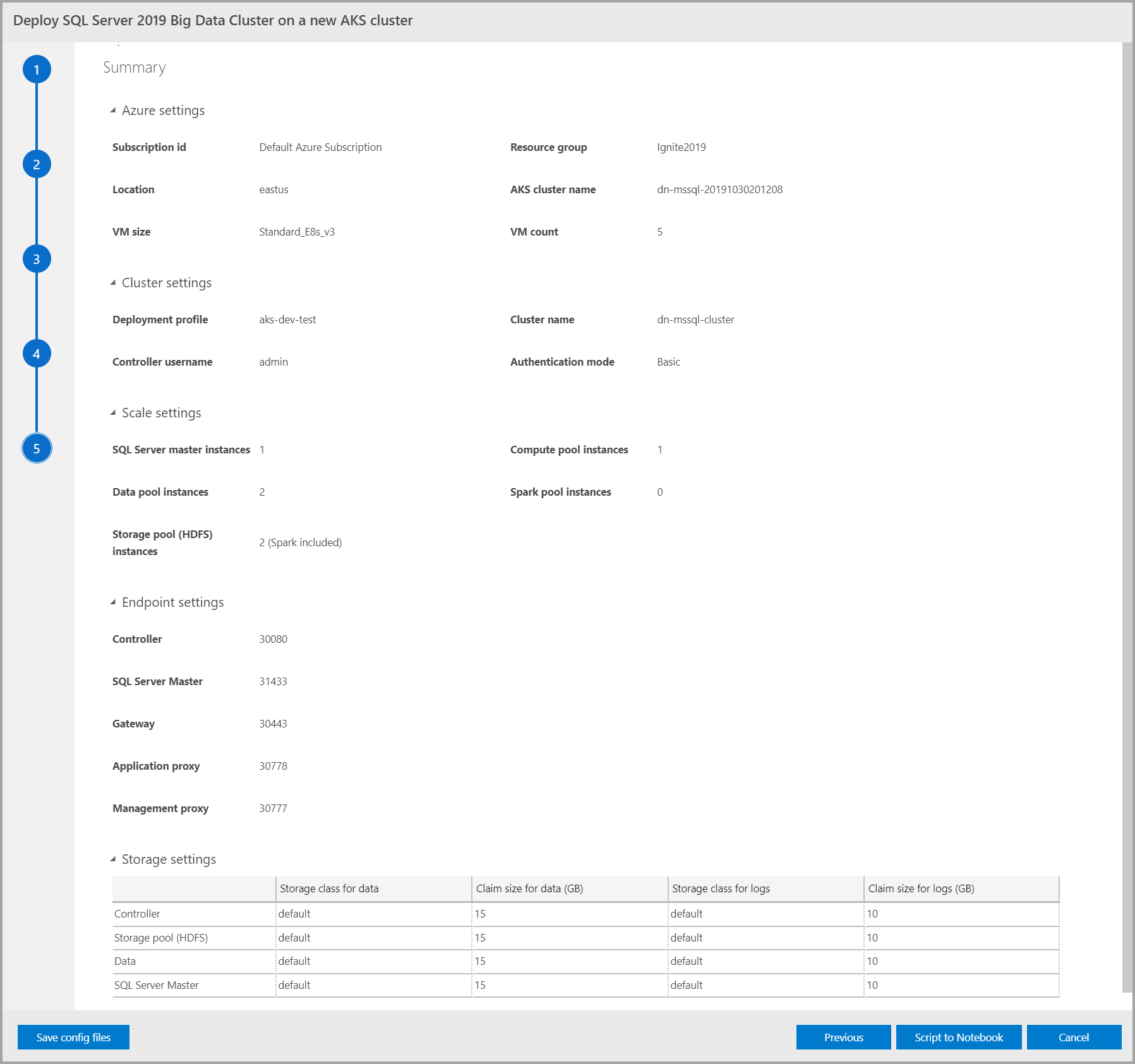
На этом экране перечисляются все входные данные, предоставленные для развертывания кластера больших данных. Файлы конфигурации можно скачать с помощью кнопки Сохранить файлы конфигурации. Выберите Скрипт для Notebook, чтобы сохранить скрипт с конфигурацией развертывания в записной книжке. Открыв записную книжку, выберите Выполнить ячейки, чтобы начать развертывание кластера больших данных в выбранном целевом объекте.
Дальнейшие действия
Дополнительные сведения о развертывании см. в статье Руководство. Развертывание Кластеров больших данных SQL Server.
Обратная связь
Ожидается в ближайшее время: в течение 2024 года мы постепенно откажемся от GitHub Issues как механизма обратной связи для контента и заменим его новой системой обратной связи. Дополнительные сведения см. в разделе https://aka.ms/ContentUserFeedback.
Отправить и просмотреть отзыв по