Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Применимо к:![]() SQL Server
SQL Server![]() База данных
База данных![]() SQL AzureУправляемый экземпляр
SQL AzureУправляемый экземпляр![]() SQL AzureБаза данных SQL в Microsoft Fabric
SQL AzureБаза данных SQL в Microsoft Fabric
Планирование задач операционной системы
Потоки — это наименьшие единицы обработки, выполняемые операционной системой, и позволяют логике приложения разделиться на несколько параллельных путей выполнения. Потоки полезны, когда сложные приложения имеют много задач, которые могут выполняться одновременно.
Когда операционная система выполняет экземпляр приложения, она создает модуль, называемый процессом, для управления экземпляром. Процесс имеет поток выполнения. Это ряд программных команд, выполненных кодом приложения. Например, если простое приложение содержит один набор инструкций, которые можно выполнить последовательно, этот набор инструкций обрабатывается как одна задача и существует только один путь выполнения (или поток) приложения. Более сложные приложения могут иметь несколько задач, которые могут выполняться одновременно, а не последовательно. Для этого приложение может запустить для каждой задачи отдельные процессы, которые являются ресурсоемкими, или запустить отдельные потоки, которые являются относительно менее ресурсоемкими. Кроме этого, каждый поток можно запланировать для выполнения независимо от других потоков, связанных с процессом.
Потоки позволяют сложным приложениям более эффективно использовать ЦП, даже на компьютерах с одним ЦП. С одним процессором только один поток может выполняться одновременно. Если один поток выполняет долго выполняющуюся операцию, которая не использует ЦП, например чтение или запись диска, другой поток может выполняться до завершения первой операции. Возможность выполнять потоки, в то время как другие потоки ожидают завершения операции, позволяет приложению увеличить использование ЦП. Это особенно касается многопользовательских приложений, интенсивно использующих операции дискового ввода-вывода, например сервера базы данных. Компьютеры с несколькими процессорами могут одновременно выполнять по одному потоку на каждый процессор. Например, если компьютер имеет восемь ЦП, он может выполнять одновременно восемь потоков.
Планирование задач SQL Server
В области SQL Server запрос является логическим представлением запроса или пакета. Запрос также представляет операции, необходимые системным потокам, таким как контрольная точка или модуль записи журнала. Запросы существуют в различных состояниях в течение всего времени существования и могут накапливать ожидания, когда ресурсы, необходимые для выполнения запроса, недоступны, например блокировки или защёлки. Дополнительные сведения о состояниях запросов см. в статье sys.dm_exec_requests (Transact-SQL).
Задачи
Задача представляет единицу работы, которую необходимо завершить для выполнения запроса. Одному запросу можно назначить одну или несколько задач.
- Параллельные запросы имеют несколько активных задач, выполняемых одновременно, а не последовательно, с одной родительской задачей (или координирующей задачей) и несколькими дочерними задачами. План выполнения для параллельного запроса может иметь последовательные ветви — области плана с операторами, которые не выполняются параллельно. Родительская задача отвечает и за выполнение этих последовательных операторов.
- Последовательные запросы имеют только одну активную задачу в любой момент времени во время выполнения. Задачи находятся в различных состояниях в течение их жизненного цикла. Дополнительные сведения о состояниях задач см. в статье sys.dm_os_tasks (Transact-SQL). Задачи в приостановленном состоянии ожидают необходимых ресурсов для выполнения задачи. Дополнительные сведения об ожидающих задачах см. в разделе sys.dm_os_waiting_tasks.
Работники
Поток выполнения SQL Server, также называемый рабочим потоком или потоком, является логическим представлением потока операционной системы. При выполнении последовательных запросов СУБД SQL Server создает рабочий процесс для выполнения активной задачи (1:1). При выполнении параллельных запросов в строчном режиме ядро СУБД SQL Server назначает поток для координации дочерних потоков, ответственных за выполнение задач, назначенных им (также 1:1), называемый основным потоком (или координирующим потоком). Родительский поток имеет связанную с ним родительскую задачу. Родительский поток — это точка входа запроса, и она существует даже до того, как ядро начало анализировать запрос. Основные обязанности родительского потока:
- Координирование параллельного сканирования.
- Запуск параллельных дочерних работников.
- Сбор строк из параллельных потоков и их отправка клиенту.
- Выполнение локальных и глобальных операций агрегирования.
Примечание.
Если план запроса содержит последовательные и параллельные ветви, то одна из параллельных задач будет отвечать за выполнение последовательной ветви.
Количество рабочих потоков, порожденных для каждой задачи, зависит от следующих факторов:
Имеет ли запрос право на параллелизм, что определяется оптимизатором запросов.
Какова фактическая степень параллелизма (DOP) в системе на основе текущей нагрузки. Она может отличаться от предполагаемой степени параллелизма, оценка которой выполняется на основе конфигурации сервера для максимальной степени параллелизма (MAXDOP). Например, конфигурация сервера для MAXDOP может составлять 8, но доступное значение DOP в среде выполнения может составлять только 2, что влияет на производительность запросов. Нагрузка на память и нехватка работников — это два условия, которые уменьшают доступный DOP во время выполнения.
Примечание.
Ограничение параметра max degree of parallelism (MAXDOP) задается для каждой задачи, а не для каждого запроса. Это означает, что при выполнении параллельных запросов один запрос может порождать несколько задач вплоть до ограничения MAXDOP и каждая задача будет использовать одну рабочую роль. Дополнительные сведения о MAXDOP см. в статье Настройка параметра конфигурации сервера "максимальная степень параллелизма".
Планировщики
Планировщик, также известный как планировщик SOS, управляет рабочими потоками, требующими времени обработки для выполнения работы от имени задач. Каждый планировщик сопоставляется с отдельным процессором (ЦП). Время, в течение которого рабочая роль может оставаться активной в планировщике, называется квантом времени операционной системы (не более 4 мс). По истечении кванта времени рабочий поток передает время другим рабочим потокам, которым требуется доступ к ресурсам центрального процессора, и изменяет свое состояние. Это сотрудничество между работниками для максимизации доступа к ресурсам ЦП называется кооперативное планирование, также известное как планирование в режиме без вытеснения. В свою очередь, изменение состояния работника распространяется на задачу, связанную с этим работником, и на запрос, связанный с этой задачей. Для получения дополнительной информации о состояниях потоков рабочих см. sys.dm_os_workers (Transact-SQL). Дополнительные сведения о планировщиках см. в sys.dm_os_schedulers.
Таким образом, запрос может порождать одну или несколько задач для выполнения единиц работы. Каждая задача назначается рабочему потоку, который отвечает за выполнение этой задачи. Каждый рабочий поток должен быть запланирован (помещен в планировщик) для активного выполнения задачи.
Рассмотрим следующий сценарий:
- Рабочая задача 1 — это долгосрочная задача, например, запрос на чтение с упреждающим чтением данных из таблиц на дисках. Работник 1 обнаруживает, что необходимые страницы данных уже находятся в буферном пуле, поэтому ему не нужно отказываться от обработки для ожидания операций ввода-вывода и он может использовать весь выделенный квант времени до приостановки.
- Рабочий 2 выполняет более кратковременные задачи на уровне долей миллисекунд и поэтому должен освободить ресурс до исчерпания полного кванта времени.
В этом сценарии и до SQL Server 2014 (12.x) допускается, что Работник 1 может фактически монополизировать планировщик, имея больше квантового времени.
Начиная с SQL Server 2016 (13.x), совместное планирование включает планирование Large Deficit First (LDF). Планирование LDF позволяет отслеживать модели использования квантов, при этом планировщик не используется монопольно ни одним рабочим потоком. В том же сценарии потоку 2 разрешено использовать повторяющиеся кванты времени до того, как потоку 1 будет разрешено больше квантов, таким образом предотвращая монополизацию планировщика потоком 1 в неблагоприятной последовательности.
Расписание параллельных задач
Представьте, что SQL Server настроен с помощью MaxDOP 8, а сопоставление ЦП настроено для 24 ЦП (планировщиков) на узлах NUMA 0 и 1. Планировщики с 0 по 11 относятся к узлу NUMA 0, планировщики с 12 по 23 относятся к узлу NUMA 1. Приложение отправляет следующий запрос (запрос) в ядро СУБД:
SELECT h.SalesOrderID,
h.OrderDate,
h.DueDate,
h.ShipDate
FROM Sales.SalesOrderHeaderBulk AS h
INNER JOIN Sales.SalesOrderDetailBulk AS d
ON h.SalesOrderID = d.SalesOrderID
WHERE (h.OrderDate >= '2014-3-28 00:00:00');
Совет
Этот пример запроса можно выполнить с помощью примера базы данных AdventureWorks2016_EXT. Таблицы Sales.SalesOrderHeader и Sales.SalesOrderDetail увеличены в 50 раз и переименованы в Sales.SalesOrderHeaderBulk и Sales.SalesOrderDetailBulk.
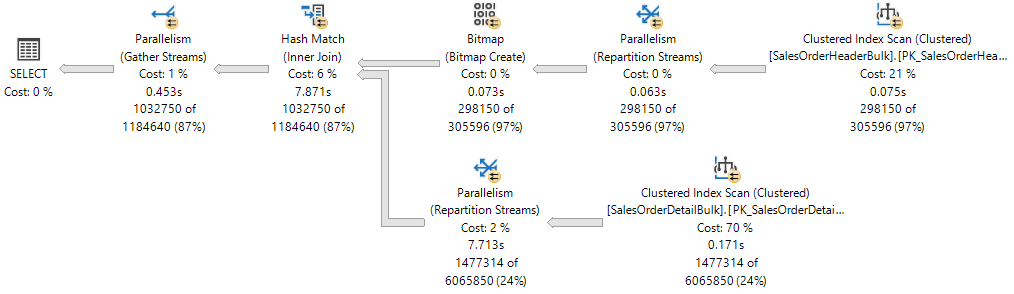
План выполнения показывает хэш-соединение между двумя таблицами и каждый из операторов, выполняемый параллельно, что указывается желтым кругом с двумя стрелками. Каждый оператор параллелизма представляет собой отдельную ветвь в плане. Поэтому в следующем плане выполнения существует три ветви.
Примечание.
Если представить план выполнения как дерево, то ветвь — это область плана, которая группирует один или несколько операторов между операторами параллелизма, также называемыми итераторами обмена. Дополнительные сведения об операторах плана см. в справочнике логических и физических операторов Showplan.
Хотя в этом плане выполнения есть три ветви, в любой момент выполнения в этом плане могут одновременно выполняться только две ветви.
- Ветвь, где используется сканирование кластеризованного индекса на
Sales.SalesOrderHeaderBulk(для входных данных построения соединения), выполняется отдельно. - Ветвь, в которой сканирование кластеризованного индекса используется в
Sales.SalesOrderDetailBulk(во входных данных пробы соединения), выполняется параллельно с ветвью, в которой был создан объект Bitmap и сейчас выполняется оператор Hash Match.
Showplan XML показывает, что в узле NUMA 0 было зарезервировано и использовано 16 рабочих потоков:
<ThreadStat Branches="2" UsedThreads="16">
<ThreadReservation NodeId="0" ReservedThreads="16" />
</ThreadStat>
Резервирование потоков гарантирует, что ядро СУБД имеет достаточно рабочих потоков для выполнения всех задач, необходимых для запроса. Потоки могут быть зарезервированы по нескольким узлам NUMA или только на одном. Резервирование потока происходит в момент запуска программы, до начала выполнения, и зависит от нагрузки планировщика. Число зарезервированных рабочих потоков является универсальным производным от формулы concurrent branches * runtime DOP и исключает родительский рабочий поток. Количество рабочих потоков в каждой ветви ограничено значением MaxDOP. В этом примере имеется два параллельных ветвя, поэтому MaxDOP имеет значение 8.2 * 8 = 16
Для справки просмотрите динамический план выполнения из динамической статистики запросов, где одна ветвь завершила выполнение и две ветви выполняются параллельно.
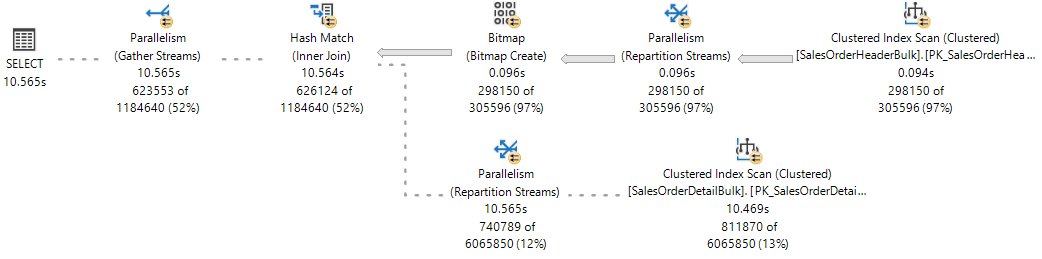
SQL Server ядро базы данных назначает рабочий поток для выполнения активной задачи (1:1), которая может наблюдаться во время выполнения запроса, путем запроса к sys.dm_os_tasks DMV, как показано в следующем примере:
SELECT parent_task_address, task_address,
task_state, scheduler_id, worker_address
FROM sys.dm_os_tasks
WHERE session_id = <insert_session_id>
ORDER BY parent_task_address, scheduler_id;
Совет
Столбец parent_task_address всегда имеет значение NULL для родительской задачи.
Совет
На очень загруженном ядре СУБД SQL Server можно увидеть число активных заданий, которое превышает ограничение, заданное зарезервированными потоками. Эти задачи могут относиться к ветви, которая больше не используется и находится в промежуточном состоянии, ожидая очистки.
Вот набор результатов. Обратите внимание, что существуют 17 активных задач для ветвей, которые в настоящее время выполняются: 16 дочерних задач, соответствующих зарезервированным потокам, плюс родительская задача или координирующая задача.
| адрес_родительской_задачи | адрес_задания | состояние_задачи | scheduler_id | адрес_работника |
|---|---|---|---|---|
| Отсутствует | 0x000001EF4758ACA8 |
ПРИОСТАНОВЛЕН | 3 | 0x000001EFE6CB6160 |
| 0x000001EF4758ACA8 | 0x000001EFE43F3468 | ПРИОСТАНОВЛЕН | 0 | 0x000001EF6DB70160 |
| 0x000001EF4758ACA8 | 0x000001EEB243A4E8 | ПРИОСТАНОВЛЕН | 0 | 0x000001EF6DB7A160 |
| 0x000001EF4758ACA8 | 0x000001EC86251468 | ПРИОСТАНОВЛЕН | 5 | 0x000001EEC05E8160 |
| 0x000001EF4758ACA8 | 0x000001EFE3023468 | ПРИОСТАНОВЛЕН | 5 | 0x000001EF6B46A160 |
| 0x000001EF4758ACA8 | 0x000001EFE3AF1468 | ПРИОСТАНОВЛЕН | 6 | 0x000001EF6BD38160 |
| 0x000001EF4758ACA8 | 0x000001EFE4AFCCA8 | ПРИОСТАНОВЛЕН | 6 | 0x000001EF6ACB4160 |
| 0x000001EF4758ACA8 | 0x000001EFDE043848 | ПРИОСТАНОВЛЕН | 7 | 0x000001EEA18C2160 |
| 0x000001EF4758ACA8 | 0x000001EF69038108 | ПРИОСТАНОВЛЕН | 7 | 0x000001EF6AEBA160 |
| 0x000001EF4758ACA8 | 0x000001EFCFDD8CA8 | ПРИОСТАНОВЛЕН | 8 | 0x000001EFCB6F0160 |
| 0x000001EF4758ACA8 | 0x000001EFCFDD88C8 | ПРИОСТАНОВЛЕН | 8 | 0x000001EF6DC46160 |
| 0x000001EF4758ACA8 | 0x000001EFBCC54108 | ПРИОСТАНОВЛЕН | 9 | 0x000001EFCB886160 |
| 0x000001EF4758ACA8 | 0x000001EC86279468 | ПРИОСТАНОВЛЕН | 9 | 0x000001EF6DE08160 |
| 0x000001EF4758ACA8 | 0x000001EFDE901848 | ПРИОСТАНОВЛЕН | 10 | 0x000001EFF56E0160 |
| 0x000001EF4758ACA8 | 0x000001EF6DB32108 | ПРИОСТАНОВЛЕН | 10 | 0x000001EFCC3D0160 |
| 0x000001EF4758ACA8 | 0x000001EC8628D468 | ПРИОСТАНОВЛЕН | 11 | 0x000001EFBFA4A160 |
| 0x000001EF4758ACA8 | 0x000001EFBD3A1C28 | ПРИОСТАНОВЛЕН | 11 | 0x000001EF6BD72160 |
Обратите внимание, что всем 16 дочерним задачам назначены разные рабочие потоки (их можно увидеть в столбце worker_address), но все рабочие роли назначены одному и тому же пулу из восьми планировщиков (0, 5, 6, 7, 8, 9, 10, 11), а родительская задача назначена планировщику, не входящему в этот пул (3).
Внимание
После планирования первого набора параллельных задач в данной ветви ядро СУБД будет использовать тот же пул планировщиков для любых дополнительных задач в других ветвях. Это означает, что один и тот же набор планировщиков будет использоваться для всех параллельных задач в рамках всего плана выполнения, ограниченных только значением MaxDOP.
Ядро СУБД SQL Server всегда будет пытаться назначить планировщиков из того же узла NUMA для выполнения задачи и распределять их поочередно (в порядке очередности), если планировщики доступны. Однако рабочий поток, назначенный родительской задаче, может быть помещен в узел NUMA, отличный от используемого для других задач.
Рабочий поток может оставаться активным в планировщике только во время его кванта (4 мс) и должен уступить управление после истечения этого кванта, так чтобы рабочий поток, назначенный другой задаче, мог стать активным. Когда квант рабочей задачи истекает и становится неактивным, соответствующая задача помещается в очередь FIFO в состоянии RUNNABLE, пока она не перейдет в состояние RUNNING, если только задача не требует доступа к ресурсам, которые недоступны в данный момент, например, задвижка или замок, в этом случае задача будет помещена в состояние SUSPENDED, пока эти ресурсы не станут доступны.
Совет
В выводе DMV, показанном выше, все активные задачи находятся в состоянии SUSPENDED. Дополнительные сведения об ожидающих задачах можно получить, выполняя запрос динамического административного представления sys.dm_os_waiting_tasks.
В итоге параллельный запрос создает несколько задач. Каждая задача должна быть назначена одному рабочему потоку. Каждый рабочий поток должен быть назначен одному планировщику. Таким образом, количество используемых планировщиков не может превышать количество параллельных задач в ветви, заданное конфигурацией MaxDOP или указанием запроса. Координирующий поток не влияет на ограничение MaxDOP.
Выделение потоков на процессор
По умолчанию каждый экземпляр SQL Server запускает каждый поток, а операционная система распределяет потоки из экземпляров SQL Server среди процессоров (ЦП) на компьютере на основе нагрузки. Если сходство процессов включено на уровне операционной системы, операционная система назначает каждый поток конкретному ЦП. В отличие от этого, модуль базы данных SQL Server назначает рабочие потоки SQL Server планировщикам, которые равномерно распределяют потоки между ЦП, в циклическом порядке.
Для обеспечения многозадачности, например, когда несколько приложений используют один и тот же набор ЦП, операционная система иногда распределяет рабочие потоки между разными ЦП. Хотя с точки зрения операционной системы эти действия эффективны, они могут снизить производительность SQL Server при больших системных нагрузках, так как данные кеша каждого процессора будут постоянно обновляться. В этих условиях назначение процессоров к конкретным потокам может повысить производительность, устраняя повторную загрузку процессоров и уменьшая количество переносов потоков между ЦП (а значит, уменьшая число переключений контекста). Такая связь между потоком и процессором называется привязкой процессора. Если привязка была включена, операционная система назначает каждую нить конкретному ЦП.
Параметр affinity mask задается с помощью инструкции ALTER SERVER CONFIGURATION. Если маска привязки не задана, SQL Server выделяет рабочие потоки равномерно среди планировщиков, которые не были отключены.
Внимание
Не настраивайте привязку ЦП в операционной системе и не настраивайте маску привязки в SQL Server. Эти настройки предназначены для достижения одного результата, и если их значения будут несогласованными, результат может быть непредсказуем. Дополнительные сведения см. в разделе Параметр affinity mask.
Пул потоков помогает оптимизировать производительность при подключении к серверу большого числа пользователей. Обычно для каждого запроса в операционной системе создается отдельный поток. Однако в случае сотен соединений с сервером, использование одного потока на каждый запрос приводит к потреблению большого числа системных ресурсов. Параметр "Максимальное количество рабочих потоков" позволяет SQL Server создавать пул рабочих потоков для обслуживания большего количества запросов, что повышает производительность.
Использование параметра облегченного пула
Внимание
Начиная с SQL Server 2025 (17.x), функция режима волокна , включенная параметром lightweight pooling , устарела и планируется удалить в будущей версии SQL Server. Из-за известных проблем стабильности и совместимости корпорация Майкрософт рекомендует избегать использования этой функции в любой версии SQL Server.
Нагрузка, возникающая при контекстном переключении потоков, может быть не очень высока. Большинство экземпляров SQL Server не видят никаких различий в производительности между настройкой параметра упрощенного пула в значение 0 или 1. Воспользоваться преимуществами, связанными с параметром Использование упрощенных пулов , могут только те экземпляры SQL Server, которые выполняются на компьютере со следующими характеристиками:
- большой сервер с несколькими процессорами
- все процессоры работают почти на пределе производительности;
- Уровень переключения контекста высокий.
В таких системах может наблюдаться небольшое повышение эффективности, если для параметра "Использование упрощенных пулов" установлено значение 1.
Внимание
Не используйте планирование в режиме волокон для выполнения повседневных операций. Это может снизить производительность, лишая регулярных преимуществ переключения контекста, так как некоторые компоненты SQL Server не могут правильно функционировать в волоконном режиме. Дополнительные сведения см. в разделе об использовании упрощенных пулов.
Выполнение потоков и нитей
В Microsoft Windows используется числовая система приоритетов, распределяющая выполняемые потоки по уровням от 1 до 31. Значение 0 зарезервировано для использования операционной системой. При наличии в очереди на выполнение нескольких потоков Windows сначала обслуживает поток с наивысшим приоритетом.
Каждый экземпляр SQL Server по умолчанию имеет уровень приоритета 7, что соответствует стандартному уровню. Это значение по умолчанию задает потокам SQL Server достаточно высокий уровень приоритета, позволяющий им получать достаточно ресурсов ЦП, не снижая производительность других приложений.
Внимание
Эта функция будет удалена в будущей версии SQL Server. Избегайте использования этого компонента в новых разработках и запланируйте изменение существующих приложений, в которых он применяется.
Параметр конфигурации priority boost используется для повышения приоритета потоков экземпляра SQL Server до значения 13. Это наивысший приоритет. Этот параметр назначает потокам SQL Server более высокий приоритет по отношению к другим приложениям. Таким образом, потоки SQL Server, как правило, будут выполняться всякий раз, когда они готовы к запуску, и не прерываются потоками из других приложений. Это может улучшить производительность, когда сервер запускает только экземпляры SQL Server и никаких других приложений. Однако, если в SQL Server выполняется операция, требующая много памяти, другие приложения, скорее всего, не имеют достаточного приоритета, чтобы прервать поток SQL Server.
Если на компьютере выполняется несколько экземпляров SQL Server, повышение приоритетов одних может привести к снижению производительности других. Кроме того, включение параметра priority boost может привести к простою других приложений и компонентов, выполняемых на компьютере. Таким образом, данный параметр рекомендуется использовать только в строго определенных условиях.
Добавление ЦП без выключения системы
Внимание
Начиная с SQL Server 2025 (17.x), функция горячего добавления ЦП не рекомендуется и планируется удалить в будущей версии SQL Server. Из-за известных проблем стабильности корпорация Майкрософт рекомендует избегать использования этой функции в администрирования SQL Server в любой версии SQL Server.
Процессоры с поддержкой горячего добавления — это возможность динамически добавлять центральные процессоры в запущенную систему. Добавление центральных процессоров может осуществляться физически — путем добавления нового оборудования, логически — путем аппаратного секционирования в сети, виртуально — через уровень виртуализации.
Требования для ЦП с поддержкой горячего добавления:
- Требуется оборудование, которое поддерживает горячее добавление ЦП.
- Требуется поддерживаемая версия Windows Server Datacenter или Enterprise. Начиная с Windows Server 2012, возможность горячего добавления поддерживается в выпуске Standard.
- Требуется выпуск SQL Server Enterprise.
- SQL Server нельзя настроить для использования soft NUMA. Дополнительные сведения о программной архитектуре NUMA см. в разделе Архитектура Soft-NUMA (SQL Server).
SQL Server не использует автоматически ЦП после их добавления. Благодаря этому SQL Server не использует ЦП, добавленные для каких-либо других целей. После добавления ЦП выполните инструкцию RECONFIGURE , чтобы SQL Server распознал новые ЦП как доступные ресурсы.
Если параметр affinity64 mask настроен, его необходимо изменить для использования новых ЦП.
Рекомендации по запуску SQL Server на компьютерах с более чем 64 ЦП
Назначение аппаратных потоков ЦПУ
Не используйте маску сходства и параметры конфигурации сервера affinity64 для привязки процессоров к определенным потокам. Эти параметры ограничены 64 процессорами. Вместо этого следует использовать параметр SET PROCESS AFFINITY инструкции ALTER SERVER CONFIGURATION.
Управление размером файла журнала транзакций
Не следует полагаться на автоматическое увеличение размера файла журнала транзакций. Увеличение журнала транзакций должно происходить последовательно. Увеличение журнала может помешать выполнению операций записи транзакций до тех пор, пока увеличение журнала не будет завершено. Вместо этого заранее выделите место для файлов журнала, установив размер файла в значение, достаточное для поддержки обычной рабочей нагрузки в среде.
Установка максимальной степени параллелизма для операций с индексами
На компьютерах, имеющих несколько процессоров, с помощью временного изменения модели восстановления базы данных на модель восстановления с неполным протоколированием или простую модель восстановления можно улучшить производительность операций с индексами, таких как создание или перестроение индексов. Эти операции с индексами могут создавать значительную нагрузку на журнал, а конфликт журнала может негативно повлиять на оптимальную степень параллелизма, выбранную SQL Server.
Помимо настройки параметра конфигурации сервера max degree of parallelism (MAXDOP), рассмотрите возможность настройки параллелизма для операций с индексами с помощью параметра MAXDOP. Дополнительные сведения см. в статье Настройка параллельных операций с индексами. Дополнительные сведения и рекомендации по настройке параметра конфигурации сервера с максимальной степенью параллелизма см. в разделе "Настройка параметра конфигурации сервера максимального уровня параллелизма".
Максимальное количество рабочих потоков, опция
SQL Server при запуске динамически настраивает опцию конфигурации сервера максимального числа рабочих потоков. SQL Server использует количество доступных ЦП и системную архитектуру для определения конфигурации сервера во время запуска с помощью документированной формулы.
Этот параметр является дополнительным вариантом и должен быть изменен только опытным специалистом по базе данных.
Если вы подозреваете проблему с производительностью, возможно, она не связана с доступностью рабочих потоков. Скорее всего, причиной является что-то наподобие операций ввода-вывода, из-за которых рабочие потоки ожидают. Рекомендуется найти причину проблемы производительности, прежде чем изменять параметр max worker threads. Тем не менее, если необходимо вручную задать максимальное число рабочих потоков, это значение конфигурации всегда должно быть в семь раз больше числа ЦП, имеющихся в системе. Дополнительные сведения см. в статье Настройка параметра max worker threads.
Избегайте использования трассировки SQL и профилировщика SQL Server
Рекомендуется не использовать трассировку SQL и профилировщик SQL в рабочей среде. Издержки использования этих средств также увеличиваются по мере увеличения числа ЦП. Если в рабочей среде необходимо использовать приложение трассировки SQL, следует ограничить до минимума число отслеживаемых событий. Следует внимательно анализировать и тестировать каждое трассировочное событие под нагрузкой и избегать комбинаций, которые значительно влияют на производительность.
Внимание
SQL Trace и SQL Server Profiler устарели. Пространство имен Microsoft.SqlServer.Management.Trace, содержащее объекты трассировки и повторного воспроизведения SQL Server, также является устаревшим.
Эта функция будет удалена в будущей версии SQL Server. Избегайте использования этого компонента в новых разработках и запланируйте изменение существующих приложений, в которых он применяется.
Вместо этого используйте расширенные события. Дополнительные сведения о расширенных событиях см. в статьях Краткое руководство. Расширенные события в SQL Server и Использование профилировщика XEvent для SSMS.
Примечание.
SQL Server Profiler для рабочих нагрузок служб Analysis Services не устарел и будет поддерживаться.
Установка количества tempdb файлов данных
Количество файлов зависит от числа (логических) процессоров на компьютере. Как правило, если число логических процессоров меньше или равно восьми, используйте равное ему число файлов данных. Если число логических процессоров больше восьми, используйте восемь файлов данных, а затем, если состязание сохраняется, увеличивайте число файлов данных на значение, кратное 4, пока состязание не уменьшится до приемлемого уровня, или внесите изменения в рабочую нагрузку или код. Кроме того, помните о других рекомендациях для tempdb, которые можно найти в документации по оптимизации производительности tempdb в SQL Server.
Однако, тщательно учитывая потребности параллелизма tempdb, вы можете сократить затраты на управление базами данных. Например, если в системе используется 64 ЦП и обычно используется tempdbтолько 32 запроса, увеличение числа tempdb файлов до 64 не улучшит производительность.
Компоненты SQL Server, которые поддерживают более 64 ЦП
В следующей таблице перечислены компоненты SQL Server и указано, могут ли они использовать больше чем 64 ЦП.
| Имя процесса | Исполняемая программа | Использование более 64 процессоров |
|---|---|---|
| Система управления базами данных SQL Server | Sqlserver.exe, | Да |
| Службы отчетов | Rs.exe | Нет |
| Службы Аналитических услуг | As.exe | Нет |
| Службы интеграции | Is.exe | Нет |
| Сервисный брокер | Sb.exe | Нет |
| Полнотекстовый поиск | Fts.exe | Нет |
| Агент SQL Server | Sqlagent.exe | Нет |
| Среда SQL Server Management Studio | Ssms.exe | Нет |
| Настройка SQL Server | Setup.exe | Нет |