Машинное обучение для компьютерного зрения
Возможность использовать фильтры для применения эффектов к изображениям полезна в задачах обработки изображений, таких как программное обеспечение редактирования изображений. Однако цель компьютерного зрения часто заключается в извлечении смысла или по крайней мере полезных сведений из изображений; для создания моделей машинного обучения, которые обучены распознавать функции на основе больших объемов существующих образов.
Совет
В этом уроке предполагается, что вы знакомы с основными принципами машинного обучения, и что у вас есть концептуальные знания о глубоком обучении с нейронными сетями. Если вы не знакомы с машинным обучением, рассмотрите возможность работы с основами модуля машинного обучения в Microsoft Learn.
Сверточная нейронная сеть (CNN)
Одной из наиболее распространенных архитектур модели машинного обучения для компьютерного зрения является сверточная нейронная сеть (CNN), тип архитектуры глубокого обучения. CNN используют фильтры для извлечения числовых карт признаков из изображений, а затем передают значения признаков в модель глубокого обучения для генерации прогноза меток. Например, в сценарии классификации изображений метка представляет основную тему изображения (иными словами, что это за изображение?). Вы можете обучить модель CNN с изображениями различных видов фруктов (например, яблок, бананов и апельсинов), чтобы прогнозируемая метка соответствовала типу фруктов на данном изображении.
Во время процесса обучения для CNN ядра фильтров изначально определяются с использованием случайно сгенерированных значений веса. Затем, по ходу процесса обучения прогнозы моделей оцениваются по известным значениям меток, а значения веса фильтра корректируются для повышения точности. В конце концов, обученная модель классификации изображений фруктов использует значения веса фильтров, которые лучше всего извлекают признаки, помогающие идентифицировать различные виды фруктов.
На следующей схеме показано, как работает CNN для модели классификации изображений:
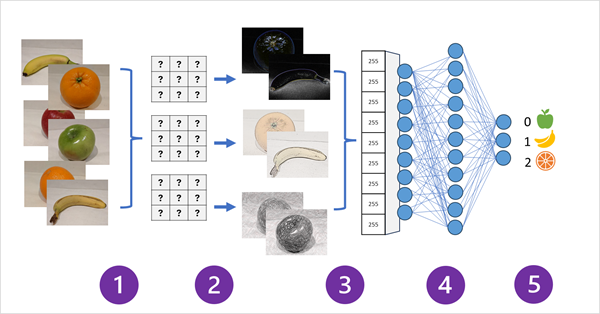
- Изображения с известными метками (например, 0: яблоко, 1: банан или 2: апельсин) передаются в сеть для обучения модели.
- Один или несколько слоев фильтров используются для извлечения признаков из каждого изображения, так как оно передается через сеть. Ядра фильтров начинаются со случайно назначенных значений веса и генерируют массивы числовых значений, называемые картами признаков.
- Карты признаков сводятся в одномерный массив значений признаков.
- Значения признаков передаются в полностью подключенную нейронную сеть.
- Выходной слой нейронной сети использует обратимую или аналогичную функцию для получения результата, содержащего значение вероятности для каждого возможного класса, например [0,2; 0,5; 0,3].
Во время обучения вероятности выходных данных сравниваются с фактической меткой класса - например, изображение банана (класса 1) должно иметь значение [0,0, 1.0, 0,0]. Разница между прогнозируемыми и фактическими оценками классов используется для вычисления потери в модели, а весы в полностью подключенной нейронной сети и ядра фильтров в слоях извлечения признаков изменяются для уменьшения потери.
Процесс обучения повторяется в течение нескольких эпох, пока не будет изучен оптимальный набор весов. Затем весовые значения сохраняются и модель можно использовать для прогнозирования меток для новых изображений, для которых метка неизвестна.
Примечание.
Архитектуры CNN обычно включают несколько слоев сверточных фильтров и дополнительные слои, чтобы уменьшить размер карт функций, ограничить извлеченные значения и в противном случае управлять значениями признаков. Эти слои были опущены в этом упрощенном примере, чтобы сосредоточиться на ключевой концепции, которая заключается в том, что фильтры используются для извлечения числовых признаков из изображений, которые затем используются в нейронной сети для прогнозирования меток изображений.
Преобразователи и многомодальные модели
CNN в основе решений компьютерного зрения уже много лет. Хотя они часто используются для решения проблем классификации изображений, как описано ранее, они также являются основой для более сложных моделей компьютерного зрения. Например, модели обнаружения объектов объединяют слои извлечения признаков CNN с идентификацией областей, интересующих изображения, чтобы найти несколько классов объектов в одном и том же изображении.
Преобразователи
Большинство достижений компьютерного зрения на протяжении десятилетий были обусловлены улучшением моделей на основе CNN. Однако в другой дисциплине ИИ — обработка естественного языка (NLP), другой тип архитектуры нейронной сети, называемый преобразователем , позволил разрабатывать сложные модели для языка. Преобразователи работают путем обработки огромных объемов данных и кодировки языковых маркеров (представляющих отдельные слова или фразы) как векторные внедрения (массивы числовых значений). Внедрение можно представить как набор измерений, каждый из которых представляет некоторые семантические атрибуты маркера. Внедрения создаются таким образом, что маркеры, которые обычно используются в одном контексте, ближе по размеру, чем несвязанные слова.
Как простой пример, на следующей схеме показаны некоторые слова, закодированные как трехмерные векторы, и вычисленные в трехмерном пространстве:
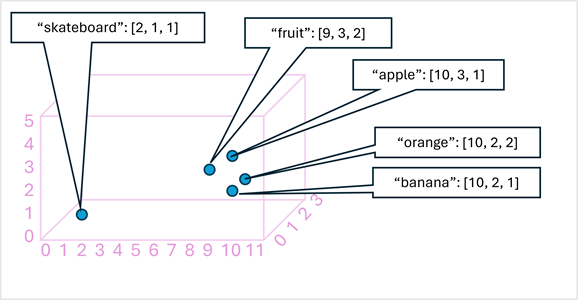
Маркеры, семантические аналогичные, кодируются в аналогичных позициях, создавая семантические языковые модели, которые позволяют создавать сложные решения NLP для анализа текста, перевода, создания языка и других задач.
Примечание.
Мы использовали только три измерения, так как это легко визуализировать. В действительности кодировщики в сетях преобразователей создают векторы с большим количеством измерений, определяя сложные семантические связи между токенами на основе линейных алгебраических вычислений. Математика, связанная с ней, сложна, как и архитектура модели преобразователя. Наша цель заключается в том, чтобы предоставить концептуальное представление о том, как кодировка создает модель, которая инкапсулирует связи между сущностями.
Мультимодальные модели
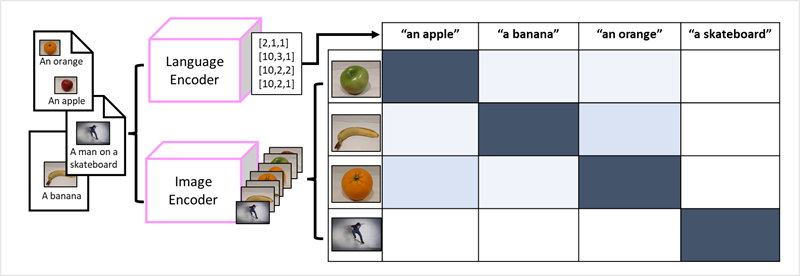
Успех преобразователей в качестве способа создания языковых моделей привел исследователей ИИ к рассмотрению того же подхода, который будет эффективным для данных изображений. Результатом является разработка многомодальных моделей, в которых модель обучена с помощью большого объема заголовок изображений без фиксированных меток. Кодировщик изображений извлекает функции из изображений на основе значений пикселей и объединяет их с внедренными текстами, созданными кодировщиком языка. Общая модель инкапсулирует связи между внедренными маркерами естественного языка и функциями изображений, как показано ниже:
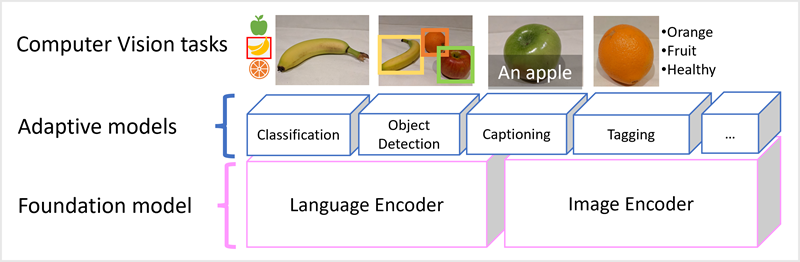
Модель Microsoft Florence является просто такой моделью. Обученная на огромных объемах изображений с подписями из Интернета, она включает в себя как языковой кодировщик, так и кодировщик изображений. Florence является примером базовой модели. Другими словами, предварительно обученная общая модель, на основе которой можно создать несколько адаптивных моделей для специализированных задач. Например, можно использовать Florence в качестве базовой модели для адаптивных моделей, выполняющих следующие действия:
- Классификация изображений: определение категории, к которой принадлежит изображение.
- Обнаружение объектов: поиск отдельных объектов на изображении.
- Заголовок: создание соответствующих описаний для изображений.
- Расстановка тегов: составление списка соответствующих текстовых тегов для изображения.
Многомодальные модели, такие как Флоренция, находятся на переднем крае компьютерного зрения и искусственного интеллекта в целом, и, как ожидается, будут двигать прогресс в таких решениях, которые ИИ делает возможным.