Упражнение. Построение и обучение нейронной сети
В этом модуле вы используете Keras для построения и обучения нейронной сети, которая анализирует текст для определения тональности. Для обучения нейронной сети вам нужны данные. Чтобы не загружать внешний набор данных, вы будете использовать классификацию тональности обзоров фильмов на IMDB, которая входит в Keras. Набор данных IMDB содержит 50 000 обзоров фильмов, которые оцениваются как положительные (1) или отрицательные (0). Набор данных разделен на 25 000 обзоров для обучения и 25 000 обзоров для тестирования. Тональность в этих обзорах станет основой, по которой нейронная сеть будет анализировать текст и оценивать тональность.
Набор данных IMDB является одним из нескольких полезных наборов данных, включенных в Keras. Полный список встроенных наборов данных см. в разделе https://keras.io/datasets/.
Введите или вставьте в первую ячейку записной книжки следующий код и нажмите кнопку Запуск (или клавиши SHIFT + ВВОД), чтобы выполнить этот код и добавить ниже новую ячейку:
from keras.datasets import imdb top_words = 10000 (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=top_words)Этот код загружает набор данных IMDB, который входит в состав Keras, и создает словарь сопоставления слов во всех 50 000 обзорах с целыми числами, которые указывают относительную частоту слов. Каждому слову назначается уникальное целое число. Самому распространенному слову присваивается номер 1, следующему — номер 2 и т. д.
load_dataтакже возвращает пару кортежей, содержащих обзоры фильмов (в этом примереx_trainиx_test), а также значения 1 и 0, которые обозначают положительные и отрицательные обзоры (y_trainиy_test).Вы должны увидеть сообщение "Using TensorFlow backend" (Используется серверная часть TensorFlow), указывающее на то, что Keras использует TensorFlow в качестве серверной части.
Загрузка набора данных IMDB
Если вы хотите в Keras использовать в качестве серверной части Microsoft Cognitive Toolkit или CNTK, добавьте несколько строк кода в начале записной книжки. Пример см. в разделе CNTK и Keras в записных книжках Azure.
Что именно загрузила функция
load_data? Переменная с именемx_train— это список из 25 000 списков, каждый из которых представляет один обзор фильма. (x_testтакже является списком 25 000 списков, представляющих 25 000 обзоров.x_trainбудет использоваться для обучения, аx_test— для тестирования.) Но внутренние списки, которые представляют обзоры, не содержат слов; они содержат целые числа. Вот как это описано в документации по Keras: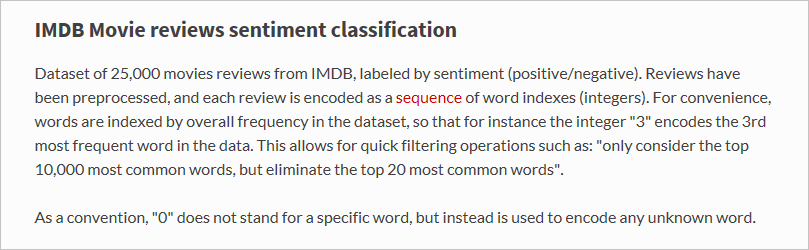
Внутренние списки содержат числа, а не текст, потому что мы обучаем нейронную сеть не с помощью текста, а с помощью чисел. А именно, с помощью тензоров. В этом случае каждый обзор является одномерным тензором (представьте себе одномерный массив), содержащим целые числа, которые обозначают слова из обзора. Чтобы продемонстрировать это, введите следующую инструкцию Python в пустую ячейку и выполните ее, чтобы посмотреть целые числа для первого обзора в обучающем наборе:
x_train[0]
Целые числа в первом обзора обучающего набора IMDB
Первое число в списке — 1 — не представляет слово. Оно отмечает начало обзора, и это относится к остальным обзорам в наборе данных. Числа 0 и 2 также зарезервированы, так что из других чисел нужно вычитать 3, чтобы сопоставить число в обзоре с числом в словаре. Второе число — 14 — обозначает слово, которому соответствует число 11 в словаре; третье число — это слово 19 из словаря и т. д.
Хотите увидеть, как выглядит словарь? В новой ячейке записной книжки выполните следующую инструкцию:
imdb.get_word_index()Отображается только подмножество записей словаря, но в целом словарь содержит более 88 000 слов и целых чисел, которые им соответствуют. Ваши выходные данные, скорее всего, не будут соответствовать выходным данным на снимке экрана, так как словарь создается заново при каждом вызове
load_data.
Словарь сопоставления слов с целыми числами
Как вы уже видели, каждый обзор в наборе данных кодируется как коллекция целых чисел, а не слов. Можно ли раскодировать обзор и увидеть исходный текст? Введите следующие инструкции в новую ячейку и выполните их, чтобы показать первый обзор в
x_trainв текстовом формате:word_dict = imdb.get_word_index() word_dict = { key:(value + 3) for key, value in word_dict.items() } word_dict[''] = 0 # Padding word_dict['>'] = 1 # Start word_dict['?'] = 2 # Unknown word reverse_word_dict = { value:key for key, value in word_dict.items() } print(' '.join(reverse_word_dict[id] for id in x_train[0]))В выходных данных ">" отмечает начало обзора, а "?" — слова, которые не находятся среди 10 000 наиболее распространенных слов в наборе данных. Эти "неизвестные" слова обозначены цифрой 2 в списке целых чисел, представляющих обзор. Помните параметр
num_words, переданный вload_data? Здесь он вступает в действие. Он не уменьшает размер словаря, но ограничивает диапазон целых чисел, используемый для кодирования обзоров.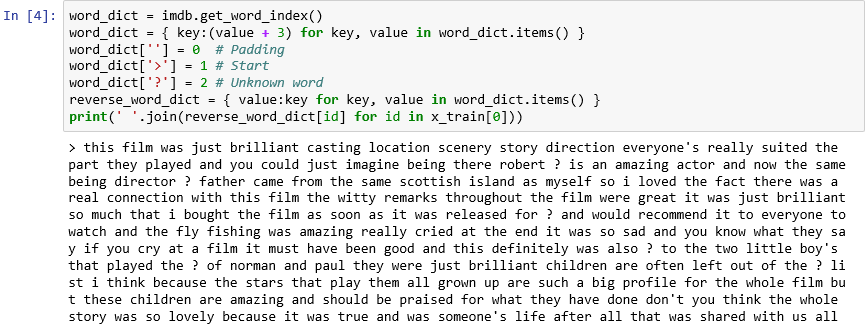
Первый обзор в текстовом формате
Обзоры "чистые" в том смысле, что буквы были преобразованы в нижний регистр, а знаки препинания удалены. Но они не готовы к обучению нейронной сети для анализа текста с целью определения тональности. При обучении нейронной сети с помощью коллекции тензоров каждый тензор должен иметь одинаковую длину. В настоящий момент списки, представляющие обзоры в
x_trainиx_test, имеют разную длину.К счастью, Keras включает функцию, которая принимает список списков в качестве входных данных и преобразует внутренние списки до указанной длины, усекая их или заполняя нулями. Введите следующий код в записную книжку и запустите его, чтобы все списки, представляющие обзоры фильмов в
x_trainиx_test, были длиной 500 целых чисел:from keras.preprocessing import sequence max_review_length = 500 x_train = sequence.pad_sequences(x_train, maxlen=max_review_length) x_test = sequence.pad_sequences(x_test, maxlen=max_review_length)Теперь, когда данные обучения и тестирования подготовлены, пришло время для построения модели! Выполните следующий код в записной книжке, чтобы создать нейронную сеть, которая выполняет анализ тональности:
from keras.models import Sequential from keras.layers import Dense from keras.layers.embeddings import Embedding from keras.layers import Flatten embedding_vector_length = 32 model = Sequential() model.add(Embedding(top_words, embedding_vector_length, input_length=max_review_length)) model.add(Flatten()) model.add(Dense(16, activation='relu')) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy',optimizer='adam', metrics=['accuracy']) print(model.summary())Убедитесь, что выходные данные выглядят следующим образом:
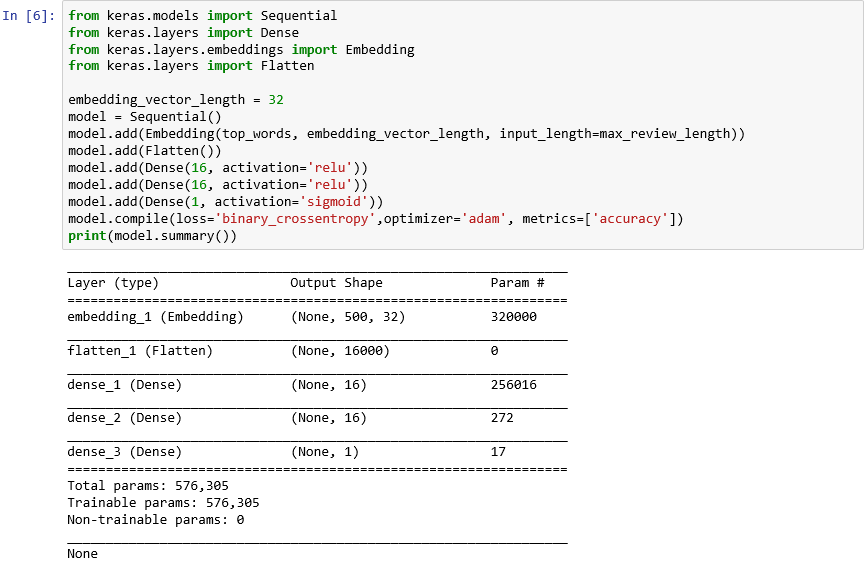
Создание нейронной сети с помощью Keras
Этот код является основой создания нейронной сети с помощью Keras. Сначала он создает экземпляр объекта
Sequential, представляющего "последовательную" модель, которая состоит из полного стека слоев, где выходные данные одного слоя предоставляют входные данные для следующего.Следующие несколько инструкций добавляют слои в модель. Первый слой — слой внедрения, который крайне важен для нейронных сетей, обрабатывающих слова. Слой внедрения, по сути, сопоставляет многомерные массивы с индексами слов в виде целых чисел с массивами чисел с плавающей запятой с меньшим числом измерений. Он также позволяет одинаково обрабатывать слова с аналогичными значениями. Полная обработка внедренных слов выходит за рамки этого задания, но вы можете узнать больше в статье Почему нужно начинать со слоев внедрения. Если вы предпочитаете более научное объяснение, см. раздел Эффективная оценка представлений слов в векторном пространстве. Вызов Flatten вслед за добавлением слоя внедрения преобразует выходные данные, чтобы они стали входными данными для следующего уровня.
Следующие три слоя, добавленные в модель, — это плотные слои, также известные как полностью подключенные слои. Это традиционные слои, которые часто используются в нейронных сетях. Каждый слой содержит n узлов, или нейронов, и каждый нейрон получает входные данные от нейронов в предыдущем слое, поэтому они называются "полностью подключенными". Именно эти слои позволяют нейронной сети обучаться на основе входных данных, итеративно строя предположения на выходе, проверяя результаты и настраивая соединения для достижения лучших результатов. Первые два плотных слоя в этой сети содержат по 16 нейронов. Это число выбрано произвольно. Вы можете повысить точность модели, поэкспериментировав с разными размерами. Последний плотный слой содержит только один нейрон, поскольку конечная цель сети — предсказать один результат, а именно тональность от 0,0 до 1,0.
Результатом является нейронная сеть, показанная на рисунке ниже. Сеть содержит входной слой, выходной слой и два скрытых слоя (плотные слои по 16 нейронов). Для сравнения: сложные современные нейронные сети содержат более ста слоев. Например, ResNet-152 от Microsoft Research, чья точность при определении объектов на фотографиях иногда превышает человеческую. Можно построить ResNet-152 с Keras, но вам потребуется кластер из компьютеров, оснащенных GPU, для обучения с нуля.
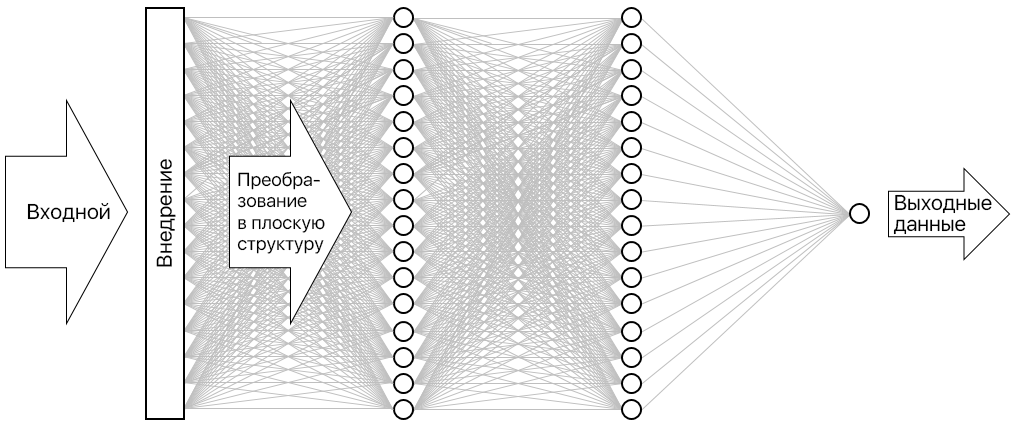
Визуализация нейронной сети
Вызов функции compile "компилирует" модель, указывая важные параметры, например, какой оптимизатор и какие метрики использовать для оценки точности на каждом этапе обучения модели. Обучение не начинается, пока вы не вызовете функцию модели
fit, поэтому вызовcompileобычно выполняется быстро.Теперь вызовите функцию fit для обучения нейронной сети:
hist = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=5, batch_size=128)Обучение займет около шести минут, то есть чуть больше минуты на эпоху.
epochs=5сообщает Keras, что нужно сделать 5 проходов вперед и назад по модели. С каждым проходом модель учится на обучающих данных и измеряет ("проверяет"), насколько хорошо она обучилась, с помощью тестовых данных. Затем она вносит корректировки и переходит к следующему проходу или эпохе. Это отражено в выходных данных функцииfit, которая показывает точность обучения (acc) и проверки (val_acc) для каждой эпохи.batch_size=128сообщает Keras использовать 128 образцов обучения за раз, чтобы обучить сети. Больший размер пакета сократит время обучения (в каждой эпохе требуется меньше проходов для охвата всех данных), но меньший размер пакета иногда повышает точность. После выполнения этого задания вы можете вернуться назад и переобучить модель с размером пакета 32, чтобы увидеть, как это повлияло на точность модели. Время обучение увеличится примерно вдвое.
Обучение модели
Эта модель необычна тем, что хорошо обучается с небольшим количеством эпох. Точность обучения быстро увеличивается до почти 100 %, в то время как точность проверки поднимается на эпоху или два, а затем выравнивает. Как правило, вы не хотите обучать модель дольше, чем требуется для стабилизации этих точности. Риск заключается во лжевзаимосвязи, из-за которой модель показывает высокий результат на тестовых данных, но ошибается на реальных. Одним из признаков лжевзаимосвязи модели является растущее несоответствие между точностью обучения и точностью проверки. Отличное введение в перенарядку см. в разделе "Overfitting" в Машинное обучение: что такое и как предотвратить его.
Чтобы визуализировать изменения точности обучения и проверки в ходе обучения, выполните следующие инструкции в новой ячейке записной книжки:
import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline sns.set() acc = hist.history['acc'] val = hist.history['val_acc'] epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, '-', label='Training accuracy') plt.plot(epochs, val, ':', label='Validation accuracy') plt.title('Training and Validation Accuracy') plt.xlabel('Epoch') plt.ylabel('Accuracy') plt.legend(loc='upper left') plt.plot()Данные о точности поступают из объекта
history, возвращаемого функцией моделиfit. На основе диаграммы вы бы порекомендовали увеличить, уменьшить или не изменять количество эпох обучения?Другой способ проверить лжевзаимосвязь — сравнить потери при обучении с потерями при проверке во время обучения. Проблемы оптимизации, подобные этим, направлены на то, чтобы свести такие потери к минимуму. С дополнительными сведениями вы можете ознакомиться здесь. Для определенной эпохи потери при обучении, значительно превышающие потери при проверке, могут свидетельствовать о лжевзаимосвязи. В предыдущем шаге вы использовали свойства
accиval_accсвойстваhistoryобъектаhistoryдля построения графика точности обучения и проверки. То же свойство также содержит значенияlossиval_loss, представляющие потери при обучении и проверке соответственно. Если бы вы хотели построить график с этими значениями, подобный приведенному ниже, как бы вы изменили код?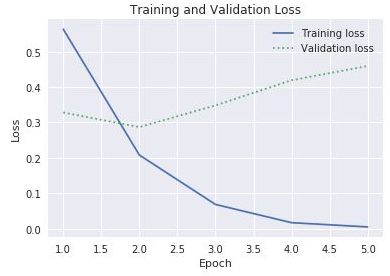
Потери при обучении и проверке
Учитывая, что разрыв между потерями при обучении и проверке начинает увеличиваться в третьей эпохе, что бы вы сказали, если бы кто-то предложил увеличить количество эпох до 10 или 20?
Закончите вызовом метода модели
evaluate, чтобы определить точность модели при измерении тональности, выраженной в тексте, на основе тестовых данных вx_test(обзоры) иy_test(значения 0 и 1, или "метки", указывающие на положительные и отрицательные отзывы):scores = model.evaluate(x_test, y_test, verbose=0) print("Accuracy: %.2f%%" % (scores[1] * 100))Какова рассчитанная точность модели?
Вероятно, вы достигли точности от 85 до 90 %. Это приемлемый результат, ведь вы построили модель с нуля (а не использовали предварительно обученную нейронную сеть) и потратили на обучение мало времени даже без GPU. Возможно добиться точности 95 % или выше с другими архитектурами нейронной сети, особенно с рекуррентными нейронными сетями (RNN), использующими слои долгой краткосрочной памяти (LSTM). Keras упрощает создание таких сетей, но время обучения значительно возрастает. Созданная модель обеспечивает разумный баланс между точностью и временем обучения. Тем не менее, если вы хотите узнать больше о создании RNN с Keras, см. раздел LSTM и ее быстрая реализация в Keras для анализа тональности.