Изучение анализа журналов Microsoft 365 и создания отчетов
Независимо от того, какие данные журнала собирает система, ведение журнала аудита полезно только в том случае, если его можно использовать для создания понятных оповещений и отчетов с действиями. Microsoft 365 использует автоматизированные системы, анализирующие данные журнала почти в режиме реального времени для поддержки непрерывного мониторинга безопасности и работоспособности службы.
Масштабный мониторинг безопасности и реагирование

Microsoft 365 выполняет непрерывный мониторинг безопасности своих систем для обнаружения угроз в службах Microsoft 365 и реагирования на них. Автоматизация, масштаб и облачные решения являются ключевыми основами нашей стратегии мониторинга и реагирования. Для эффективного отслеживания и остановки атак в масштабе некоторых основных служб Microsoft 365 наши системы мониторинга должны автоматически повышать точность оповещений почти в режиме реального времени. Аналогичным образом, при обнаружении проблемы нам необходима возможность масштабного снижения риска. Мы не можем полагаться на то, что наша команда исправит проблемы вручную на каждом компьютере. Чтобы масштабно снизить риски, мы используем облачные средства для автоматического применения средств противодействия и предоставления инженерам инструментов для быстрого применения утвержденных средств по снижению рисков в среде.
Данные журналов, которые мы собираем, дают возможность круглосуточно обеспечивать мониторинг безопасности и оповещения. Наша система оповещений анализирует данные журнала по мере их отправки, что позволяет оповещать пользователей практически в режиме реального времени. К ним относятся оповещения на основе правил и более сложные оповещения на основе моделей машинного обучения. Наша логика мониторинга выходит за рамки общих сценариев атак и включает в себя глубокую осведомленность об архитектуре и операциях служб. Мы используем данные мониторинга безопасности для постоянного улучшения наших моделей, чтобы обнаруживать атаки новых типов и повышать точность мониторинга безопасности.
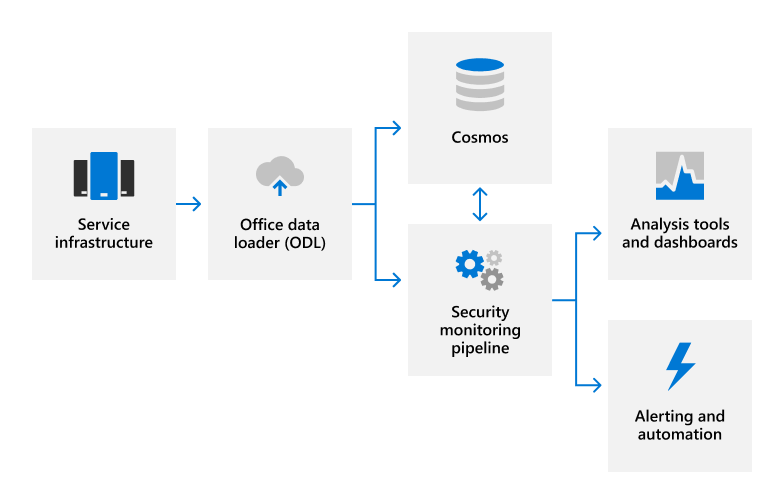
Если нам нужно отреагировать на оповещение или дополнительно изучить судебные доказательства в рамках всей службы, мы можем быстро это сделать во всей среде с помощью облачных средств. К этим средствам относятся полностью автоматизированные интеллектуальные агенты, которые реагируют на обнаруженные угрозы с помощью защитных контрмер. Во многих случаях эти агенты развертывают автоматические контрмеры, чтобы масштабно уменьшить количество обнаружений в сфере безопасности без вмешательства человека. Если это невозможно, система мониторинга безопасности автоматически оповещает дежурных инженеров, которые оснащены набором средств, позволяющих им действовать в режиме реального времени для масштабного уменьшения обнаруженных угроз. Потенциальные инциденты, обнаруженные при мониторинге безопасности, передаются оперативной службе Безопасности Microsoft 365 и разрешаются с помощью процесса реагирования на инциденты безопасности.
Мониторинг работоспособности служб
В дополнение к мониторингу безопасности команды обслуживания анализируют данные журналов своих служб в рамках мониторинга работоспособности служб. Мониторинг работоспособности служб помогает выявлять потенциальные проблемы, связанные с производительностью системы, взаимодействием с пользователями и отклонениями от базового использования службы. О проблемах работоспособности служб, которые влияют на доступность, сообщается инженерам команды обслуживания с помощью автоматических оповещений. Во многих случаях наши службы автоматически реагируют на проблемы работоспособности служб с помощью автоматизированных мер самовосстановления, таких как восстановление поврежденных данных из зоны репликации или автоматическое масштабирование службы для обработки повышенных нагрузок.
В дополнение к решению краткосрочных проблем команды обслуживания используют данные о тенденциях работоспособности служб для планирования емкости и других долгосрочных стратегических целей для поддержания оптимального обслуживания наших клиентов. Команды обслуживания включают данные о производительности служб и пользовательском интерфейсе в планирование функций, чтобы гарантировать, что наши службы продолжат соответствовать потребностям клиентов.