Упражнение. Создание модели работоспособности приложений
Компании Contoso Shoes требуется способ обнаружения, диагностики и прогнозирования проблем в этой архитектуре. Вы хотите создать модель работоспособности, измеримую с помощью состояния работоспособности, применяемой к потокам пользователей и систем. Цель заключается в выявлении потенциальных точек сбоя, прежде чем они могут вызвать сбой.
Текущее состояние и проблема
До сих пор вы добавили API проверки работоспособности и создали многорегионные возможности в архитектуре. Однако нет способа получить представление о сложной топологии, которая включает потоки пользователей и системы. Этот пробел необходимо заполнить, чтобы команда SRE быстро идентифицировать и устранять проблемы.
В недавнем инциденте команда не смогла увидеть каскадное влияние проблемы, возникшей из-за компонента API, влияющего на его зависимости платформы. В устранении неполадок было потрачено значительное время, так как неработоспособный компонент не может быть замечен сразу. В конечном счете, эта неэффективность привела к более длительным простоям, вызывая финансовую потерю компании.
Спецификация
Проектирование модели работоспособности, которая показывает связь между всеми компонентами в архитектуре, включая компоненты приложения и зависимости платформы. Фактор в элементах, существующих в потоке запросов, включая шлюз, вычислительные ресурсы, базы данных, хранилище, кэши и т. д. Также включают компоненты, которые обычно существуют вне потока запросов. Например, артефакты Open Container Initiative (OCI), секретные хранилища, службы конфигурации и другие. Все службы Azure должны быть настроены для отправки диагностических данных.
Добавьте в архитектуру единый приемник данных для сбора данных из различных источников.
Определите общее состояние работоспособности на основе статистических журналов и метрик. Представляет состояние в одном из трех состояний работоспособности: неработоспособные, деградированные и здоровые.
Визуализировать состояние работоспособности всех компонентов в иерархии, представляющей все потоки.
Рекомендуемый подход
Чтобы приступить к работе с проектом, рекомендуется выполнить следующие действия.
Внимание
Моделирование работоспособности — это комплексное упражнение. Подход, приведенный в этом разделе, предназначен для начала работы. Будьте обширны в применении модели ко всем функциональным и нефункциональным потокам в критически важном дизайне, чтобы получить целостное представление о системе.
1. Запуск моделирования работоспособности
Это теоретические упражнения. Моделирование работоспособности в действии проектирования сверху вниз, в котором вам потребуется полный список компонентов, используемых в архитектуре. Этот список должен включать все компоненты приложения и службы Azure.
Поместите эти компоненты в граф зависимостей, в которых отображается иерархическое представление решения. Верхний слой содержит потоки пользователей, отслеживающие запрос от конечного пользователя к веб-сайту, и потоки на уровне API приложения. Нижний слой содержит системные потоки из служб Azure. Кроме того, сопоставляют зависимости между ресурсами Azure.
Граф должен выглядеть примерно так:
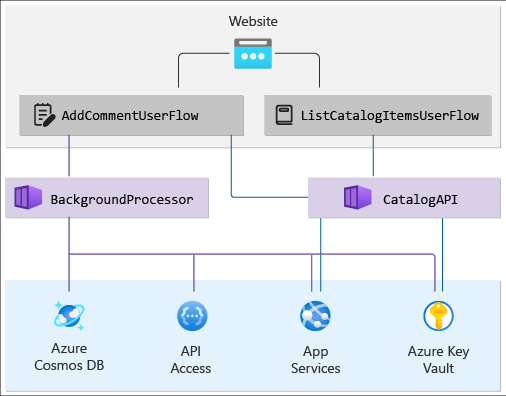
Проверка хода выполнения: работоспособность многоуровневого приложения
2. Определение показателей работоспособности
Для каждого компонента соберите метрики и пороговые значения метрик, а затем определите значение, по которому компонент должен считаться работоспособным, пониженным и неработоспособным. Это решение должно зависеть от ожидаемой производительности и нефункциональных бизнес-требований. Классифицируйте метрики следующим образом:
Метрики приложений: точки данных из кода приложения, например число исключений.
Метрики служб: точки данных из служб Azure, например единиц транзакций базы данных (DTU).
Метрики решения: точки данных уровня решения, такие как сквозное время обработки запроса.
Ниже приведен пример для служб приложение Azure:
| Службы приложений | Состояние работоспособности |
|---|---|
| Время < отклика 200ms HTTP Server errors < 2 |
 |
| Время < отклика 500ms ОШИБКИ HTTP-сервера < 2 |
 |
| Время > отклика 500ms ОШИБКИ HTTP-сервера > 2 |
 |
3. Определение общего состояния работоспособности
Для каждого пользовательского и системного потока определите общее состояние. Вам потребуется агрегировать состояние работоспособности отдельных компонентов, участвующих в этом потоке.
Предположим, что системный поток состоит из компонента приложения, плана службы приложение Azure и Служба приложений.
| API | План службы приложений | Службы приложений | Состояние работоспособности |
|---|---|---|---|
| Максимальная задержка < 30 мс | ЦП % 70 % < длина < очереди HTTP 5 |
Время < отклика 200ms HTTP Server errors < 2 |
|
| Максимальная задержка < 30 мс | ЦП % 90% < длина < очереди HTTP 5 |
Время < отклика 500ms ОШИБКИ HTTP-сервера < 2 |
|
| Максимальная задержка > 30 мс | ЦП % 90% > длина > очереди HTTP 5 |
Время > отклика 500ms ОШИБКИ HTTP-сервера > 2 |
|
Оценка работоспособности потока пользователя должна быть представлена наименьшей оценкой для всех сопоставленных компонентов. Для системных потоков следует применять соответствующие весы на основе критически важных бизнес-процессов. Между двумя потоками необходимо определить приоритеты финансово значимых или клиентских потоков пользователей.
Проверка хода выполнения. Пример — модель многоуровневой работоспособности
4. Сбор данных мониторинга
Вам потребуется единый приемник данных в каждом регионе, который собирает журналы и метрики для всех служб приложений и платформ, развернутых в рамках региональной метки. Вам потребуется другой приемник для хранения метрик, созданных из глобальных ресурсов, таких как Azure Front Door и Cosmos DB.
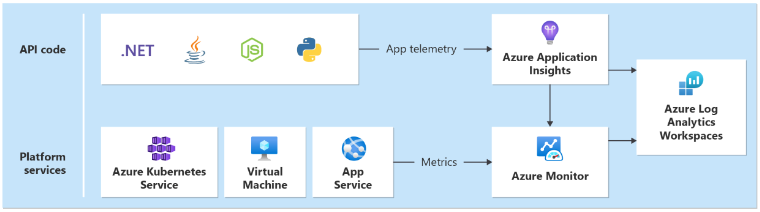
Выбор технологий
- приложение Azure Insights: используется для сбора всех данных телеметрии приложения.
- Журналы Azure Monitor: собирает данные, отправленные Application Insights и метрики платформы для служб Azure.
- Azure Log Analytics: используется в качестве центрального средства для анализа журналов и метрик со всех компонентов приложения и инфраструктуры.
Проверьте ход выполнения: единый приемник данных для коррелированного анализа
5.Настройка запросов для мониторинга данных
язык запросов Kusto (KQL) хорошо интегрирован с Log Analytics. Реализуйте пользовательские запросы KQL в качестве функций для получения данных из Azure Monitor.
Сохраните пользовательские запросы в репозитории кода, чтобы они импортировали и применялись автоматически в рамках конвейеров непрерывной интеграции и непрерывной доставки (CI/CD).
6.Визуализация состояния работоспособности
Вы можете визуализировать граф зависимостей с оценками работоспособности с помощью представления светофора. Используйте такие средства, как панели мониторинга Azure, мониторинг книг или Grafana. Приведем пример:
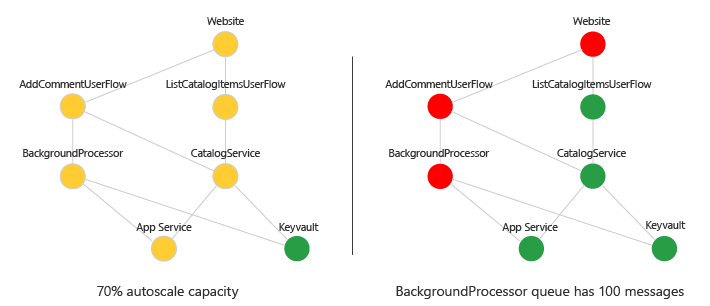
Проверка хода выполнения: визуализация
7.Настройка оповещений об изменениях состояния
Для немедленного привлечения внимания к проблемам следует использовать панели мониторинга с оповещениями.
Если состояние работоспособности компонента изменяется на "Деградированное " или "Неработоспособное", оператор должен быть немедленно уведомлен. Задайте оповещения на корневом узле, так как любое изменение этого узла указывает на неработоспособное состояние в базовых потоках пользователей или ресурсах.
Проверка хода выполнения: оповещение
Проверьте свою работу
Просмотрите эту демонстрацию по моделированию мониторинга и работоспособности. Вы охватывали все аспекты в вашем дизайне?
- У вас есть единый приемник данных для коррелированного анализа?
- Включены ли журналы приложений, метрики платформы и точки данных решения?
- Вы настроили панели мониторинга для визуализации состояния работоспособности всех компонентов?
- Вы рассмотрели точки сбоя в каждой службе (или ее части), которые могут вызвать сбой или предотвратить масштабирование, развертывание, мониторинг?
- Вы рассмотрели пакеты запросов для записи ключевых запросов, которые помогут быстрее устранить проблемы?
- Был ли ваш API проверки работоспособности полезным в этой модели? Нужно ли изменить этот API, чтобы лучше соответствовать модели работоспособности?