Введение
Проблемы машинного обучения и интеллектуального анализа данных (MLDM) сегодня экспоненциально растут. Соответственно возрастает и интерес к механизмам аналитики, которые могут эффективно выполнять алгоритмы MLDM в распределенных системах, таких как облака. Проектирование, реализация и тестирование распределенных приложений MLDM может оказаться сложной задачей, так как для этого обычно требуются эксперты, представляющие, как можно эффективно решать проблемы синхронизации, взаимоблокировок, связи, планирования, управления распределенным состоянием и отказоустойчивости. Многие последние достижения в алгоритмическом проектировании MLDM были сосредоточены на моделировании таких алгоритмов, как графы.
Экспресс-данные и вычисления с абстракцией графов
Давайте рассмотрим несколько примеров данных, смоделированных в виде графов, и покажем, как в этой модели могут быть выражены вычисления. Математически граф моделируется как множество: $G = \lbrace V, E \rbrace$, где $V$ — набор вершин $v_{i}$, а $E$ — набор ребер $e_{i}$. Кроме того, каждое ребро $e_{i}$ в $G$ представляет ребро точно между двумя вершинами: $\lbrace v_{i}, v_{j} \rbrace \in V$. Существует много типов графов; они могут быть ненаправленными, что означает $e = \lbrace v_{i}, v_{j} \rbrace = \lbrace v_{j}, v_{i} \rbrace \forall e \in E$ (т. е. все ребра эквивалентные и двунаправленные), или направленными, когда ребра различные и не равны. Графы также могут быть взвешенными, если в $\forall e \in E$ существует дополнительный параметр, который называется весом ($w_{i}$). Более того, вершины также могут быть взвешенными. Как будет показано, это очень полезная возможность в разных приложениях. Типичные графовые вычисления — это, например, вычисление кратчайшего пути между двумя точками, разделение графа на подграфы на основе некоторой метрики оптимизации (такой как минимальное количество срезов ребер или максимальный поток между графами), вычисление максимальной степени (вершины с наибольшим количеством ребер) и т. п.
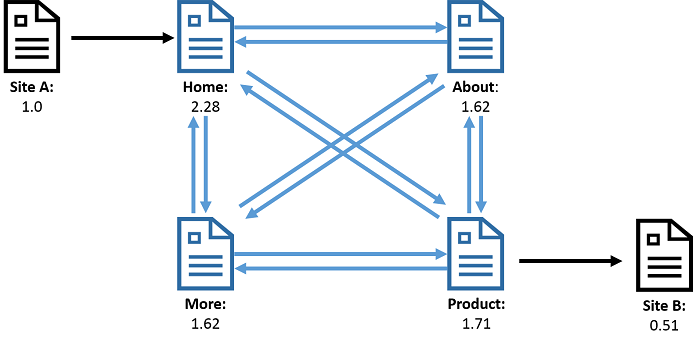
Рис. 1. Веб-граф, в котором вершины представляют веб-страницы, а ребра — ссылки между страницами. В результате запуска PageRank для этого графа каждая вершина приобретает связанное с ней значение, называемое рангом, которое представляет важность страницы. Ранг вычисляется исходя из количества входящих и исходящих ссылок на эту страницу.
На рисунке показан пример веб-графа. Вершины обозначают веб-страницы, а ребра — ссылки между веб-страницами. Классическим примером вычислений, выполняемых на веб-графе, является PageRank, который вычисляет важность веб-страницы, исходя из количества страниц, которые на нее ссылаются. Аналогично, в графе социальной сети, приведенном на рисунке 2, люди представлены в виде вершин, а ребра представляют отношения, такие как "друг" или "подписчик". Здесь наиболее интересным может быть, например, вычисление самых популярных людей (т. е. вычисление вершин с наибольшим числом ребер) или поиск сильно сплоченных сообществ людей, в которых все знают друг друга (подсчет треугольников).
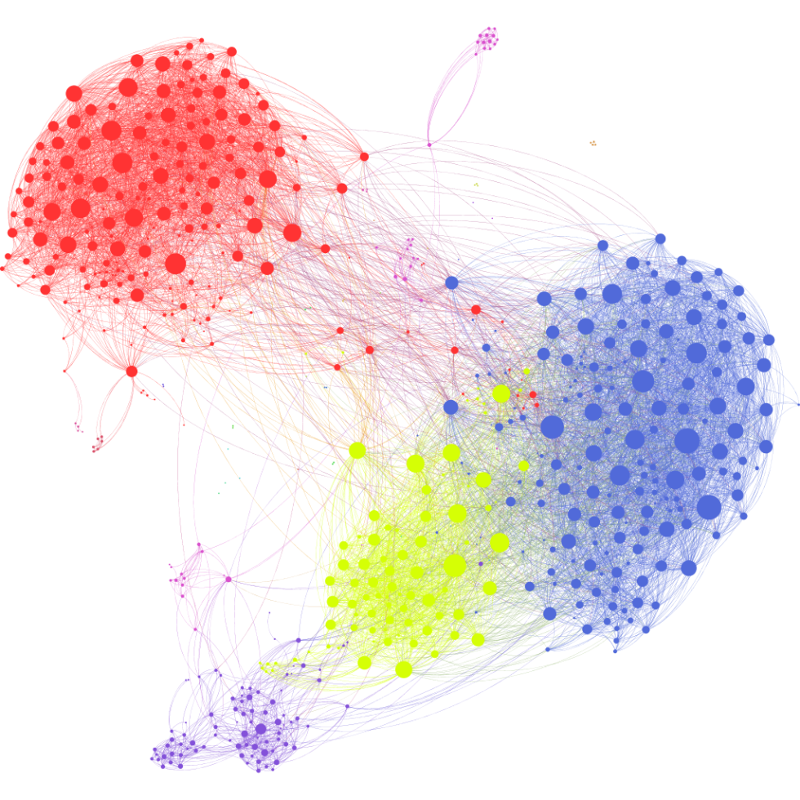
Рис. 2. Визуализация социального графа Facebook для ограниченного количества пользователей. (Источник)
Как уже можно понять, масштаб и сложность некоторых из упомянутых выше проблем постоянно растут. Один из крупнейших общедоступных веб-графов состоит из 1,7 миллиарда веб-страниц и 64 миллиардов гиперссылок. Общеизвестно, что это намного меньше тех данных, которые обрабатываются производственными системами таких интернет-компаний, как Google и Майкрософт. Представляется невозможным хранить все эти данные в памяти одного компьютера, а ведь нам еще нужны эффективные системы, которые могут обрабатывать такие объемы данных.
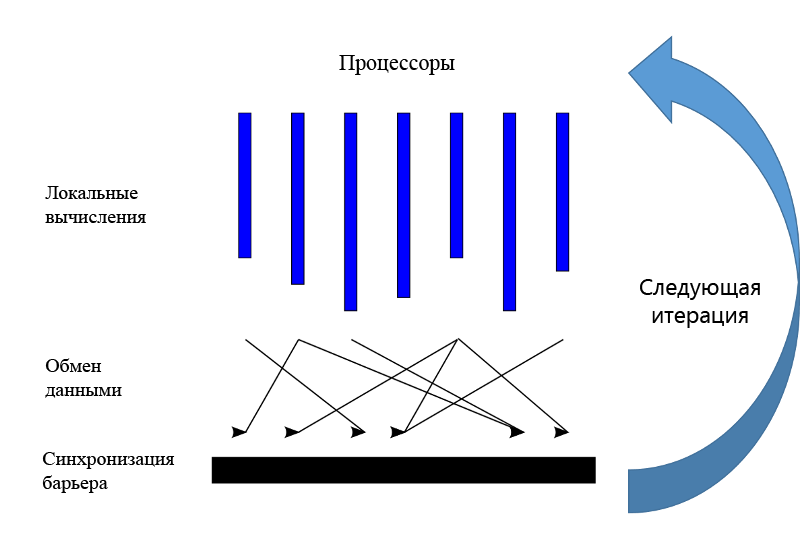
Рис. 3. Параллельная парадигма массового синхронного параллелизма (BSP)
Примером системы, предназначенной для распределенной обработки больших графов, является Pregel от Google. Pregel выполняет вычисления на графах итеративно, в жестком порядке. Этот подход также называется моделью параллельных вычислений, или BSP (Bulk-Synchronous Parallel). Программа Pregel выполняется в виде серии глобально синхронизированных итераций, которые могут приводить к определенным вычислениям, выполняемым в контексте каждой вершины графа (рис. 3). Затем вершины могут обмениваться сообщениями со своими соседями; обычно это делается для обновления состояния или других переменных. После того как все вершины завершат обработку текущего выполнения, Pregel запускает следующую итерацию. Сообщения, которыми машины обменивались в итерации $i$, доставляются в итерацию $i + 1$. Программа будет запускать последовательные итерации, пока не будет выполнено условие сходимости либо пока не будет завершено $N$ итераций, где $N$ — определенное пользователем максимальное число выполняемых итераций.
Хотя Pregel предлагает перспективный вариант в качестве распределенного подсистемы аналитики графа, он страдает от серьезного недостатка: Pregel выполняет вычисления синхронно, что может повлиять на производительность, так как среда выполнения каждой итерации всегда диктуется последним потоком для завершения выполнения. Можно также представить последствия, если граф не сбалансирован в контексте степени вершин. Это касается большого числа графов, представляющих интерес для аналитики больших данных. Например, социальные графы показывают степенное распределение, в котором меньшее количество вершин имеет большее количество ребер. В качестве примера можно привести граф подписчиков в Twitter (рис. 4), где знаменитости и влиятельные люди имеют миллионы подписчиков, в то время как у большинства других пользователей число подписчиков значительно меньше.
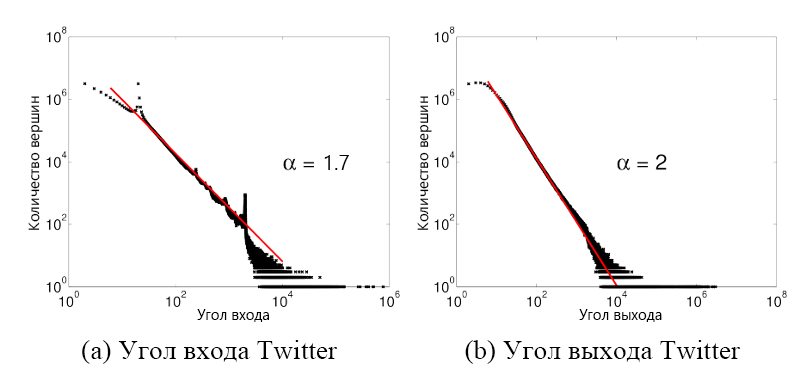
Рис. 4. Степенное распределение в графе подписчиков Twitter. Обратите внимание, что небольшое количество вершин (<100) имеет очень высокую степень и вне> (10 000)1
В этом модуле будет представлен GraphLab, еще один вариант механизма распределенной аналитики с параллелизмом графов, который может эффективно и корректно обрабатывать как синхронные, так и асинхронные проблемы MLDM и другие задачи. GraphLab также хорошо подходит для графов, демонстрирующих степенное распределение.
В этом модуле будут рассмотрены следующие темы.
- Обсуждение структуры данных, которая должна использоваться для хранения входных графов, предназначенных для использования и обработки в GraphLab.
- Демонстрация пути, который проходят входные графы через механизм GraphLab, от получения до генерации результатов.
- Определение архитектурной модели GraphLab.
- Представление модели программирования, используемой GraphLab, и механизмов согласованности, поддерживаемых для защиты общих данных от конфликтов чтения-записи или записи-записи.
- Обсуждение модели асинхронных вычислений, которая лежит в основе GraphLab.
- Изучение механизмов обеспечения отказоустойчивости в GraphLab.
Цели обучения
Изучив этот модуль, вы сможете:
- ознакомиться с уникальными возможностями GraphLab и вариантами применения, для которых эти возможности предназначены;
- вспомнить особенности платформы распределенного программирования с параллелизмом графов;
- вспомнить три основные составляющие механизма GraphLab;
- описать этапы, задействованные в механизме выполнения GraphLab;
- обсудить архитектурную модель GraphLab;
- вспомнить стратегию планирования GraphLab;
- описать модель программирования GraphLab;
- перечислить и обосновать уровни согласованности в GraphLab;
- описать стратегию размещения данных в памяти в GraphLab и ее влияние на производительность для определенных типов графов;
- обсудить вычислительную модель GraphLab;
- обсудить механизмы обеспечения отказоустойчивости в GraphLab;
- определить шаги, связанные с выполнением программы GraphLab;
- сравнить и сопоставить MapReduce, Spark и GraphLab в контексте их моделей программирования, вычислений, параллелизма, архитектуры и планирования;
- определить подходящий механизм аналитики с учетом характеристик приложения.
Необходимые компоненты
- Понимание темы облачных вычислений, в том числе знакомство с моделями и некоторыми поставщиками облачных служб.
- Знание технологий, лежащих в основе облачных вычислений.
- Представление о том, как поставщики облачных служб управляют оплатой и выставлением счетов за использование облака.
- Знание понятия центров обработки данных и их назначения.
- Знания в области настройки, поддержки и подготовки центров обработки данных.
- Представление о том, как подготавливаются и измеряются облачные ресурсы.
- Знакомство с понятием виртуализации.
- Знание различных типов виртуализации.
- Представление о виртуализации ЦП.
- Представление о виртуализации памяти.
- Представление о виртуализации ввода-вывода.
- Знания различных типов данных и об их хранении
- Знакомство с распределенными файловыми системами и принципами их работы.
- Знакомство с базами данных NoSQL и хранилищем объектов, а также с принципами их работы
- Представление о том, что такое распределенное программирование и почему оно подходит для облачной среды
- Представление о MapReduce и о том, каким образом эта модель позволяет выполнять вычисления с большими объемами данных
- Общие сведения о Spark и отличиях от MapReduce
Ссылки
- J. Gonzalez, Y. Low, H. Gu, D. Bickson, and C. Guestrin (October, 2012). PowerGraph: Distributed Graph-Parallel Computation on Natural Graphs In Proceedings of the 10th USENIX Conference on Operating Systems Design and Implementation