Модель программирования
Hadoop представляет MapReduce в качестве аналитического механизма. В его основе лежит распределенная файловая система Hadoop (HDFS)1. HDFS имитирует файловую систему Google (GFS)2 и разделяет входные наборы данных на фрагменты фиксированного размера (блоки), распределяя их по активным узлам кластера. По умолчанию каждый блок HDFS имеет размер 64 МБ и может быть настроен пользователями по-разному. Задания могут обрабатывать блоки HDFS параллельно на распределенных машинах, тем самым используя параллелизм, возможный благодаря секционированным наборам данных. MapReduce разделяет задания на несколько задач, обозначенных как задачи map и reduce. Все задачи map выполняются на так называемом этапе отображения, а задачи reduce — на этапе свертки. На этапе отображения может быть одна или несколько задач map, а на этапе свертки — ноль или несколько задач свертки. Если задание MapReduce не включает задачи reduce, оно называется "reduce-less"3.
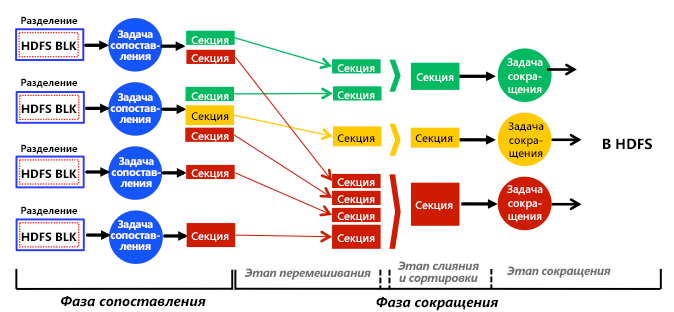
Рис. 1. Полное упрощенное представление этапов, этапов, задач, ввода данных, вывода данных и потока данных в подсистеме аналитики MapReduce
На этом рисунке показана полная, хотя и упрощенная схема подсистемы аналитики MapReduce. Задачи map работают с распределенными блоками HDFS, а задачи reduce — с выходными данными задач map, обозначенными как промежуточные выходные данные, или секции. Каждая задача map обрабатывает один или несколько отдельных блоков HDFS (подробнее об этом чуть ниже), а каждая задача reduce обрабатывает одну или несколько секций. В обычной программе MapReduce задача map, выполняемая во всех входных блоках HDFS, одинакова, и задача reduce, выполняемая для всех секций, также одинакова. Таким образом, в рамках определенного этапа отображения или свертки задания MapReduce могут рассматриваться в категории "одна программа — много данных" (SPMD).
Задачи map и reduce используют разные данные, работая независимо друг от друга и параллельно, только на соответствующих этапах. То есть задачи на одном этапе никогда не обмениваются данными (не отправляют и не получают сообщения), и единственная связь в MapReduce происходит явным образом (с помощью инфраструктуры MapReduce) между разными задачами на разных этапах. В частности, задачи map формируют новые секции на этапе отображения, и сам модуль Hadoop передает секции (по сети) задачам reduce на этапе свертки в процессе, именуемом перетасовыванием. Смысл такой стратегии заключается в том, что Hadoop не масштабировался бы до крупных кластеров (с сотнями или тысячами узлов), если бы задачам было разрешено взаимодействовать произвольно. Вместо этого все коммуникации происходят только между этапами отображения и свертки под полным контролем самого обработчика (а не задач). Поэтому типичная программа, выполняемая в варианте MapReduce, может рассматриваться как особый случай модели передачи сообщений. Задачи не имеют доступа к общей памяти, но полагаются на сообщения, передаваемые платформой между барьерами синхронизации map и reduce.
Ссылки
- HDFS Architecture Guide Hadoop
- S. Ghemawat, H. Gobioff, and S. T. Leung (Oct. 2003). The Google File System SOSP
- S. Chen and S. W. Schlosser (2008). MapReduce Meets Wider Varieties of Applications IRP-TR-08-05, Intel Research