Структура данных
Когда пользователь отправляет задание, связанные блоки данных HDFS загружаются и направляются в задачи map на этапе отображения (см. рис. 2). Каждая задача map обрабатывает один или несколько блоков HDFS, инкапсулированных в так называемый фрагмент. Фрагмент может содержать одну или несколько ссылок (не фактических данных) на один или несколько блоков HDFS. Размер фрагмента, то есть на какое количество блоков HDFS ссылается фрагмент, можно настроить. Каждая задача map всегда отвечает за обработку только одного фрагмента. Поэтому количество фрагментов определяет количество задач map в задании MapReduce, которое, в свою очередь, определяет общий параллелизм map. Если фрагмент указывает только на один блок HDFS, число задач map будет равным числу блоков HDFS1, 3. В целях локализации данных в Hadoop, как правило, каждый фрагмент вмещает только один блок HDFS. В частности, MapReduce пытается планировать задачи map рядом с входными фрагментами, чтобы сократить сетевой трафик и повысить производительность приложения. Таким образом, если фрагмент ссылается на несколько блоков, вероятность того, что эти блоки будут находиться на том же узле, где будет выполняться соответствующая задача map, становится низкой. Это приводит к передаче по сети, по крайней мере, одного блока (по умолчанию 64 МБ) для каждой задачи map. Однако при соотношении 1:1 между фрагментами и блоками задача map может выполняться на узле, где существует необходимый блок, и, следовательно, использовать локальность данных и сократить сетевой трафик.
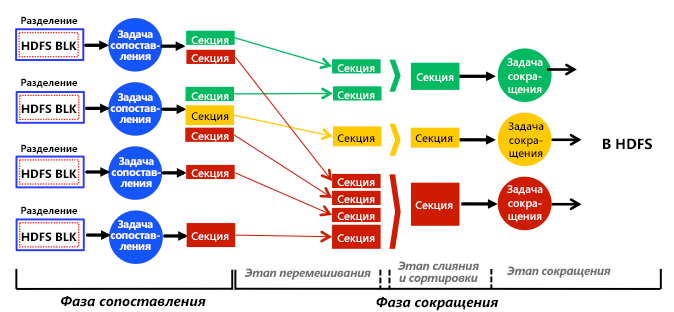
Рис. 2. Полное, упрощенное представление этапов, этапов, задач, ввода данных, вывода данных и потока данных в подсистеме аналитики MapReduce
При наличии этапа свертки задачи map хранят секции на локальных дисках (не в HDFS) и хэшируют их в назначенные задачи reduce. Каждая задача reduce собирает (перетасовывает) соответствующие секции с локальных дисков, выполняет слияние и сортировку, запускает определяемую пользователем функцию reduce и сохраняет окончательный результат в HDFS. Таким образом, этап свертки обычно разделяется на шаги перетасовывания, слияния и сортировки, а также свертки, как показано на рис. 2. В отсутствие этапа свертки задачи map записывают свои выходные данные непосредственно в HDFS. На рис. 2 показано, что задачи reduce могут получать разное количество секций разных размеров. Это явление называется отклонением секционирования1, 4 и влияет на планирование задач reduce.
На рис. 2 показано упрощенное представление того, что фактически делает механизм Hadoop MapReduce. Например, MapReduce перекрывает этапы map и reduce для повышения производительности. В частности, задачи reduce планируются только после определенного процента (по умолчанию — 5 %) завершения задач map, чтобы можно было постепенно начать перетасовывание их секций. В частности, шаги перетасовывания и слияния и сортировки выполняются одновременно, так что секции постоянно объединяются во время выборки. Причиной такой стратегии является чередование выполнения задач map и reduce, а также сокращение времени обработки заданий MapReduce. Такой прием обычно называется методом раннего перетасовывания2, 4.
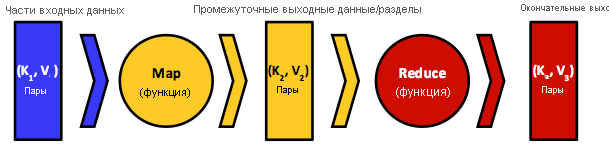
Рис. 3. Модель данных с ключевым значением, которая использует MapReduce, и входные данные и выходные данные для карты и сокращения функций
MapReduce создан на основе функциональных языков. Программисты пишут код в функциональном стиле, который состоит из последовательных функций map и reduce, передаваемых в качестве заданий в механизм MapReduce. Механизм преобразует задания в задачи map и reduce, а также распределяет и планирует их на участвующих узлах кластера2. Входные и выходные данные функций map и reduce всегда структурированы как пары "ключ-значение", а поток данных соответствует общему шаблону, показанному на рис. 3. Как правило, в map типы входных пар "ключ-значение", $K_{1}- V_{1}$, будут отличаться от типов выходных пар "ключ-значение" функции, $K_{2}$ и $V_{2}$. Однако типы входных пар "ключ-значение" в reduce, $K_{2}$ и $V_{2}$, должны совпадать с выходными данными функции map. Функция reduce допускает агрегирование значений, поэтому она обычно получает итератор (список) входных значений из нескольких задач map. Затем она применяет определяемую пользователем функцию reduce к этим значениям совокупно, при этом возвращая новые типы пар "ключ-значение", $K_{3}$ и $V_{3}$. Ключ из задачи map может передаваться только одной задаче reduce, а задача reduce может принимать и обрабатывать ключи из одной или нескольких задач map. Это свойство гарантировано механизмом MapReduce (в частности, функцией хэширования, используемой для секционирования выходных данных map). Наконец, к выходным данным функции map можно применить еще одну функцию — функцию объединения, которая действует так же, как функция reduce. В этом случае выходные данные функции объединения будут впоследствии формировать входные данные функции reduce.
Функцию объединения лучше проиллюстрировать на примере. Предположим, функция map анализирует файлы, представляющие прогнозируемую прибыль компании в течение следующих 5 лет, создавая пары "ключ-значение" в форме [$K_{2}$ = год, $V_{2}$ = расчетная прибыль (в млн долларов США)]. Допустим, несколько математических моделей формируют прогнозы (возможно, разные) для каждого конкретного года. Также предположим, что функция reduce получает выходные данные map и подсчитывает максимальную прибыль за указанный период. Допустим, две задачи map, $M_{1}$ и $M_{2}$, обрабатывают прогноз на 2015 год (который находится в двух разных фрагментах) и создают результаты {[2015, 29], [2015, 31]} ($M_{1}$) и {[2015, 23], [2015, 31], [2015, 28]} ($M_{2}$). Выходные данные $M_{1}$ и $M _{2}$ будут хэшированы и переданы в одну и ту же задачу reduce, а функция reduce будет вызываться с входными данными {[2015, 29], [2015, 31], [2015, 23], [2015, 31], [2015, 28]} и выдавать выходные данные [2015, 31], предоставляя максимальную прогнозируемую сумму. Однако если функция объединения также выдает максимальную прогнозируемую прибыль для выходных данных $M_{1}$ и $M_{2}$, только [2015, 31] и [2015, 31] будут передаваться в соответствующую задачу reduce из $M_{1}$ и $M_{2}$. Таким образом функция объединения уменьшит объем данных, передаваемых по сети, сохранит пропускную способность, доступную в кластере, и потенциально повысит производительность. Хотя это тактика работает для нашего примера вычислений, она может не подходить для других. Например, если бы нам нужно было вычислить среднюю прогнозируемую прибыль за годы, мы не смогли бы сделать это с помощью функции объединения, так как, в математическом смысле, среднее арифметическое из средних арифметических нескольких значений не всегда равно среднему значению всех (тех же самых) значений. Подходящие функции объединения должны быть коммутативными и ассоциативными функциями или распределенными функциями, как указано в сером цвете и сопоставлении, "Куб данных: реляционный оператор агрегирования generalizing Group by, Cross-tab и Sub-totals".5
1 Количество блоков HDFS в задании может быть вычислено путем деления размера набора данных задания на настраиваемый размер блока HDFS.
2 Каждая задача reduce обрабатывает одно или несколько значений, созданных одной или несколькими задачами map.
Ссылки
- S. Ibrahim, H. Jin, L. Lu, S. Wu, B. He, and L. Qi (Dec. 2010). LEEN: Locality/Fairness-Aware Key Partitioning for MapReduce in the Cloud CloudComm
- M. Hammoud and M. F. Sakr (2011). Locality-Aware Reduce Task Scheduling for MapReduce CloudCom
- HDFS Architecture Guide Hadoop
- M. Hammoud, M. S. Rehman, and M. F. Sakr (2012). Center-of-Gravity Reduce Task Scheduling to Lower MapReduce Network Traffic CLOUD
- J. Gray, S. Chaudhuri, A. Bosworth, A. Layman, D. Reichart, M. Venkatrao, and H. Pirahesh (1997). Data Cube: A Relational Aggregation Operator Generalizing Group-by, Cross-tab, and Sub-totals Data Mining and Knowledge Discovery