Вычислительные и архитектурные модели
На этом уроке мы рассмотрим вычислительную и архитектурную модель для MapReduce.
Вычислительная модель
Задания MapReduce, как и все распределенные программы, реализуют как синхронную, так и асинхронную модель вычислений. Во время каждого этапа и шага задачи MapReduce выполняют множество вычислений, зависящих от результатов предыдущего этапа или шага, и могут продолжать только после того, как эти данные поступают. Например, задача reduce не может начаться до того, как все необходимые секции поступят с шагов перетасовывания и слияния и сортировки. Более того, во время этапа задачи не взаимодействуют друг с другом. Взаимодействие происходит только в конце этапа или шага. Любая синхронная система должна гарантировать это свойство взаимодействия2, и MapReduce является хорошим примером этой вычислительной модели.
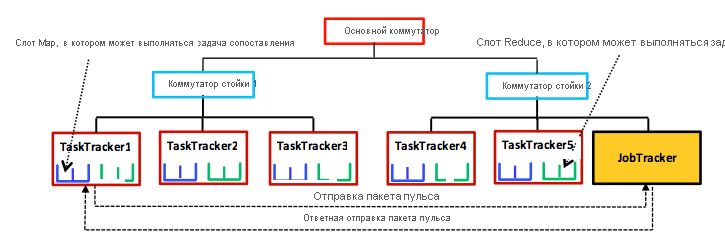
Рис. 4. Упрощенный пример архитектуры типа "главный — подчиненный", применяемой Hadoop MapReduce.
Архитектурная модель
Как показано на рисунке, MapReduce использует архитектуру типа "главный — подчиненный". Главный узел называется JobTracker (JT), а каждый подчиненный — TaskTracker (TT). JT и TT обмениваются данными через сеть кластера с помощью механизма периодических пакетов пульса. По умолчанию TT отправляют сообщения (пакеты пульса) в JT каждые три секунды, а JT отвечает6 новой задачей map или reduce или другим сообщением. JT использует эти пакеты пульса для обнаружения сбоев задач. Каждый TT по умолчанию имеет два слота map и два слота reduce, в которых могут выполняться соответствующие задачи. Такое выделение слотов определяет максимальное число задач map и reduce (степень параллелизма задач), которые могут выполняться одновременно в TT.
В Hadoop предполагается иерархическая топология сети в виде дерева с центральным и стоечными коммутаторами, как показано на рисунке. TT размещаются в разных стойках и могут находиться в одном или нескольких центрах обработки данных. Между любыми двумя TT пропускная способность соединения зависит от их относительного расположения в топологии сети. Например, TT в одной стойке могут взаимодействовать друг с другом гораздо быстрее, чем с TT в других стойках. Измерить пропускную способность между любыми двумя TT на практике сложно1, поэтому Hadoop использует простой подход на основе расстояния. Этот подход представляет позиции TT в сети в виде строк (т. е. расположение TaskTracker5 на рисунке — /CoreSwitch/RackSwitch1/TaskTracker5). В Hadoop считается расстояние между любым TT и его родительским коммутатором, поэтому общее расстояние между любыми двумя TT можно вычислить, просто сложив расстояния до ближайшего общего родительского элемента. В нашем примере
Total-Distance(/CoreSwitch/RackSwitch2/TaskTracker1, /CoreSwitch/RackSwitch2/JobTracker) = 4.
6 JT не отвечает на каждый пакет пульса, отправленный TT. TT могут отсылать пакеты пульса просто для того, чтобы указать, что они все еще активны. Если TT включает в свой пакет пульса запрос (например, запрос на задачу map или reduce), JT отвечает пакетом пульса, который удовлетворяет запрос TT (например, задача map или reduce).
Ссылки
- T. White (2011). Hadoop: The Definitive Guide 2nd Edition O'Reilly
- D. P. Bertsekas and J. N. Tsitsiklis (January 1, 1997). Parallel and Distributed Computation: Numerical Methods Athena Scientific, First Edition