YARN
В этом уроке мы рассмотрим Hadoop 2.0, известный как YARN.
Hadoop был существенно переделан для устранения нескольких технических недостатков, включая надежность и доступность JobTracker (JT) и выделение статического ресурса (слотов map и reduce) 10 в TaskTracker (TT). Переработанная платформа решает такие проблемы в JT, главном узле Hadoop, и, следовательно, единой точке отказа (SPOF). Еще одна основная цель нового Hadoop — поддержка других механизмов распределенной аналитики, помимо MapReduce. Это позволяет повысить эффективность использования кластеров Hadoop и устраняет необходимость развертывания большого кластера для каждой платформы. В случае с Hadoop результатом стала новая версия под названием Yet Another Resource Negotiator (YARN). Далее мы представим YARN и расскажем, чем он отличается от предыдущей версии Hadoop MapReduce, которую мы называем MapReduce 1.0.
YARN — это второе поколение Hadoop (версии 2.0 и выше). Основным преимуществом YARN по сравнению с предыдущим поколением Hadoop является то, что выделение ресурсов больше не является фиксированным, а YARN не привязан к единой платформе программирования. Это позволяет YARN функционировать как независимый планировщик кластера, который способен планировать различные рабочие нагрузки и приложения. YARN выполняет планирование в два этапа. Операции JobTracker из Hadoop v1 в YARN разделены на выделение ресурсов и управление задачами, что позволяет легко масштабировать кластеры YARN.
Архитектура и рабочий процесс
Главное изменение по сравнению с MapReduce 1.0 — разделение функций JT на несколько независимых управляющих программ, как показано на следующем рисунке. YARN по-прежнему использует топологию "главный — подчиненный" (также называемую "главный — ведомый"), но со следующими улучшениями:
- Для поддержки других распределенных механизмов аналитики в дополнение к MapReduce модуль управления ресурсами полностью отсоединен от JT и определен как отдельная сущность — диспетчер ресурсов (RM). Диспетчер ресурсов был также разделен на два основных компонента: планировщик (S) и диспетчер приложений (ASM).
- Вместо того чтобы использовать один главный узел, JT, для всех приложений, YARN назначает один главный узел на каждое приложение — главный узел приложения (AM). AM можно распределить между узлами кластера, чтобы избежать единой точки отказа для приложений и потенциального замедления.
- TT остаются без изменений, но теперь называются диспетчерами узлов (NM).

Рис. 8. Элементы архитектуры YARN: один RM, один ASM, один S, многие виртуальные машины и многие виртуальные машины
Компоненты YARN
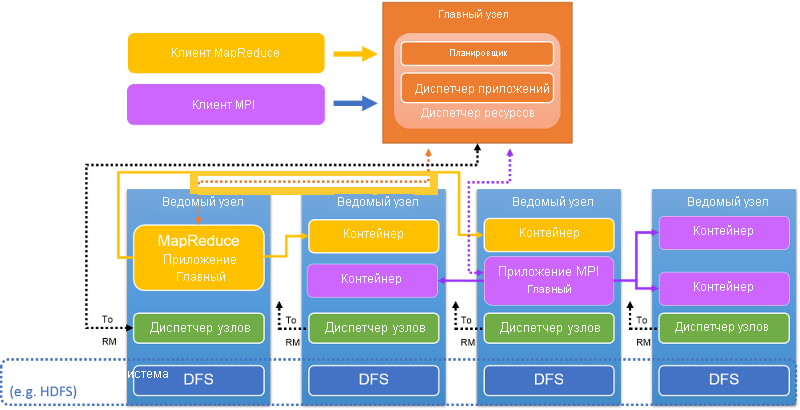
Рис. 9. Архитектура кластера YARN
Диспетчер ресурсов кластера размещается на главном узле (рис. 9). RM принимает отправку приложений и заданий клиентом, выделяет ресурсы для заданий, отслеживает состояние кластера и управляет доступом к ресурсам. RM имеет два компонента: планировщик, который планирует задание, и диспетчер приложений, который создает, отслеживает, перезапускает и завершает задания, а также управляет ими.
RM является центральным контролирующим элементом, который распределяет ресурсы между различными конкурирующими приложениями и заданиями. RM динамически выделяет ресурсы в аренду для приложений в форме контейнеров. Контейнеры — это логическое представление ресурсов в виде объема памяти или количества ЦП. В настоящее время RM обрабатывает емкость памяти и ресурсы ЦП, но пока не поддерживает ресурсы диска или сети. RM взаимодействует с диспетчерами узлов для сборки глобального представления кластера и применения назначений ресурсов. RM отслеживает использование ресурсов и активность узлов с помощью пакетов пульса.
Планировщик является частью RM и создает глобальный план для ресурсов кластера, обслуживает потребности в ресурсах для приложений и планирует задания с использованием таких стратегий, как справедливое планирование или планирование по емкости. Диспетчер приложений, еще одна часть RM, принимает отправленные задания, согласовывает с планировщиком инициализацию ресурсов (контейнер) для запуска главного узла задания и предоставляет службы для обеспечения отказоустойчивости и перезапуска AM при возникновении сбоев.
AM координирует выполнение приложения (или задания) в кластере YARN. Каждое задание, будь то задание MapReduce, MPI или Spark, имеет выделенный AM в кластере YARN. AM выполняется в обычном контейнере, как и другие задачи. AM отвечает за получение контейнеров и выделение им задач. Он рассчитывает набор ресурсов, необходимых для выполнения задач, и отправляет запрос к RM. После выделения ресурсов AM выполняет задачи в этих контейнерах. По завершении использования ресурсов AM возвращает их RM. Ниже мы подробно объясним этот процесс.
Когда AM выполняется в контейнере, он периодически отправляет пакеты пульса в RM, чтобы сообщить о своей активности и требуемых ресурсах. AM вычисляет объем ресурсов, требуемых для задания, и запрашивает контейнеры, указывая параметры и ограничения, в периодических пакетах пульса для RM. В свою очередь, RM динамически реагирует на пакет пульса и сдает в аренду контейнеры (в виде токенов). AM использует токены при обращении к соответствующему NM для запуска задач задания. AM отслеживает состояние выполняемых задач в непрерывном режиме. Во время выполнения задания RM не следит за расписанием AM. Для задания MapReduce AM подобен JobTracker в Hadoop версии 1.0.
Диспетчер узла находится на каждом узле. У каждого узла кластера YARN есть один NM. NM проверяет подлинность аренды контейнеров и отслеживает использование ресурсов. NM обращается к RM через пакеты пульса и завершает контейнеры по указанию RM или AM.
Контейнер представляет арендованный выделенный ресурс в кластере. Арендованный ресурс — это логический пакет ресурсов, привязанный к узлу. RM — это единственный центр, выделяющий контейнеры для заданий. Каждый выделенный контейнер имеет глобально уникальный идентификатор ContainerID. Каждый контейнер имеет ряд нестатических атрибутов: ЦП, память, диск BW, сеть BW. Контейнеры можно сравнить со слотами MapReduce в Hadoop версии 1.0. После завершения задачи, выполняемой в нем, контейнер будет завершен. RM отзывает ресурсы и использует их позже.
Если AM нужны вычислительные ресурсы, он отправляет планировщику RM ряд запросов на контейнеры. Планировщик понимает протокол <priority, (host, rack, *), resources, #containers>. Планировщик RM назначает или выделяет контейнеры в том же формате. Моментальный снимок из журнала RM показывает, как RM выделяет контейнер (рис. 10):

Рис. 10. Моментальный снимок журнала назначения контейнера в YARN. Важные сведения в этой записи: 1. ContainerID. 2. Вычислительные ресурсы в этом ContainerID. 3. Идентификатор узла, на котором размещается ContainerID. 4. Отчет о ресурсах этого узла после выделения.
Планирование заданий и задач
YARN выполняет планирование в два этапа. RM планирует задания, а AM планирует его задачи в контейнерах, выделенных диспетчером RM. Планировщик, отвечающий за планирование заданий в RM, использует разные стратегии планирования:
- Планировщик FIFO: это базовый и простой планировщик, имеющий одну очередь первого входа и планирующий запросы контейнеров на основе этого. Как правило, задание может занимать ресурсы в пределах кластера во время работы. Хотя каждому заданию можно предложить много ресурсов, это создает проблемы, такие как нехватка ресурсов для других заданий или несправедливое распределение ресурсов. Планировщик FIFO позволяет задавать приоритеты заданий, чтобы сначала выполнялись задания с наивысшим приоритетом. Однако поскольку планировщик FIFO не поддерживает вытеснение, проблема с нехваткой ресурсов сохраняется. Задание с высоким приоритетом может быть заблокировано длительным заданием с низким приоритетом.
- Планировщик емкости. В этом планировщике предполагается, что задания Hadoop выполняются в общем кластере с несколькими клиентами и максимизирует пропускную способность и использование кластера. Capacity Scheduler предоставляет гарантированную емкость пользователям, совместно использующим большой кластер. Capacity Scheduler организует задания в очереди. Как правило, очереди настраиваются администраторами в зависимости от того, как кластер YARN будет секционирован и использован различными группами пользователей (группа 1, очередь 1 получает 50 % кластера). Capacity Scheduler предоставляет набор ограничений, позволяющих гарантировать, что одно задание или очередь не смогут использовать непропорциональное количество ресурсов в кластере.
- Справедливый планировщик: этот планировщик фокусируется на выполнении различных заданий YARN справедливо, предоставляя задания с равным количеством ресурсов с течением времени. По умолчанию Fair Scheduler принимает решения о планировании только на основе памяти. Однако Fair Scheduler можно настроить для планирования по памяти и ЦП. Fair Scheduler гарантирует, что короткие задания будут выполняться быстрее, не отнимая ресурсы у крупных и длительных заданий. Он также является предпочтительным вариантом в случае, если несколько пользователей совместно используют один и тот же кластер. Помимо равномерного выделения ресурсов Fair Scheduler может планировать задания с разными приоритетами. Приоритеты, заданные пользователями, можно использовать для определения того, сколько ресурсов должно быть назначено каждому заданию.
- Планировщик: пользователи могут подключаться к своему планировщику заданий.
Стратегии планирования можно настроить в файле yarn-site.xml. Также существует множество свойств, которые можно задать в yarn-site.xml для настройки рабочих параметров описанных планировщиков.
После выделения заданию ресурсов (контейнеров) AM будет планировать задачи задания в этих контейнерах. AM планирует задачи так же, как JobTracker в Hadoop версии 1.0. Кроме того, AM отвечает за наблюдение за состоянием задач, как это делает TaskTracker в Hadoop версии 1.0.
Отказоустойчивость в YARN
Диспетчер ресурсов представляет собой единую точку отказа для кластера YARN. RM периодически создает контрольные точки своего состояния в постоянном хранилище. Если RM завершается сбоем, его можно перезапустить из одной из контрольных точек. После этого все запущенные AM будут завершены и перезапущены, а приложения и задачи, которые ожидают состояния контрольной точки, могут быть запланированы и выполнены.
Любой AM подвержен сбоям. RM заметит, что AM не отправляет пакет пульса, и перезапустит его. Однако AM необходимо повторно синхронизировать со всеми работающими контейнерами, чтобы гарантировать корректное выполнение задания.
RM также может обнаруживать сбои NM. При сбое NM все контейнеры на этом узле будут завершены, а о сбое будут уведомлены все выполняющиеся AM. AM должны получить новые ресурсы в виде контейнеров от RM для выполнения завершенных задач. Контейнеры не будут назначаться на узле со сбоем в кластере, пока он не восстановится и не сообщит об этом RM.
Поток заданий для MapReduce в YARN
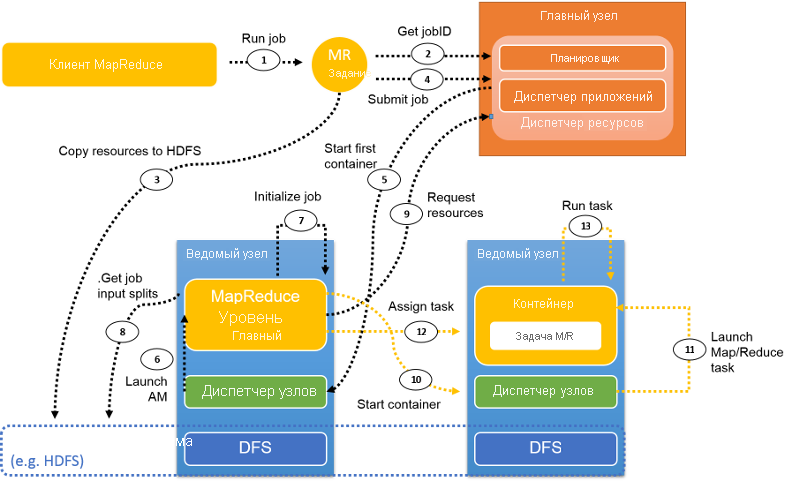
Рис. 11. Поток заданий в YARN, выполняющий задание MapReduce
На этом рисунке показан типичный поток заданий MapReduce в YARN. В следующих разделах описаны шаги этого потока.
Отправка задания
Шаг 1. Клиент MapReduce использует тот же API, что и Hadoop версии 1.0, для отправки задания в YARN. Если для параметра mapreduce.framework.name задано значение yarn в конфигурации задания, активируется ClientProtocol YARN. Задание в YARN называется приложением.
Шаг 2. В отличие от версии Hadoop 1.0, где JobTracker управляет всеми заданиями в кластере, в YARN из RM извлекается новый идентификатор задания. Однако иногда jobID в YARN также называется applicationID.
Шаг 3. Необходимые ресурсы задания, такие как JAR-файл задания, файлы конфигурации и сведения о фрагментах, копируются в общую файловую систему в процессе подготовки к запуску задания.
Шаг 4. Клиент задания вызывает submitApplication() в RM для отправки задания.
Инициализация задания
Шаг 5. RM передаст запрос задания планировщику после получения вызова submitApplication(). Планировщик выделяет ресурсы для запуска контейнера, в котором будет размещен главный узел приложения (AM). Затем RM отправляет арендованные ресурсы диспетчеру узла.
Шаг 6. NM получает сообщение от RM и запускает контейнер для AM.
Шаг 7. AM инициализирует задание. Для мониторинга задания создается несколько объектов учета. Затем, пока задание выполняется, AM получает сведения о ходе выполнения его задач.
Шаг 8. AM взаимодействует с общей файловой системой (например, HDFS) для получения данных о входных фрагментах и другой информации, которая была скопирована в общую файловую систему на шаге 3.
Назначение задач
Шаг 9. AM вычисляет количество задач map, которое определяется числом входных фрагментов (аналогично Hadoop версии 1.0). Число задач reduce — это настраиваемый параметр, который можно задать в файле конфигурации. AM запрашивает ресурсы для всех задач map и reduce у RM в форме запроса на контейнеры. Запрос включает в себя такие параметры, как расположение данных (для задач map), объем памяти и количество ЦП в каждом контейнере.
ResourceRequest: <Priority: 20,
Resource: <vCores: 1, memory: 1024>,
Num Containers: 2,
Desired Host: 192.1.1.1,
Relax Locality: true>
В приведенном выше примере priority определяет приоритет контейнера, который можно настроить в зависимости от типа задачи (например, map или reduce). Ресурсы, необходимые для этой задачи, обозначаются как подчиненная запись с именем Resource. Здесь число vCores (ЦП) обозначается как 1, а memory — целочисленный параметр, определенный в МБ. Num containers обозначает количество таких контейнеров, которое требуется для YARN. Desired host обозначает требования к расположению в запросе. Relax locality обозначает, является ли определенное требование к расположению строгим или для этой задачи допускаются другие расположения.
Шаг 10 и Шаг 11. После того как RM отвечает, выдав контейнеры в аренду, AM обращается к NM, и NM запускают контейнеры.
Шаг 12. AM назначает задачу этому контейнеру на основе знаний о расположении. Задача будет выполнена приложением Java, основной класс которого — YarnChild.
Отчеты о состоянии
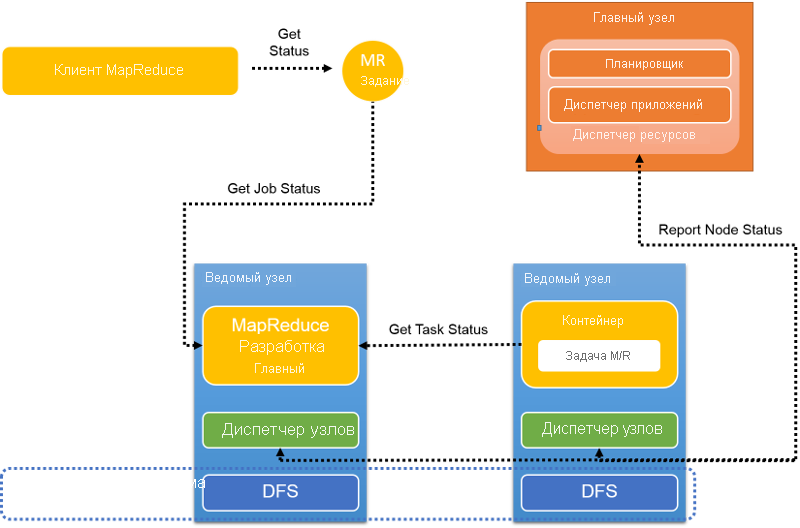
Рис. 12. Отчеты о пульсе и состоянии в YARN
Во время выполнения задания задачи отправляют отчеты о ходе выполнения и состоянии соответствующему AM, поэтому у AM есть обобщенное представление о задании (рис. 12). Диспетчеры узлов сообщают об активности и использовании ресурсов в RM, который имеет глобальное представление о кластере.
Завершение задания
Каждые пять секунд клиент задания проверяет состояние задания, чтобы узнать, завершилось ли оно. Вызываемая функция — waitForCompletion(). После завершения задания вызывается метод очистки. Все контейнеры и рабочее состояние AM будут очищены. Сервер журнала заданий отслеживает сведения, связанные с этим заданием.
Пример: WordCount
Здесь представлен пример использования WordCount в кластере YARN, состоящем из 1 главного узла и 4 подчиненных узлов. Мы используем экземпляр m1.large (2 виртуальных ЦП, 6,5 ECU, 7,5 ГБ памяти) в Amazon Web Services (AWS). Входные данные секционированы как 39 обычных текстовых файлов в распределенной файловой системе с общим размером 2,32 ГБ. Число задач map рассчитано как 39, и мы вручную настроим 7 задач reduce в файле конфигурации.
Мы используем моментальные снимки для подробного описания процесса выполнения этого задания в YARN:
Клиент запускает задание WordCount.
RM назначает
jobIDдля этого задания WordCount.Сведения об этом задании WordCount сохраняются или копируются в HDFS.
Задание WordCount отправляется в RM (рис. 13).
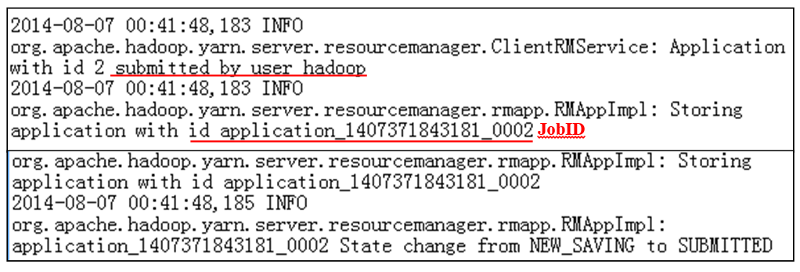
Рис. 13. Журнал отправки заданий
RM взаимодействует с NM, чтобы выделить контейнер для AM.
NM проверяет подлинность контейнеров, которые RM выдал в аренду.
RM успешно запускает AM для задания WordCount (рис. 14).
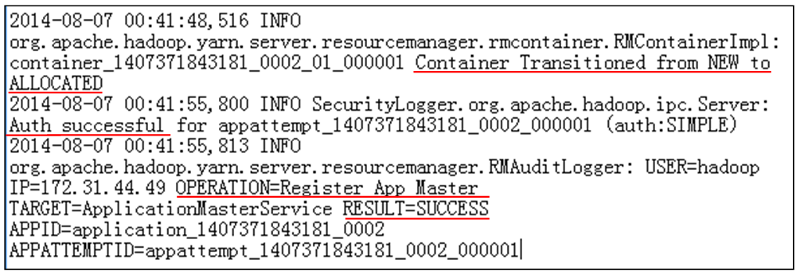
Рис. 14. Журнал выделения заданий
Am запускается, и он вычисляет ресурсы, необходимые для завершения задания WordCount: 39 задач карты и 7 задач сокращения.
RM получает запросы от AM и выделяет ресурсы в виде контейнеров.
AM отправляет арендованные ресурсы NM, и контейнеры запускаются.
AM запускает задачи map, готовые к выполнению в контейнерах. В нашем случае AM в первую очередь запускает 12 попыток выполнить задачу map, так как на кластере с 4 узлами недостаточно ресурсов для другого контейнера.
Затем AM назначает контейнеры для попыток выполнения задач map на основе знаний о расположении данных (рис. 15).

Рис. 15. Журнал назначений заданий
Задачи map начинают выполняться. AM отслеживает состояние каждой попытки выполнения задачи с помощью пакетов пульса.
В какой-то момент задача map завершает выполнение в контейнере, и об этом сообщается AM.
Затем этот контейнер очищается с помощью AM. Вычислительные ресурсы извлекаются, а NM запускает новый контейнер с помощью процесса, описанного выше. AM назначает новую попытку выполнения задачи map или reduce в новом контейнере. В одном контейнере может выполняться только одна задача.
Из-за раннего перетасовывания после выполнения нескольких задач map (по умолчанию — по крайней мере, 5 %) AM назначает попытку выполнения задачи reduce в доступном контейнере. Этап свертки состоит из перетасовывания, слияния и сортировки и выполнения функции reduce. Только после того, как выходные байты задачи reduce будут записаны в HDFS, задача reduce может завершиться.
AM управляет всеми задачами map и reduce и ждет их завершения. После завершения последней задачи reduce все задание будет отмечено как завершенное.
AM обменивается данными с NM для очистки всех оставшихся контейнеров.
AM уведомляет RM о завершении задания.
RM очищает AM. Все задание WordCount завершается (рис. 16).

Рис. 16. Журнал очистки заданий
Временная шкала задач для примера задания WordCount
Вскоре после начала задания запускается 12 задач map (синие полосы) (рис. 17). Больше задач map запустить невозможно, так как в кластере нет доступных ресурсов (контейнеров). Мы будем называть несколько задач map, выполняющихся параллельно, волной. Итак, в первой волне 12 задач map. Через какое-то время некоторые задачи map завершаются. Из-за раннего перетасовывания по завершении некоторых задач map (по умолчанию — 5 %) будут запланированы задачи reduce и начнется перетасовывание. В этом примере имеется достаточно ресурсов для запуска 4 задач reduce. Каждая задача reduce состоит из трех последовательных шагов: перетасовывание (красный), слияние и сортировка (желтый) и функция reduce (розовый). Пока 4 задачи reduce выполняют раннее перетасовывание, начинается выполнение второй волны задач map. По завершении последней задачи map завершается весь этап отображения. Затем можно запустить слияние и сортировку и функции reduce. У нас есть достаточно контейнеров для выполнения 3 задач reduce. Задание вскоре завершается после выполнения последней задачи reduce.
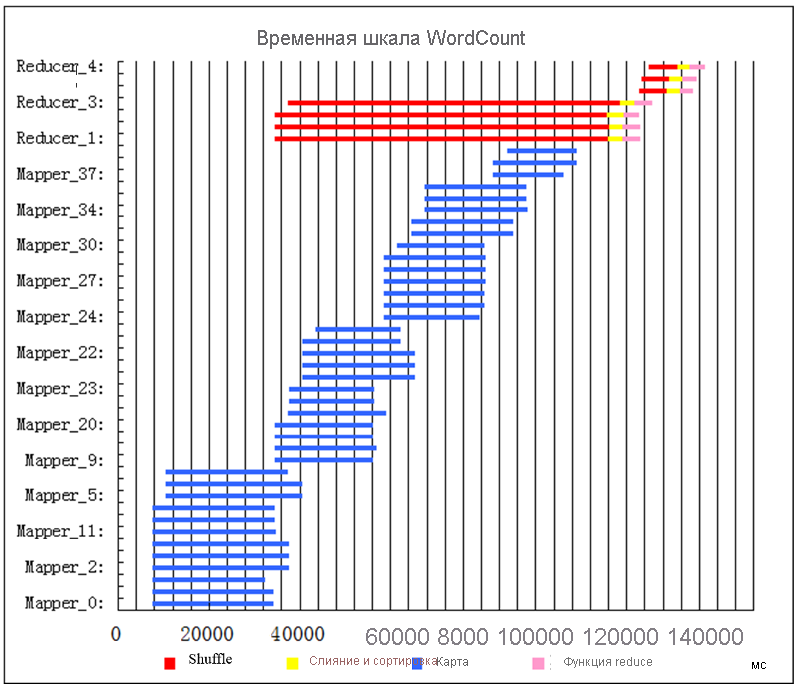
Рис. 17. Выполнение задания временная шкала для WordCount
10 Число слотов map и число слотов reduce — это настраиваемые параметры, которые пользователи могут задать перед отправкой заданий в Hadoop MapReduce.