Отказоустойчивые распределенные наборы данных
В основе Spark лежит особая абстракция, которая называется отказоустойчивыми распределенными наборами данных (RDD)1. RDD — это объекты в памяти, доступные только для чтения и секционированные по кластеру. Они позволяют пользователям управлять параметрами хранения и секционирования и, таким образом, оптимизировать размещение данных и обработку этих данных с использованием обширного набора операторов. RDD разделяются между компьютерами на основе либо диапазона (секционирования последовательных записей), либо хэша ключа в каждой записи. Каждый метод секционирования оптимален для конкретного варианта использования. (Секционирование хэша ускоряет объединение, поскольку позволяет размещать записи из разных наборов данных с общими ключами. Секционирование диапазона ускоряет доступ к небольшому отфильтрованному подмножеству данных.)
Несмотря на отсутствие необходимости физического существования в физическом хранилище, RDD могут быть отказоустойчивыми. При этом их не нужно реплицировать. Вместо этого они используют журнал преобразований, с помощью которого "запоминают" набор уже выполненных операций, чтобы потом их можно было воссоздать и перестроить в случае потери данных. Маркер RDD содержит достаточно информации для выполнения повторных вычислений из версии данных, хранящейся на диске.
Вся работа в Spark представляет собой создание новых RDD, преобразование существующих RDD или выполнение операций в RDD. Про RDD необходимо понимать, что они представляют собой отложенные вычисления и имеют временный характер. Отложенные вычисления — это оптимизация, при которой выполняется конвейерная обработка множества преобразований, а RDD вычисляется только при первом использовании с действием. Временный характер означает, что RDD может материализоваться (вычисляться и загружаться в память) при использовании в параллельном приложении, но впоследствии он удаляется из памяти.
| Аспект | RDD | Распределенная общая память |
|---|---|---|
| Чтение | Грубые и детальные | Детальные |
| Запись | Грубые | Детальные |
| Согласованность | Стандартная (постоянная) | В зависимости от приложения или среды выполнения |
| Восстановление после сбоя | Детальность и небольшие затраты за счет использования журнала преобразований | Требуются контрольные точки и откат программ |
| Предотвращение отстающих задач | Возможно за счет использования задач резервного копирования | Сложно |
| Размещение работы | Автоматически в зависимости от местонахождения данных | В зависимости от приложения (среды выполнения стремятся к прозрачности) |
| Поведение при нехватке ОЗУ | Как в других потокоориентированных системах | Низкая производительность (переключение) |
Абстракция RDD — это тип системы распределенных общих коллекций, аналогичный традиционным системам распределенной общей памяти (DSM)2. Интересно сравнить две абстракции.
В отличие от DSM, которая позволяет считывать и записывать данные в отдельные участки памяти, Spark позволяет выполнять только грубые преобразования RDD. Кроме того, RDD поддерживает механизм восстановления с небольшими затратами за счет использования журнала преобразований, в то время как системы DSM требуют скоординированных контрольных точек3. Как в MapReduce, для избавления от отстающих задач можно использовать упреждающее исполнение медленных задач.
Далее рассмотрим жизненный цикл RDD.
Создание RDD
По умолчанию в модели программирования Spark RDD представляется в виде объекта Scala (но также может быть объектом Python или Java). Создавать RDD можно несколькими способами:
- Из файла в распределенной файловой системе, такой как HDFS
- Путем параллелизации коллекции или массива и их распределения между несколькими узлами
- За счет преобразования существующего RDD (операции преобразования рассматриваются ниже).
- Изменив уровень сохраняемости существующего RDD с помощью одного из двух действий:
- кэш: подсказки для платформы для сохранения RDD в памяти после первого вычисления, чтобы обеспечить повторное использование
- сохранение: записывает данные в распределенную файловую систему, например HDFS
В следующих примерах показано, как создавать RDD. Эти команды можно использовать в оболочке Spark Scala.
Загрузка текстового файла
Используйте метод Python textFile(), чтобы загрузить текстовый файл server.logs в строку RDD:
log_lines_RDD = sc.textFile("server.logs")
Параллелизация существующего RDD
Используйте метод Python parallelize(), чтобы параллелизовать существующий RDD:
greeting_lines_RDD = sc.parallelize(["hello", "world"])
Операции с RDD
Созданный RDD поддерживает два типа операций, как показано на следующем рисунке.
- Преобразования: операции, создающие новые удаленные удаленные диски из существующих
- Действия. Вычисления на RDD, возвращающие один объект драйверу
Как уже говорилось, преобразования Spark по умолчанию являются отложенными. Это значит, что они не вычисляются сразу; вместо этого они объединяются в пакеты и выполняются только при выполнении действия. Выполнение действия вызывает материализацию всех RDD в журнале преобразований. Однако после того, как вычисление будет выполнено, RDD сохранится только в том случае, если этого явно требует программа.
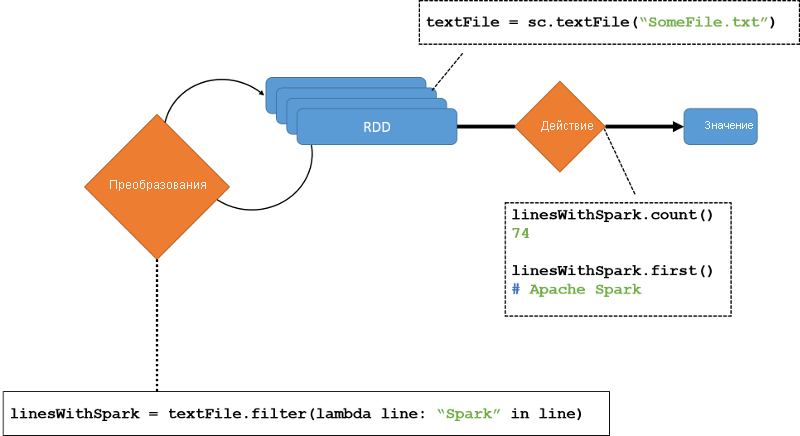
Рис. 3. Операции с устойчивыми распределенными наборами данных (RDD)
Примеры преобразований и действий:
| Преобразование | Description | Действие | Значение |
|---|---|---|---|
map(func) |
Возвращает новый RDD, сформированный путем передачи каждого элемента источника через функцию func. |
reduce(func) |
Агрегирует элементы набора данных с помощью функции func, которая принимает два аргумента и возвращает один. Функция должна быть ассоциативной — это необходимо для правильного параллельного вычисления. |
filter(func) |
Возвращает новый RDD, выбирая те элементы источника, для которых func возвращает true. |
collect() |
Возвращает все элементы RDD в виде массива в программе-драйвере. Это преобразование удобно использовать после фильтра или другой операции, возвращающей достаточно небольшое подмножество данных. |
join(otherDataset, [numTasks]) |
При вызове для двух RDD — типа (K, V) и (K, W) — преобразование возвращает RDD пар (K, (V, W)) со всеми парами элементов для каждого ключа. |
count() |
Возвращает количество элементов в RDD. |
Мы обсудим их более подробно в одном из следующих уроков, где рассмотрим несколько примеров программ. А сейчас разберем несколько простых примеров, чтобы понять основные операции, которые можно выполнять в RDD.
Преобразования
Следующий код Python фильтрует log_lines_RDD для поиска атак на веб-сервер, выполняя поиск строк, совпадающих с определенной строкой подписи.
log_lines_RDD = sc.textFile("server.logs")
xss_RDD = log_lines_RDD.filter(lambda x: "%3C%73%63%72%69%70%74%3E" in x)
sqli_RDD = log_lines_RDD.filter(lambda x: "bobby_tables" in x)
owasp_attacks_RDD = xss_RDD.union(sqli_RDD)
Метод filter() не изменяет исходный RDD. Вместо этого мы получаем два новых RDD. При этом log_lines_RDD можно будет использовать повторно. Метод union() — это преобразование, которое работает с двумя RDD и создает из них объединенный owasp_attacks_RDD.
Действия
Следующий код Python подсчитывает количество атак в объединенном owasp_attacks_RDD. Действие вызывает принудительную материализацию. Во многих случаях examplesRDD.count() используется для принудительной материализации во время локального тестирования кода Spark.
log_lines_RDD = sc.textFile("server.logs")
xss_RDD = log_lines_RDD.filter(lambda x: "%3C%73%63%72%69%70%74%3E" in x)
sqli_RDD = log_lines_RDD.filter(lambda x: "bobby_tables" in x)
owasp_attacks_RDD = xss_RDD.union(sqli_RDD)
print("Number of attacks:" + owasp_lines_RDD.count())
Очевидно, что RDD лучше всего подходят для пакетных операций, в которых одни и те же операции применяются ко всем элементам набора данных. Приложениям, требующим асинхронных, детализированных обновлений, требуются более специализированные системы. Поскольку они неизменяемы, вычисление новых RDD для каждого дополнительного входного элемента потребует больших затрат. Таким образом, даже при работе с входными данными в режиме реального времени Spark часто передает эти изменения в виде пакетов за короткие периоды времени.
Сохранение RDD
RDD можно сохранять четырьмя способами4:
- В памяти как десериализированные объекты: десериализированный объект выражает структуру данных в виде набора байтов. Хранение необработанных объектов RDD в памяти дает наибольшую производительность, поскольку платформа может обращаться к элементам в собственном коде. Однако есть и издержки, поскольку, помимо данных, сохраняются и метаданные объекта. Например, объекты Java легкодоступны, но занимают в 2–5 раз больше места, чем необработанные данные, которые в них находятся.
- В памяти как сериализованные данные: сериализуя RDD, связанные данные хранятся в четко определенном формате. Этот метод работает медленнее, чем хранение десериализованных объектов, но занимает меньше памяти, чем хранение графов объектов.
- Хранилище на диске: этот метод помогает хранить действительно большие удаленные диски удаленных рабочих дисков, которые не помещаются в память, но это не должно быть постоянно перекомпилировано.
- Хранилище вне кучи: хранилище вне кучи предоставляется специальной системой хранения, ориентированной на память под названием Tachyon,4, которая обеспечивает надежный обмен данными на уровне кластера со скоростью памяти.
Во всех четырех случаях RDD хранится по разделам во всех рабочих ролях. Каждый раздел является мельчайшей частью набора данных. При нехватке памяти из-за высокой скорости поступления данных разделами RDD в памяти обычно разбирается политика вытеснения LRU. Однако если какой-то раздел недавно использовался и относится к тому же RDD, что и вновь прибывший раздел, он не будет вытесняться, чтобы не допустить пробуксовки.
По умолчанию RDD пересчитываются вместе с каждым выполняемым с ними действием. Чтобы использовать RDD в разных действиях, можно вызвать метод RDD persist(). RDD можно сохранять в разных местах, как показано в следующей таблице.
| Уровень | Занимаемое место | Время ЦП | В памяти | На диске | Комментарии |
|---|---|---|---|---|---|
MEMORY_ONLY |
Высокая | Низкая | Y | N | |
MEMORY_ONLY_SER |
Низкий | Высокий | Y | N | |
MEMORY_AND_DISK |
Высокий | Средний | Частично | Частично | Если памяти не хватает для размещения данных, переходит на диск. |
MEMORY_AND_DISK_SER |
Низкий | Высокий | Частично | Частично | Если памяти не хватает для размещения данных, переходит на диск. Хранит сериализованное представление в памяти. |
DISK_ONLY |
Низкий | Высокий | N | Y |
Spark также позволяет сохранять данные в кэше всего кластера в памяти. Этот метод может повысить производительность при частом доступе к данным (например, при использовании небольшого "горячего" набора данных или выполнении итеративного алгоритма). RDD также включают метод unpersist(), который позволяет удалять их из постоянного хранилища.
Конечно, чтобы получить все эти свойства с помощью RDD, мы также должны выбрать подходящее представление для их хранения. Любое представление должно иметь возможность отслеживать журнал преобразований в широком диапазоне преобразований, которые пользователи могут комбинировать произвольным образом. Spark использует для RDD простое представление на основе графов. Доступ к каждому RDD осуществляется через общий интерфейс, в котором предлагаются пять функций: набор разделов (атомарные фрагменты набора данных), набор зависимостей (в родительском RDD), функция для вычисления набора данных на основе его родительских объектов, метаданные средства секционирования и список предпочтительных узлов, доступ к каждому разделу которых может осуществляться быстрее из-за местонахождения.
| Операция | Значение |
|---|---|
partitions() |
Возвращает список объектов разделов. |
preferredLocations(p) |
Выдает список узлов с более быстрым доступом к разделу p из-за местонахождения данных. |
dependencies() |
Возвращает список зависимостей. |
iterator(p, parentIters) |
Вычисляет элементы раздела p с учетом итераторов для его родительских разделов. |
partitioner() |
Возвращает метаданные, указывающие, секционирован ли RDD по хэшу или по диапазону. |
Допустим, наш входной набор данных состоит из файлов в HDFS. По умолчанию partitions() возвращает список для каждого блока HDFS, занимаемого этим файлом. Каждый объект раздела в этом списке представлен смещением блока. Поскольку речь идет о системе HDFS, preferredLocations(p) возвращает список узлов, в которых хранится локальная копия блока. Операция iterator(p, parentIters) просто считывает блок.
Итак, мы рассмотрели RDD и некоторые основные операции с RDD. На следующих страницах мы рассмотрим более подробные примеры, чтобы понять, как RDD помогает Spark добиваться высокой производительности для многих типов приложений и как они обеспечивают отказоустойчивость и восстановление.
Ссылки
- Zaharia, Matei and Chowdhury, Mosharaf and Das, Tathagata and Dave, Ankur and Ma, Justin and McCauley, Murphy and Franklin, Michael J and Shenker, Scott and Stoica, Ion (2012). Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation
- Janakiraman, G and Tamir, Yuval (1994). Coordinated checkpointing-rollback error recovery for distributed shared memory multicomputers Proceedings of IEEE 13th Symposium on Reliable Distributed Systems
- Zaharia, Matei and Holden Karau, Konwinski Andy and Wendell, Patrick (2015). Learning Spark: Lightning-Fast Big Data Analytics O'Reilly Media
- Li, Haoyuan and Ghodsi, Ali and Zaharia, Matei and Shenker, Scott and Stoica, Ion (2014). Tachyon: Reliable, memory speed storage for cluster computing frameworks Proceedings of the ACM Symposium on Cloud Computing