Журнал преобразований, отказоустойчивость и восстановление
В больших распределенных кластерах, выполняющих длительные задания на недорогом стандартном оборудовании, очень важно иметь отказоустойчивую платформу на случай возникновения ошибок. В отличие от платформы Hadoop, где большое внимание уделяется быстрому восстановлению после отказов за счет репликации данных, хранящихся в HDFS, и отстающих задач, Spark использует для восстановления после ошибок абстрактную концепцию журнала преобразований. Журнал преобразований — это направленный ациклический граф, определяющий операции, необходимые для создания RDD1.
Давайте рассмотрим программу из предыдущего урока, в котором рассказывалось, как описать преобразование RDD:
log_lines_RDD = sc.textFile("server.logs")
xss_RDD = log_lines_RDD.filter(lambda x: "%3C%73%63%72%69%70%74%3E" in x)
sqli_RDD = log_lines_RDD.filter(lambda x: "bobby_tables" in x)
owasp_attacks_RDD = xss_RDD.union(sqli_RDD)
Поскольку RDD создаются друг из друга с использованием преобразований, Spark отслеживает зависимости с помощью графа преобразований. Это позволяет вычислять RDD в пассивном режиме (как уже объяснялось ранее) и предоставляет платформе информацию по восстановлению после отказов. Журнал преобразований для фрагмента кода показан на следующем рисунке:
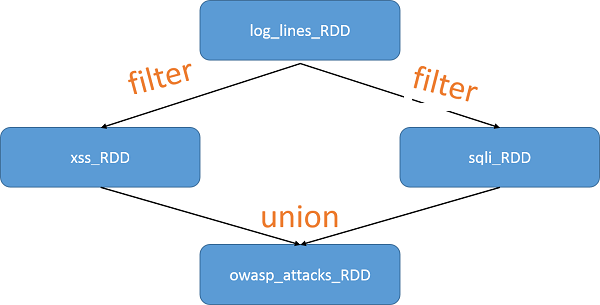
Рис. 4. График происхождения RDD
Поскольку RDD неизменяемы, определять такие графы очень просто. Обратите внимание, что на графике выше не было материализовано RDD и вычисления были фактически выполнены. Это происходит в следующей строке кода, которая является первым действием в программе:
print "Number of attacks:" + owasp_lines_RDD.count()
Поскольку ни один из RDD не сохраняется, в этот момент в памяти хранятся только owasp_lines_RDD. Поскольку отказоустойчивость достигается за счет структур данных в памяти, Spark фокусируется на уменьшении затрат, которые могут потребоваться для обеспечения отказоустойчивости из-за дублирования операций записи в HDFS. Сохраняя RDD в памяти и вычисляя потерянные разделы заново, Spark избегает высокой стоимости методов обеспечения отказоустойчивости, которые используются в платформе Hadoop, включая репликацию и последующий ввод/вывод данных на диск. С другой стороны, Hadoop предлагает значительно более быстрое восстановление после отказов, поскольку просто переключается на одну из других реплик.
Зависимости
Одна из интересных задач, стоявших перед разработчиками Spark, заключалась в обеспечении подходящего способа представления зависимостей между RDD. Они разделили зависимости на два типа:
- Узкие зависимости: каждая секция родительского RDD используется по крайней мере одной секцией дочернего RDD.
- Широкие зависимости: несколько секций дочернего RDD используют каждую секцию родительского RDD.
Рассмотрим преобразование map(func), которое возвращает новый распределенный набор данных, сформированный путем передачи каждого элемента источника через функцию func. Здесь у дочернего RDD есть узкая зависимость от родительского, так как каждый раздел родительского RDD возвращает один раздел дочернего. По сути, при вызове функции map(func) в RDD преобразование возвращает объект MappedRDD. Он содержит те же разделы и preferredLocations, что и исходный (родительский) RDD, но дополнительно применяет func к записи родительского RDD в методе итератора.
С другой стороны, существует преобразование join(), которое при вызове для двух RDD — типа (K, V) и (K, W) — возвращает RDD пар (K, (V, W)) со всеми парами элементов для каждого ключа. Если родительские RDD секционированы с использованием одного и того же разделителя диапазона или хэша, это можно представить в виде двух узких зависимостей. Если ни один из RDD не имеет определенного раздела, значит, зависимость широкая. Наконец, если один родительский RDD имеет модуль разделения, а другой — нет, зависимость считается смешанной. Во всех трех случаях выходной RDD имеет разделитель. Разделитель может быть унаследован от родителей или установлен по умолчанию (разделитель хэша).
Обе зависимости показаны на следующем рисунке:
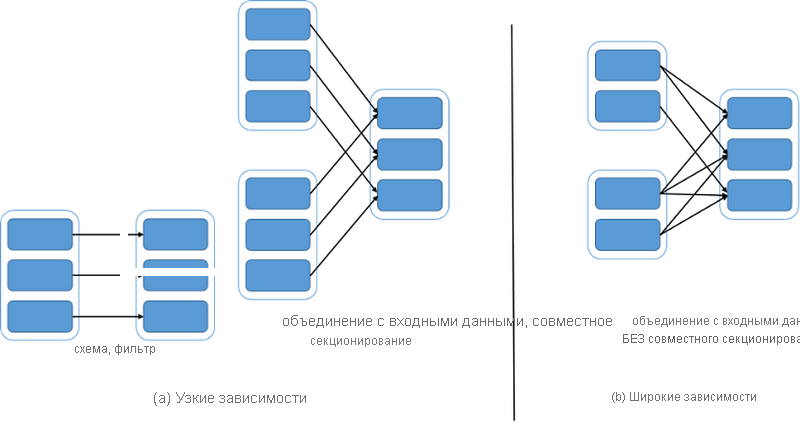
Рис. 5. Узкие и широкие зависимости в Spark
Назначение контрольных точек
Если цепочка журналов преобразований становится слишком длинной или содержит очень широкие зависимости, возможно, что перезапустить ее в случае отказа будет невозможно. Решение в том, чтобы назначить для таких RDD контрольные точки. При этом, в отличие от распределенных систем общей памяти (DSM), полное состояние приложения контрольных точек не требует. Кроме того, неизменяемый характер RDD позволяет выполнять эту задачу в фоновом режиме без значительного влияния на производительность работающего приложения или необходимости использовать распределенную схему моментальных снимков для обеспечения согласованности.
Контрольные точки назначаются для отслеживания метаданных (конфигурации заданий, состояния заданий) и сохранения некоторых созданных RDD в надежное хранилище (HDFS).
Используя методы журнала преобразований и назначения контрольных точек, Spark обеспечивает отказоустойчивость и восстановление.
Ссылки
- Zaharia, Matei and Chowdhury, Mosharaf and Das, Tathagata and Dave, Ankur and Ma, Justin and McCauley, Murphy and Franklin, Michael J and Shenker, Scott and Stoica, Ion (2012). Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation