Экосистема Spark
В Spark есть встроенные библиотеки или модули, включающие Spark SQL для SQL и структурированной обработки данных, потоковую передачу Spark, MLlib для машинного обучения и GraphX для обработки графов. По сути это единая платформа для выполнения ETL, MapReduce и сложной аналитики.
SQL Spark
Apache Spark предоставляет модуль для обработки структурированных данных — Spark SQL. С помощью Spark SQL пользователи могут выполнять запросы типа SQL к RDD Spark1. Spark SQL имеет два основных преимущества:
- Широкий ряд программистов и разработчиков SQL может использовать Spark для выполнения заданий аналитики.
- Широкая база пользователей позволяет разработчикам приложений использовать RDD Spark в качестве серверной части базы данных подобно MySQL или Hive.
Spark SQL предоставляет пользователям абстракцию программирования в виде DataFrames — распределенной коллекции данных, упорядоченных в столбцы. DataFrames также позволяет интегрировать команды SQL в приложения, использующие библиотеку MLlib. Более подробно об этом говорится ниже в разделе об MLlib. API для DataFrames доступны в Java, Scala и Python. DataFrames можно создавать из таблиц в Hive, внешних баз данных, файлов структурированных данных или RDD.
Приложения могут выполнять запросы SQL программным путем (по аналогии с MySQL), используя функцию SQL в sqlContext. Результат возвращается в виде DataFrame. Схему для таблицы также можно указывать программным путем. Источники данных можно указывать через интерфейс DataFrame различными способами, причем Spark SQL поддерживает разные источники данных (например, JSON и Parquet). Как и другие операции с таблицей, загрузку данных можно выполнять программным путем.
Потоковая передача Spark
Потоковая передача Spark, расширение к основному API Spark, обеспечивает масштабируемую, отказоустойчивую обработку потоков данных в режиме реального времени с высокой пропускной способностью.

Рис. 7. Потоковая передача Spark
Потоковая передача Spark позволяет подключить источник данных потоковой передачи к кластеру Spark, как показано на рисунке. Система потоковой передачи Spark разделяет входные потоковые данные на пакеты, которые затем можно передавать в ядро Spark для выполнения необходимых операций аналитики. Например, кластер Spark можно подключить к потоку Twitter, чтобы отфильтровывать твиты об определенной компании или продукте, а отфильтрованные твиты пропускать через анализ тональности и получать в реальном времени отчеты об отношении к продукту или бренду.
Потоковая передача Spark позволяет использовать абстракцию высокого уровня, представляющую собой дискретный поток2 или Dstream, который может создаваться из входного потока. Dstreams представляются в Spark как последовательность RDD. API в потоковой передаче Spark позволяют создавать конвейер потоковой обработки на Java, Python или Scala.
Чтобы создать конвейер потоковой передачи в потоковой передаче Spark, сначала необходимо создать Dstream из источника входных данных. Источник может быть простым, таким как сетевой сокет или файловый поток, или представлять собой более сложную систему, такую как Kafka3, Flume4, Kinesis или Twitter. Созданный Dstream можно отправить в любое количество потоковых функций для преобразования. Некоторые функции включают map(), reduce(), join() и count(). Дополнительные сведения см. в разделе об API.
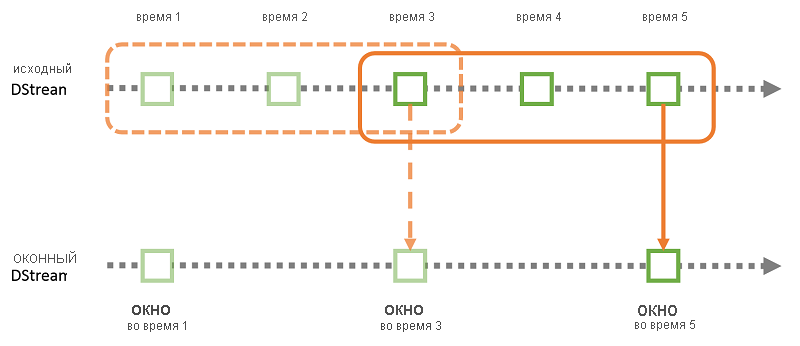
Рис. 8. Вычисление скользящего окна в Потоковой передаче Spark
Помимо простых преобразований потоковая передача Spark позволяет выполнять оконные вычисления, т. е. преобразования, применяемые к скользящему окну данных (рис. 8). В этом случае пользователь может указать как размер окна (число исходных RDD для включения в окно преобразования), так и скользящий интервал (число исходных RDD для выполнения скользящих вычислений в конце каждого преобразования).
После вычисления исходных RDD в Dstream потоковая передача Spark предлагает различные варианты вывода данных, включая запись в двоичные или текстовые файлы либо файлы, совместимые с Hadoop, или сохранение RDD для последующей обработки.
Библиотека машинного обучения: MLlib
Spark предоставляет масштабируемую библиотеку машинного обучения под названием MLlib5. Она работает с API для Apache Spark и подходит для использования в Java, Scala и Python. Для использования MLlib с Python требуется модуль NumPy. В этом случае можно использовать файловую систему Hadoop (HDFS) и другие источники данных на основе Hadoop (например, HBase), что упростит подключение модулей в библиотеках MLlib к рабочим процессам Hadoop. MLlib состоит из стандартных алгоритмов машинного обучения, в том числе для классификации, регрессии, кластеризации, сокращения размерности, преобразования и извлечения функций, а также совместной фильтрации. Существуют также библиотеки для базовой статистики. Кроме того, существует несколько библиотек оптимизации, таких как вероятностный градиентный спуск и БФГС.
Библиотеки в MLlib используют итеративные вычисления, а значит, отличаются высокой производительностью, так как Spark отлично работает с итеративными вычислениями. Это крайне важно для алгоритмов MapReduce, в которых иногда используются однопроходные приближения. Более того, новые версии MLlib в Apache Spark включают новый пакет, spark.ml, позволяющий пользователям объединять несколько алгоритмов в единый обучающий конвейер, который можно указать как последовательность этапов с помощью набора высокоуровневых API.
API машинного обучения Spark включает различные компоненты, которые важно понимать. Один из главных факторов для любой библиотеки машинного обучения — это способ работы с данными, особенно с разными типами данных. Машинное обучение Spark использует DataFrame из Spark SQL для поддержки разнообразных типов данных в рамках концепции единого набора данных.
Еще одной функцией, которая упрощает обработку данных, включенных в API Spark ML, является концепция Transformers — она реализует метод transform(), который помогает в преобразовании данных (например, в преобразовании одного вектора признаков в другой с помощью регуляризации). Другими словами, Transformer представляет собой модель, преобразующую один DataFrame в другой. Дополняет все это алгоритм машинного обучения, который размещает и обучает данные. Это — концепция Estimator, которая реализует метод fit().
Например, NaiveBayes реализует мультиноминальный упрощенный классификатор Байеса. Выходные данные — это NaiveBayesModel, которую можно использовать для прогнозирования на основе тестовых данных. В данном случае NaiveBayes — это Estimator. Рассмотренная модель, NaiveBayesModel, может использоваться как Transformer.
Ход всего процесса машинного обучения — получение данных, преобразование данных в требуемый формат и размещение данных в модели — представляется в виде конвейера в Spark ML. Такой конвейер состоит из серии PipelineStages. Через конвейер можно указать последовательность операций в Spark ML для задания машинного обучения.
GraphX
GraphX6 используется для графов и параллельных вычислений на графах. GraphX — это расширение RDD, и хотя оба включают схожие основные операции, GraphX расширяет RDD Spark за счет новой абстракции графов. Идея GraphX заключается в поддержке некоторых операций и приемов, используемых в платформах для работы с графами, таких как Pregel и GraphLab (см. следующий урок). В результате GraphX позволяет Spark эффективно выполнять параллельные вычисления на графах, такие как PageRank, и подключаемые компоненты, почти с такой же производительностью, как у платформ для работы с графами.
GraphX содержит абстракции для эффективного представления многореляционных графов с атрибутами с помощью RDD Spark. Один из примеров — граф свойств. В таким графе ребра снабжаются метками, а обе вершины и ребра могут иметь любое количество связанных с ними пар "ключ-значение" (см. рис. 9). Граф такого типа также является направленным. По сути, граф такого типа помогает поддерживать несколько параллельных ребер, что можно, например, использовать для обозначения нескольких связей между двумя вершинами. (Например, отношения между коллегами также могут быть друзьями, и вершины графа будут двумя людьми.) В GraphX вершина представлена как уникальный 64-разрядный идентификатор. vertexID Ограничений для порядка этих идентификаторов нет. Ребра графа также имеют соответствующие идентификаторы источника и вершины. Класс Graph содержит члены для доступа к вершинам и ребрам графа.
class Graph[VD, ED] {
val vertices: VertexRDD[VD]
val edges: EdgeRDD[ED]
}
На следующем рисунке показан граф свойств, состоящий из различных участников проекта Archon. Как показано на графе, свойством вершины является имя пользователя и род занятий человека. Ребра графа описывают отношения между людьми. Представленный ниже граф будет иметь следующую сигнатуру:
val userGraph: Graph[(String, String), String]
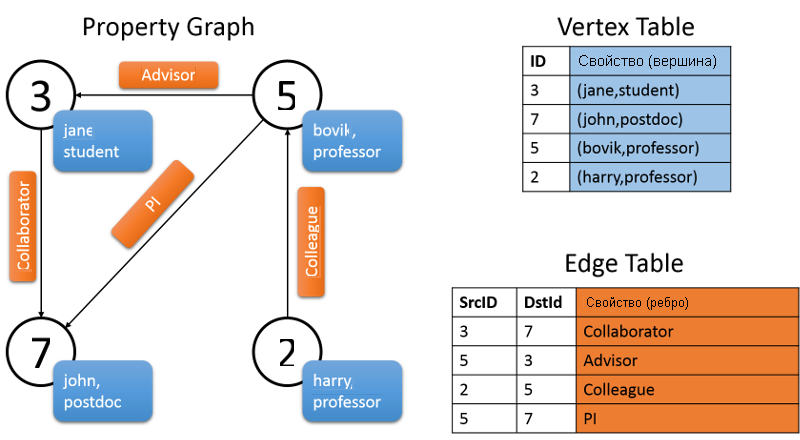
Рис. 9. Граф свойств в GraphX
Граф свойств в GraphX параметризуется по типам вершины (VD) и ребра (ED). GraphX предоставляет несколько способов построения этого графа с учетом коллекции вершин и ребер в RDD или на диске. Графы могут формироваться из необработанных файлов, RDD или синтетических генераторов.
GraphX поддерживает фундаментальные операции с графами (например, subgraph, joinVerticesи aggregrateMessages), а также оптимизированную версию API Pregel. Кроме того, чтобы упростить анализ графов для пользователей, в Spark GraphX включили различные алгоритмы и построители графов. Алгоритмы предоставляются напрямую в виде методов и входят в пакет под названием org.apache.spark.graphx.lib.
Spark GraphX также позволяет пользователям создавать функции и преобразовывать графы на основе новых свойств. GraphX разработан как расширяемая платформа. Для этого используются два класса. Класс Graph состоит из основных операторов с определенными оптимизациями, необходимыми для создания графов. GraphOps — это расширение класса Graph с более удобными операторами, которые используют основные операторы в Graph. Такое разделение операторов применяется в Apache Spark для того, чтобы упростить работу с дальнейшими расширениями. В будущем представления графов должны будут предоставлять основные операторы, перечисленные в классе Graph, и позволять использовать реализацию в GraphOps повторно. Список операций в каждом из этих классов см. в документации по API.
Ссылки
- Xin, Reynold S and Rosen, Josh and Zaharia, Matei and Franklin, Michael J and Shenker, Scott and Stoica, Ion (2013). Shark: SQL and rich analytics at scale Proceedings of the 2013 ACM SIGMOD International Conference on Management of data
- Zaharia, Matei and Das, Tathagata and Li, Haoyuan and Shenker, Scott and Stoica, Ion (2012). Discretized streams: an efficient and fault-tolerant model for stream processing on large clusters Proceedings of the 4th USENIX conference on Hot Topics in Cloud Computing
- Kreps, Jay and Narkhede, Neha and Rao, Jun and others (2011). Kafka: A distributed messaging system for log processing Proceedings of 6th International Workshop on Networking Meets Databases (NetDB), Athens, Greece
- Hoffman, Steve (2013). Apache Flume: Distributed Log Collection for Hadoop Packt Publishing Ltd
- Sparks, Evan R and Talwalkar, Ameet and Smith, Virginia and Kottalam, Jey and Pan, Xinghao and Gonzalez, Joseph and Franklin, Michael J and Jordan, Michael I and Kraska, Tim (2013). MLI: An API for distributed machine learning data mining (ICDM), 2013 IEEE 13th International Conference on Data Mining Workshops
- Xin, Reynold S and Gonzalez, Joseph E and Franklin, Michael J and Stoica, Ion (2013). GraphX: A resilient distributed graph system on Spark First International Workshop on Graph Data Management Experiences and Systems