Пример: файловая система CEPH
Ceph — это система хранения, которую можно развернуть в больших кластерах серверов с подключенными дисками. В следующем видео рассматриваются основные понятия, лежащие в основе Ceph.
Цели проектирования для Ceph2 включают следующее:
- Универсальный кластер хранения, который поддерживает широкий спектр приложений.
- Архитектура, которая может эффективно масштабироваться до сотен тысяч узлов и петабайтов хранилища.
- Высоконадежная система без единой точки отказа, которая является самоуправляемой и надежной.
- Система должна работать на стандартном оборудовании. Ceph должен быть доступен через три различных абстракции, как показано на следующем рисунке.
Кластер хранения Ceph является распределенным хранилищем объектов. На основе кластера хранения размещаются разные службы хранилища, ориентированные на клиента. Служба шлюза объектов Ceph позволяет клиентам получать доступ к кластеру хранения Ceph с помощью интерфейса HTTP на основе REST, который в настоящее время совместим с протоколами Swift в Amazon и Openstack. Служба блочных устройств Ceph позволяет клиентам получать доступ к кластеру хранения в виде блочных устройств, которые можно отформатировать с помощью локальной файловой системы и подключить к операционной системе или использовать в качестве виртуального диска для работы с виртуальными машинами в Xen, KVM, VMWare или QEMU. Наконец, файловая система Ceph (Ceph FS) предоставляет абстракцию файлов и каталогов для всего кластера хранения в качестве файловой системы, отвечающей требованиям POSIX.
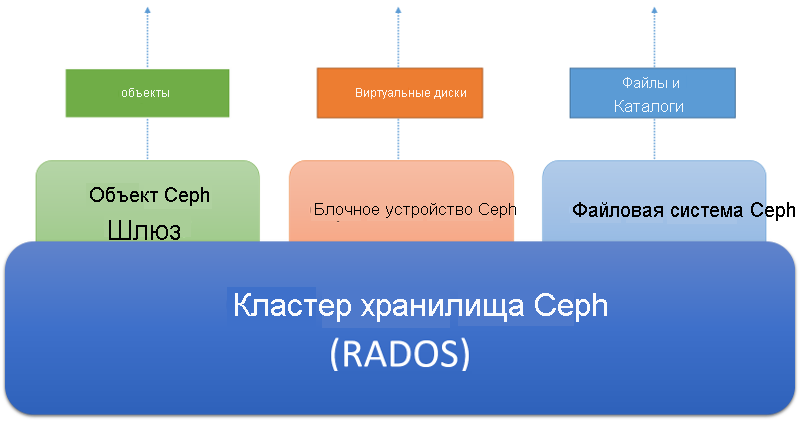
Рис. 6. Экосистема Ceph
Подробная схема архитектуры Ceph представлена ниже:

Рис. 7. Архитектура Ceph
В основе Ceph лежит распределенная система хранения объектов под названием RADOS. Клиенты могут взаимодействовать с RADOS напрямую с помощью низкоуровневого API librados, который основан на сокетах и поддерживает ряд языков программирования. Кроме того, клиенты могут взаимодействовать с тремя API более высокого уровня, которые предоставляют 3 отдельных абстракции в RADOS.
RADOS Gateway, или radosgw, позволяет клиентам получать доступ к RADOS через шлюз на основе REST по протоколу HTTP. Он эмулирует службу объектов Amazon S3 и совместим с приложениями, которые используют API Amazon S3 или API Openstack SWIFT.
Блочное устройство RADOS, или RBD, предоставляет хранилище объектов RADOS как универсальное распределенное блочное устройство, похожее на сеть SAN. RBD позволяет извлечь блочные устройства из RADOS и подключить их к системам Linux с помощью драйвера ядра. RBD также можно использовать в качестве образов виртуальных дисков для популярных систем виртуализации, таких как Xen, VMWare, KVM и QEMU.
Ceph FS — это распределенная файловая система, отвечающая требованиям POSIX и расположенная поверх RADOS, которую можно напрямую подключить в файловых системах клиентов Linux. Мы подробно обсудим Ceph FS далее.
Архитектура кластера хранения Ceph (RADOS)
В основе Ceph лежит надежное, автономное, распределенное хранилище объектов (Reliable, Autonomous, Distributed Object Store, RADOS). В RADOS данные хранятся в виде объектов, распределенных по кластеру компьютеров. Клиенты взаимодействуют с кластером RADOS, сохраняя и извлекая объекты. Объект состоит из имени объекта (ключа, используемого для идентификации объекта), а также двоичного содержимого объекта (которое является значением, связанным с определенным ключом объекта). Роль RADOS заключается в том, чтобы хранить объекты распределенным образом в кластере, обеспечивая масштабируемость, надежность и отказоустойчивость.
В кластере RADOS существует два типа узлов: управляющие программы хранилища объектов (OSD) и узлы монитора (рис. 8). OSD хранит объекты и реагирует на запросы объектов. OSD хранит эти объекты на узлах, используя локальную файловую систему на каждом узле, и сохраняет буферный кэш для повышения производительности. Узлы монитора отслеживают состояние кластера, чтобы знать, какие OSD входят в кластер и выходят из него.
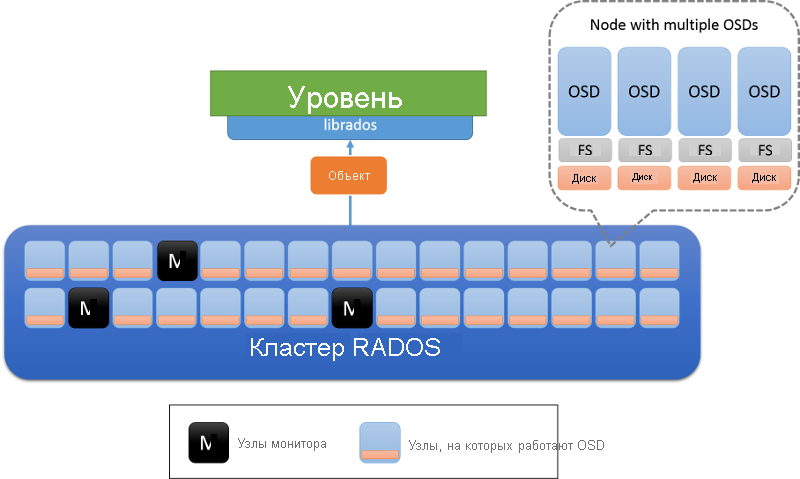
Рис. 8. Архитектура RADOS. OSD отвечает за данные на узле (обычно на каждом физическом диске развертывается один OSD). Узлы, отмеченные M, являются узлами монитора.
Состояние кластера и мониторы в RADOS
Состояние кластера RADOS инкапсулируется в объект, называемый схемой кластера, который совместно используется всеми узлами в кластере. Схема кластеров содержит сведения о состоянии кластера в любой момент времени, включая количество присутствующих OSD, компактное представление того, как данные распределяются между OSD (об этом мы подробно поговорим в следующем разделе), и логическую метку времени, обозначающую время построения этой схемы кластера. Обновления для схемы кластера выполняются узлами монитора в одноранговом режиме и последовательно. Это означает, что между узлами в кластере передаются только изменения в схеме кластера от одной метки времени до другой, чтобы между узлами передавался небольшой объем данных.
Мониторы в RADOS вместе осуществляют управление системой хранения данных путем хранения мастер-копии схемы кластеров и отправки периодических обновлений в случае изменения состояния OSD. Мониторы организованы на основе алгоритма paxos, и для чтения или обновления схемы кластера требуется большая часть мониторов. Мониторы обеспечивают сериализацию и целостность обновлений схемы. Кластер RADOS предназначен для небольшого числа мониторов (>3) и обычно представляет нечетное число, чтобы не допустить неразрешимых споров, когда отдельные мониторы должны прийти к консенсусу.
Размещение данных в RADOS
Чтобы хранилище распределенных объектов работало правильно, клиент должен иметь возможность связаться с правильным OSD для взаимодействия с объектом. Сначала клиент связывается с монитором, чтобы получить схему кластера для данного кластера хранилища. Сведения, содержащиеся в схеме кластера, можно использовать для определения точного OSD, ответственного за определенный объект в кластере.
Первым шагом является определение группы размещения определенного объекта (рис. 9). Группа размещения может рассматриваться как контейнер, в котором находится объект. Это делается с помощью хэш-функции (актуальная хэш-функция всегда получается из схемы кластера). После определения группы размещения для данного объекта клиент должен найти OSD, который отвечает за эту группу размещения.
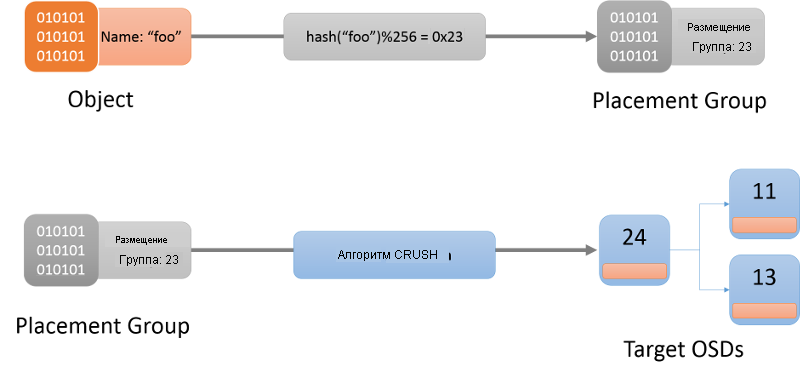
Рис. 9. Поиск объекта в группе размещения и, наконец, в ОСD с помощью алгоритма CRUSH.
Алгоритм, используемый для назначения групп размещения для OSD, известен как Controlled Replication Under Scalable Hashing (CRUSH)1 (рис. 9). CRUSH назначает группы размещения в кластере псевдослучайным, но детерминированным способом. CRUSH является более стабильным, чем хэш-функция, в том смысле, что когда OSD входят в кластер или выходят из него, CRUSH гарантирует, что большинство групп размещения остаются там, где находятся, и перемещает только небольшой объем данных для поддержания сбалансированного распределения. Для простой хэш-функции, напротив, потребуется повторное распространение большинства ключей при добавлении или удалении контейнеров. Здесь мы не будем подробно рассматривать алгоритм CRUSH. Заинтересованные читатели должны ссылаться на CRUSH: управляемое, масштабируемое, децентрализованное размещение реплика данных.
Когда имя объекта хэшируется в группу размещения, CRUSH создает список точных r OSD, которые отвечают за группу размещения. Здесь r — количество реплик для данного объекта. На основе информации в схеме кластера определяются активные OSD, которые находятся в этой схеме, а затем можно связаться с нужным OSD для взаимодействия (создания, чтения, обновления, удаления) с указанным объектом.
Репликация в RADOS
В RADOS объект реплицируется между несколькими OSD, связанными с группой размещения этого объекта. Это гарантирует наличие нескольких копий определенного объекта в случае сбоя определенного OSD. RADOS имеет несколько доступных схем выполнения репликации, например первичная копия, цепочка и splay (рис. 10).
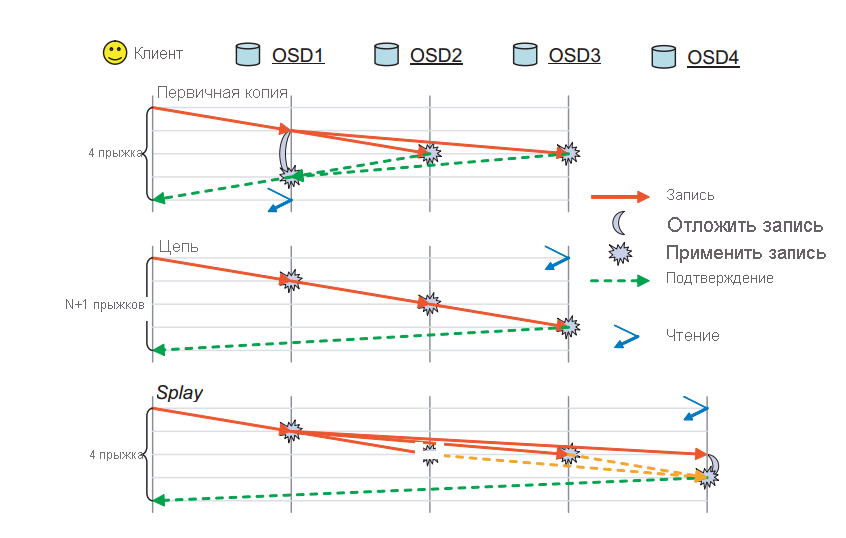
Рис. 10. Режимы реплика, поддерживаемые в RADOS. (Источник 2)
Первичная репликация копирования. В схеме реплика копирования клиент взаимодействует с первой доступной ОСD (основной реплика OSD) для взаимодействия с объектом. OSD первичной реплики обработает запрос и отправит ответ клиенту. В случае записи OSD первичной реплики пересылает запрос на запись в реплики r-1, которые затем обновляют свои локальные копии объекта и отвечают мастеру. Операция записи в мастер откладывается до тех пор, пока все операции записи не будут зафиксированы другими OSD для этого объекта. Затем мастер подтверждает запись в клиент. Запись не завершается, пока все реплики не ответили OSD первичной копии. Такой же процесс применяется для операций чтения. Первичная копия отвечает только после того, как все реплики получили информацию и значение объекта стало одинаковым во всех репликах.
Репликация цепочки. Запросы к объекту перенаправляются вниз по цепочке до тех пор, пока не найден rth (окончательный) реплика. Если это операция записи, она будет зафиксирована для каждой реплики на пути к последней реплике. Финальный OSD, содержащий финальную реплику, в конечном итоге подтвердит запись в клиент. Любая операция чтения будет направляться непосредственно в конец, чтобы сократить число прыжков, необходимое для чтения данных из кластера.
Репликация Splay: Splay реплика tion объединяет элементы как основной копии, так и реплика цепочки реплика. Запросы на чтение направляются к последнему OSD в цепочке реплик, а операции записи отправляются в начало. В отличие от цепочки, обновления средних OSD выполняются параллельно, как в схеме репликации первичных копий.
Помимо этих схем репликации сохраняемость в RADOS обрабатывается с использованием двух отдельных сообщений подтверждения (рис. 11). Каждый OSD имеет буферный кэш данных, обслуживаемых им. Обновления записываются в буферный кэш и немедленно подтверждаются с помощью сообщения ack. Этот буферный кэш периодически записывается на диск, а когда последняя реплика зафиксирует данные на диске, клиенту отправляется сообщение commit, указывающее, что данные были сохранены.
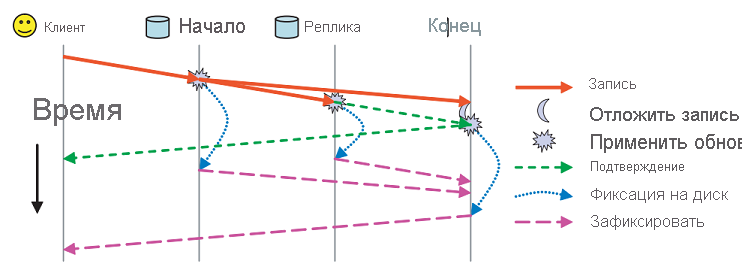
Рис. 11. Ack и фиксация сообщений в RADOS (источник 2)
Модель согласованности в RADOS
Каждое сообщение в RADOS (как от клиента, так и между узлами) имеет метку времени, чтобы обеспечить единообразие упорядочивания и применения сообщений. Если OSD обнаруживает неверное сообщение из-за устаревшей схемы кластера, полученное от запрашивающего объекта, он отправляет последовательные обновления схемы, чтобы предоставить актуальные данные.
В некоторых сложных ситуациях необходимо тщательно обрабатывать гарантии строгой согласованности, предлагаемые RADOS. Если сопоставление группы размещения для определенного OSD меняется (в случае изменения в схеме кластера), система должна обеспечить согласованную и беспрепятственную передачу групп размещения между прежними OSD и новыми. Во время изменения группы размещения новые OSD должны связаться с прежними для передачи состояния, в течение которого прежние OSD узнают об изменениях и перестанут отвечать на запросы этих групп размещения.
Другой случай, когда бывает сложно достичь гарантированной согласованности, связан со сбоем сети, который приводит к разделению сети. В этом случае некоторые клиенты, имеющие старую схему кластера, могут продолжать выполнять операции чтения в этом OSD, в то время как обновленная схема может изменить OSD, отвечающий за эту группу размещения. Как вы помните, мы рассматривали этот сценарий сбоя при обсуждении теоремы CAP. Нарушение согласованности всегда возникает в этом случае. RADOS пытается смягчить последствия, требуя, чтобы все OSD отправляли пакеты пульса с другими репликами с интервалом по умолчанию 2 секунды. Если конкретный OSD не может достичь других групп реплики за определенный период, его операции чтения будут заблокированы. Кроме того, OSD, назначенные в качестве новых первичных элементов для определенной группы размещения, должны либо получить подтверждение передачи образа от прежней группы размещения, либо подождать, пока интервал пакета пульса не укажет на то, что прежний первичный элемент группы размещения не работает. Таким образом уменьшается потенциальная несогласованность в кластере RADOS при наличии разделов сети.
Обнаружение сбоев и отказоустойчивость в RADOS
Сбои узлов в RADOS обнаруживаются во время обмена данными между OSD, назначенными группе размещения, или между OSD и узлами монитора. Если узел не отвечает в течение определенного числа попыток повторного подключения, он объявляется неработающим. OSD, входящие в группу размещения, будут обмениваться сообщениями с пакетами пульса, чтобы убедиться, что сбои обнаружены. Это приводит к тому, что узлы монитора обновляют схему кластера и уведомляют все узлы с помощью сообщения о последовательном обновлении схемы. После обновления схемы кластера OSD будут обмениваться объектами между собой, чтобы гарантировать, что в каждой группе размещения будет необходимое количество реплик. Если OSD получает сообщение о том, что он был объявлен нерабочим, он просто синхронизирует свой буфер с диском и завершается для гарантии согласованности поведения.
Файловая система Ceph
Как показано на предыдущем рисунке, Ceph FS — это уровень абстракции в системе хранения RADOS. RADOS не имеет представления о метаданных для объекта, кроме имени объекта. Файловая система Ceph позволяет создать слой метаданных файлов поверх отдельных объектов файлов, хранящихся в RADOS. В следующем видео объясняется концепция Ceph FS.
Помимо ролей узлов кластера OSD и мониторов, Ceph FS вводит серверы метаданных (MDS) (рис. 12). Эти серверы хранят метаданные файловой системы (дерево каталогов, а также списки управления доступом и разрешения, режим, сведения о владельце и метки времени для каждого файла).
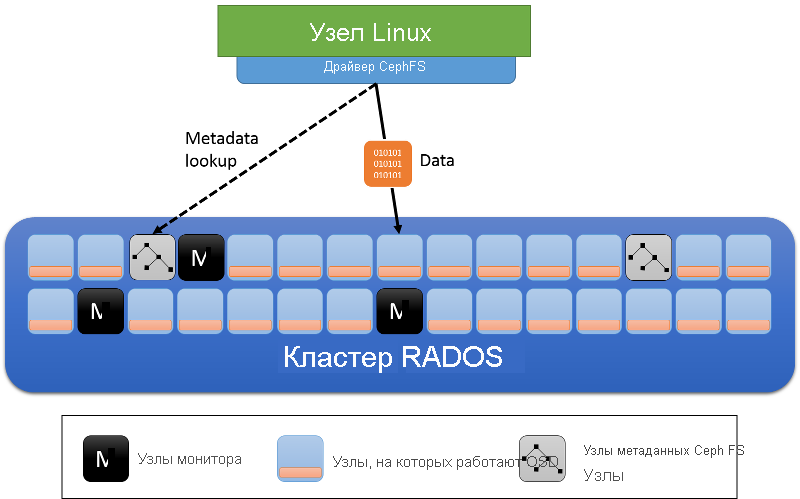
Рис. 12. Серверы метаданных в файловой системе Ceph
Метаданные, используемые Ceph FS, отличаются от метаданных, используемых локальной файловой системой. Как вы помните, в локальной файловой системе файл описывается inode, который содержит список указателей на блоки данных файла. Каталоги в локальной файловой системе — это просто специальные файлы, имеющие ссылки на другие inode, которые могут быть другими каталогами или файлами. В Ceph FS объект каталога на сервере метаданных содержит все внедренные в него inode.
Динамическое секционирование поддерева
Изначально один сервер метаданных отвечает за все метаданные кластера. Когда серверы метаданных добавляются в кластер, дерево каталогов файловой системы секционируется и назначается получившейся группе серверов метаданных (рис. 13). Каждый MDS измеряет популярность метаданных в своей иерархии каталогов с помощью счетчиков. Взвешенная схема3 используется не только для обновления счетчика определенного конечного узла в каталоге, но и для предков этого элемента каталога вплоть до корневого. Таким образом, каждый MDS поддерживает список точек доступа в метаданных, которые можно переместить в новый MDS при добавлении в кластер.
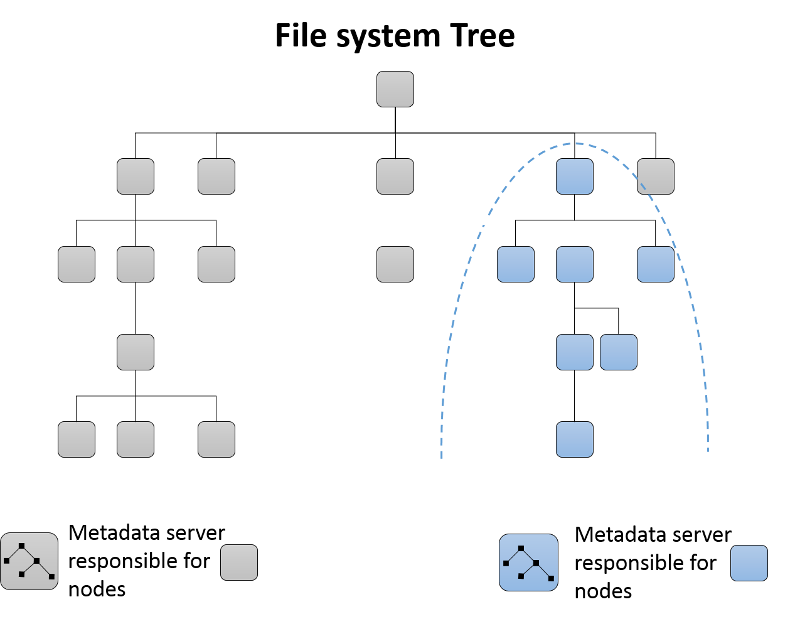
Рис. 13. Динамическое секционирование поддерев в файловой системе Ceph
Кэширование и отказоустойчивость на серверах метаданных
Серверы метаданных в Ceph FS обычно кэшируют сведения о метаданных в памяти и обслуживают большинство запросов из памяти. Кроме того, серверы MDS используют форму ведения журнала, когда обновления отправляются в RADOS в виде объектов журнала и записываются на сервер метаданных. В случае сбоя сервера метаданных журнал можно воспроизвести, чтобы перестроить проблемную часть дерева сервера MDS в новом MDS или существующем экземпляре MDS.
Ссылки
- Вейл, S. A., Брандт, S. A., Миллер, Э. Л., и Малцахн, C. (2006). CRUSH: Controlled, scalable, decentralized placement of replicated data In Proceedings of the 2006 ACM/IEEE conference on Supercomputing 122
- Вейл, S. A., Брандт, S. A., Миллер, Э. Л., и Малцахн, C. (2006). Ceph: A scalable, high-performance distributed file system Proceedings of the 7th symposium on Operating systems design and implementation (OSDI) 307–320
- Вейл, S. A., Pollack, K. T., Brandt, S. A., & Miller, E. L. (2004). Dynamic metadata management for petabyte-scale file systems In Proceedings of the 2004 ACM/IEEE conference on Supercomputing 4