Описание того, что было до облака
Теперь, когда мы определили, что такое облачные вычисления, рассмотрим примеры того, как вычисления использовались в различных доменах, таких как бизнес-вычисления, научные вычисления и персональные вычисления, до появления облачных вычислений.
Бизнес-вычисления: бизнес-вычисления часто включают использование информационных систем управления, которые управляют логистикой и операциями, планирование корпоративных ресурсов (ERP), управление отношениями клиентов (CRM), производительность офисов и бизнес-аналитика (BI). Такие средства позволили оптимизировать процессы, что привело к повышению производительности и снижению затрат на различных предприятиях.
К примеру, программное обеспечение CRM позволяет компаниям собирать, хранить, управлять и интерпретировать различные данные о прошлых, текущих и потенциальных будущих клиентах. Программное обеспечение CRM предлагает интегрированное представление (в режиме реального времени или почти в режиме реальном времени) всех организационных взаимодействий с клиентами. Отдел продаж производственной компании может использовать программное обеспечение CRM в целях планирования встреч, задач и последующих мероприятий с клиентами. Команда маркетологов может ориентироваться на клиентов с помощью кампаний, основанных на определенных шаблонах. Команды бухгалтеров могут отслеживать предложения с расценками и счета. Таким образом, это централизованный репозиторий для хранения данных сведений. Для включения этой функции, организации и отделы продаж используют различные аппаратные и программные технологии по сбору данных, которые необходимо хранить и анализировать с использованием различных баз данных и аналитических систем.
Научные вычисления: научные вычисления используют математические модели и методы анализа, реализованные на компьютерах для решения научных задач. Популярным примером является компьютерное моделирование физических явлений, например, использование моделей климата для прогнозирования погоды. Эта область нарушила традиционные теоретические и лабораторные экспериментальные методы, позволив ученым и инженерам реконструировать известные события или предсказать будущие ситуации, разработав программы для моделирования и изучения различных систем в различных обстоятельствах. Такое моделирование обычно требует очень большого количества вычислений, которые часто выполняются на дорогих суперкомпьютерах или распределенных вычислительных платформах.
Личные вычисления: в персональных вычислениях пользователь запускает различные приложения на персональном компьютере общего назначения (ПК). Примерами таких приложений являются текстовые процессоры и другое офисное программное обеспечение, приложения для коммуникации, такие как клиенты почтовых служб, и развлекательные программы — видеоигры и медиаплееры. Пользователь ПК обычно устанавливает, поддерживает программное и аппаратное обеспечение, используемое для выполнения таких задач, а также владеет им.
Масштабирование адресации
Одной из давних проблем в области ИТ является масштабирование вычислительных ресурсов для удовлетворения спроса, например, увеличение пропускной способности веб-сайта для удовлетворения потребностей растущей клиентской базы или для обработки "взрывных" нагрузок в часы пик или специальных мероприятий, которые привлекают большое количество пользователей.
Увеличение масштабов вычислений является непрерывным процессом, будь то увеличение числа охватываемых клиентов и событий, мониторинга и анализа в CRM, повышения точности числового моделирования в научных вычислениях или реальности в приложениях для видеоигр. Кроме того, необходимость в большем масштабе обусловлена ростом внедрения технологий различными доменами или расширением бизнеса и рынков, а также постоянным увеличением числа пользователей и их потребностей. Организациям необходимо учитывать увеличение масштабов при планировании и выделении бюджета для развертывания своих решений.
Организации обычно планируют свою ИТ-инфраструктуру в рамках процесса планирования ресурсов. В процессе планирования ресурсов рост использования различных ИТ-услуг измеряется и используется в качестве ориентира для будущего расширения. Организациям следует заранее планировать закупку, настройку и обслуживание новых и лучших серверов, устройств хранения данных и сетевого оборудования. Иногда организации ограничены программным обеспечением, потому что они могут приобрести ограниченный набор лицензий, поэтому могут требовать больше для расширения инфраструктуры в целях охвата более широкого набора пользователей.
Наиболее базовая форма масштабирования известна как вертикальное масштабирование, при котором старые системы заменяются новыми, более эффективными, с более быстрыми процессорами, большим объемом памяти и дискового пространства. Во многих случаях вертикальное масштабирование состоит из обновления или замены серверов и увеличения емкости массивов хранения данных. Этот процесс может планироваться и выполняться месяцами и часто требует коротких периодов простоя по мере развертывания обновлений.
Масштабирование также можно выполнить горизонтально, увеличив или уменьшив количество ресурсов, выделенных для системы. Примером этого является высокопроизводительное вычисление, в котором дополнительные серверы и емкость хранилища могут быть добавлены к существующим кластерам, тем самым увеличивая количество вычислений, которые можно выполнять в секунду. Другой пример — веб-фермы — кластеры серверов, на которых размещаются веб-сайты и веб-приложения. К ним можно подключить дополнительные серверы для обработки увеличенного трафика. Подобно вертикальному масштабированию, этот процесс может планироваться и выполняться месяцами, и простои точно также возможны.
Так как компании обслуживали свое ИТ-оборудование и владели им, в условиях роста затрат на масштабирование они нашли другие способы снижения затрат. Крупные компании объединили вычислительные потребности различных отделов в единый большой центр обработки данных, с помощью которого они объединили расходы на помещение, электроэнергию, охлаждение и сеть для снижения затрат. С другой стороны, малые и средние компании могут арендовать помещение, сеть, электроэнергию, охлаждение и физическую безопасность, размещая свое ИТ-оборудование в общем центре обработки данных. Обычно это называется службой совместного расположения, который был реализован малыми и средними компаниями, не желающими создавать свои собственные центры обработки данных собственными силами. Службы совместного размещения по-прежнему применяются в различных областях в качестве экономически эффективного подхода к сокращению эксплуатационных расходов.
Бизнес-вычисления решают задачи масштабирования путем вертикального и горизонтального масштабирования, а также консолидации ИТ-ресурсов в центрах обработки данных и совместного расположения. В научных вычислениях для увеличения масштаба проблем и точности их числового моделирования были применены параллельные и распределенные системы. Одним из определений параллельной обработки является применение нескольких однородных компьютеров, совместно использующих состояние и функционирующих как один большой компьютер для выполнения крупномасштабных или высокоточных вычислений. Распределенные вычисления — это использование нескольких автономных вычислительных систем, подключенных к сети, для разделения большой проблемы на подзадачи, которые выполняются одновременно и передаются по сети через сообщения. Научное сообщество продолжало вводить новшества в этих областях, чтобы решить проблему масштабирования. В персональных вычислениях масштабирование оказало влияние посредством возросших требований, предъявляемых приложениями с большим объемом содержимого, требующими больше памяти. Пользователи заменяют свои ПК новыми, более быстрыми моделями или обновляют существующие модели, чтобы соответствовать этим требованиям.
Рост интернет-служб
Конец 1990-х годов ознаменовался неуклонным ростом использования этих вычислительных приложений и платформ в разных доменах. Вскоре возникли ожидания, что программное обеспечение будет не только функциональным, но и позволит получить ценные сведения для бизнеса и персональных требований. Использование этих приложений стало совместным; приложения были смешаны и сопоставлены для передачи информации друг другу. ИТ теперь был не просто центром затрат для компании, а источником инноваций и эффективности.
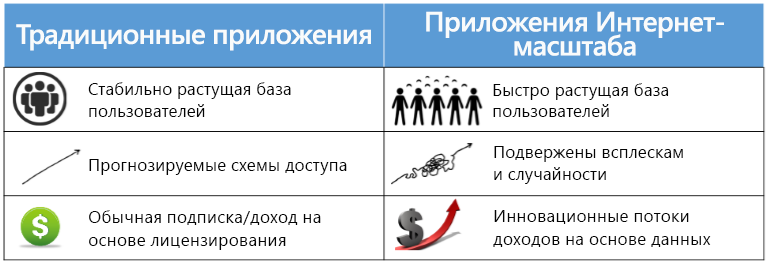
Рис. 1.2. Сравнение традиционных и интернет-масштабируемых вычислений.
21-й век ознаменовался взрывом в объеме и пропускной способности беспроводных коммуникаций, Всемирной паутины и Интернета. Эти изменения привели к созданию общества, управляемого сетью и данными, которые упрощают создание, распространение цифрового объема информации, а также доступ к нему. Интернет создал глобальный рынок с более чем 4 миллиардами пользователей. Этот рост данных и подключений является ценным для предприятий. Данные создают значения несколькими способами, в том числе путем проведения экспериментов, сегментирования групп населения и поддержки принятия решений с помощью автоматизации1. Принимая цифровые технологии, топ-10 экономик в мире, как ожидается, увеличит их добычу более чем на триллион долларов в период с 2015 по 2020 год.
Растущее число подключений через Интернет также повлияло на его значение. Исследователи выдвинули гипотезу, что значение сети изменяется суперлинейно в зависимости от количества пользователей. Таким образом, в масштабе Интернета получение и удержание клиентов является приоритетом, и это достигается путем создания надежных и оперативных служб и внесения изменений на основе наблюдаемых шаблонов данных.
Ниже приведены некоторые примеры систем, доступных через Интернет:
- Поисковые системы, которые сканируют, хранят, индексируют и ищут большие (до петабайта) наборы данных. Например, Google начинал как гигантский веб-индекс, который сканировал и анализировал веб-трафик раз в несколько дней и сопоставлял эти индексы с ключевыми словами. Теперь он обновляет свои индексы практически в режиме реального времени и является одним из самых популярных способов доступа к информации в Интернете. Его индекс содержит триллионы страниц размером в тысячи терабайт3.
- Социальные сети, такие как Facebook и LinkedIn, позволяющие пользователям налаживать личные и профессиональные связи и создавать сообщества на основе схожих интересов. Например, Facebook теперь может похвастаться более чем 2 миллиардами активных пользователей в месяц.
- Службы онлайн-магазинов, такие как Amazon, ведут инвентаризацию миллионов продуктов и обслуживают пользователей по всему миру. В 2017 году объем розничных продаж Amazon в сети составил 178 миллиардов долларов, что на 31 % больше, чем годом ранее.
- Многофункциональные потоковые мультимедийные приложения позволяют людям просматривать и обмениваться видео и другими видами разнообразного контента. Один из таких примеров — YouTube, обслуживает 5 миллиардов видео в день, и каждую секунду на него загружается 300 минут видео.
- Системы связи в реальном временидля аудио, видео и текстовых чатов, такие как Skype, которые обеспечивают более 50 миллиардов минут разговоров в месяц.
- Комплекты для повышения производительности и совместной работы, которые обслуживают миллионы документов для многих одновременно работающих пользователей, обеспечивая постоянные обновления в режиме реального времени. Например, Microsoft 365 обслуживает около 60 миллионов активных пользователей каждый месяц.
- CRM-приложения от таких поставщиков, как SalesForce, развернуты в более чем ста тысячах организаций. Крупные CRM теперь предоставляют интуитивно понятные информационные панели мониторинга для отслеживания состояния, аналитику для поиска клиентов, которые генерируют наибольшее количество прогнозов бизнеса и доходов для прогнозирования будущего роста.
- Приложения для интеллектуального анализа данных и бизнес-аналитики, которые анализируют использование других служб (например, указанных выше), чтобы выявить проблемы и возможности для монетизации.
Очевидно, ожидается, что эти системы будут иметь дело с большим количеством пользователей в одно и то же время. Для этого требуется инфраструктура, способная обрабатывать большие объемы сетевого трафика, генерировать и надежно хранить данные без каких-либо заметных задержек. Эти службы формируют свою ценность, обеспечивая постоянный и надежный стандарт качества. Они также предоставляют разнообразные пользовательские интерфейсы для мобильных устройств и веб-браузеров, что делает их простыми в использовании, но сложными в создании и обслуживании.
Ниже приведены некоторые требования к системам масштабирования в Интернете:
- Повсеместность — доступность из любого места в любое время с множества устройств. Например, продавец ожидает, что служба CRM будет предоставлять своевременные обновления на мобильном устройстве, чтобы сделать посещения клиентов более короткими, быстрыми и эффективными. Служба должна бесперебойно функционировать при различных сетевых подключениях.
- Высокий уровень доступности. Служба должна быть всегда доступна. Время доступности измеряется количеством девяток. Три девятки, или 99,9 %, означают, что служба будет недоступна в течение 9 часов в год. Пять девяток (около 6 минут в год) — это типичный порог для службы высокой доступности. Даже несколько минут простоя в онлайн-приложениях для розничной торговли могут негативно повлиять на продажи в миллионы долларов.
- Минимальная задержка —быстрое и реагирующее время доступа. Было доказано, что даже незначительно медленное время загрузки страницы значительно сокращает использование уязвимой веб-страницы. Например, увеличение задержки поиска со 100 миллисекунд до 400 миллисекунд сокращает количество запросов на пользователя с 0,8 % до 0,6 %, и это изменение сохраняется даже после восстановления задержки до исходного уровня.
- Масштабируемость — способность справляться с переменными нагрузками, вызванными сезонностью и виральностью, что приводит к пикам и спадам трафика в течение длительных и коротких периодов времени. В такие дни, как "Черная пятница" и "Кибер понедельник", розничные продавцы, такие как Amazon и Walmart, получают сетевой трафик в несколько раз превышающий средний показатель.
- Экономическая эффективность — интернет служба требует значительно больше инфраструктуры, чем традиционное приложение, а также лучшего управления[4]. Один из способов сократить расходы — это облегчить управление службами и сократить количество администраторов, обслуживающих службу. Меньшие службы могут иметь низкое соотношение службы к администратору (например, 2:1, что означает, что один администратор должен поддерживать две службы). Однако для поддержания прибыльности такие службы, как Microsoft Bing, должны иметь большое соотношение служб и администраторов (например, 2500:1, то есть один администратор поддерживает 2500 служб).
- Совместимость — многие из этих служб часто используются вместе и, следовательно, должны обеспечивать простой интерфейс для повторного использования и поддерживать стандартизированные механизмы импорта и экспорта данных. Например, такие службы, как Uber, могут интегрировать Карты Google в свои продукты, чтобы предоставлять пользователям упрощенную информацию о местоположении и навигации.
Теперь мы рассмотрим некоторые ранние решения для различных проблем, описанных выше. Первой проблемой, которую необходимо было решить, было значительное время на посещение первых веб-сервисов, расположенных в основном в США, в обе стороны. Самые ранние механизмы для решения проблем с низкой задержкой (из-за удаленных серверов) и сбоя сервера просто полагались на избыточность. Одним из методов достижения этого было "зеркальное отображение" содержимого, при котором копии популярных веб-страниц хранятся в разных местах по всему миру. Это позволило минимизировать объем нагрузки на центральном сервере, сократить время ожидания конечных пользователей, и переключать трафик на другой сервер в случае сбоев. Недостатком стало увеличение сложностей и несогласованность при необходимости изменить даже одну копию данных. Таким образом, этот метод более полезен для статических рабочих нагрузок с интенсивными операциями чтения, таких как показ изображений, видео или музыки. Из-за эффективности этой методики большинство интернет-служб используют сети доставки содержимого (CDN) для хранения распределенных глобальных кэшей популярного контента. Например, Cable News Network (CNN) теперь поддерживает копии своих видео на нескольких "пограничных" серверах в разных местах по всему миру с персонализированной рекламой для каждого местоположения.
Конечно, отдельным компаниям не всегда имеет смысл покупать десятки серверов по всему миру. Эффективность затрат часто достигается за счет использования служб общего размещения. В этом случае части одного веб-сервера будут сданы в аренду нескольким клиентам, что приведет к амортизации затрат на обслуживание сервера. Службы общего расположения могут быть высокоэффективными, поскольку ресурсы могут быть перерасходованы при условии, что не все службы будут одновременно работать на максимальной мощности. (Слишком подготовленный физический сервер — это сервер, в котором агрегатная емкость всех клиентов больше фактической емкости сервера.) Недостатком было то, что почти невозможно изолировать услуги клиентов от тех, кто их соседей. Таким образом, одна перегруженная или подверженная ошибкам служба может отрицательно повлиять на всех ее соседей. Еще одна проблема возникла потому, что арендаторы часто могут быть злоумышленниками и пытаться использовать свое преимущество совместного размещения для кражи данных или отказа в обслуживании других пользователей.
Чтобы противостоять этому, были разработаны виртуальные частные серверы как варианты модели общего размещения. Клиенту будет предоставлена виртуальная машина (ВМ) на общем сервере. Эти виртуальные машины часто были статически распределенными и связанными с одной физической машиной, что означало, что их было трудно масштабировать, и они часто требовали ручное восстановление после любых сбоев. Так как они больше не могли быть избыточно подготовленными, они имели улучшенную производительность и изоляцию безопасности между совместно размещенными службами по сравнению с простым совместным использованием ресурсов.
Другая проблема совместного использования общедоступных ресурсов заключается в том, что для него требовалось хранение личных данных в сторонней инфраструктуре. Некоторые из описанных выше интернет-служб не могут позволить себе потерять контроль над хранением данных, так как любое раскрытие их частных данных может иметь катастрофические последствия. Следовательно, эти компании должны были создать собственную глобальную инфраструктуру. До появления общедоступного облака такие службы могли быть развернуты только крупными корпорациями, такими как Google и Amazon. Каждая из этих компаний должна бы была строить большие, однородные центры обработки данных по всему миру, используя готовые компоненты, где центр обработки данных можно будет рассматривать как один огромный компьютер масштаба хранилища (WSC). WSC обеспечил простую абстракцию для глобального распределения приложений и данных, сохраняя при этом право собственности.
Благодаря экономии на масштабе использование центра обработки данных можно оптимизировать для снижения затрат. Несмотря на то, что это было не так эффективно, как общедоступное совместное использование ресурсов (облако), эти компьютеры масштаба хранилища обладали многими желаемыми свойствами, которые служили основой для создания интернет-служб. Масштаб вычислительных приложений перешел от обслуживания фиксированной пользовательской базы к обслуживанию динамичного глобального заполнения. Стандартизированные WSC позволили крупным компаниям обслуживать такую большую аудиторию. Идеальная инфраструктура сочетает производительность и надежность WSC с моделью совместного размещения. Это позволило бы даже небольшой корпорации разработать и запустить глобально конкурентоспособное приложение без больших затрат на создание крупных центров обработки данных.
Другим подходом к совместному использованию ресурсов были распределенные вычисления типа "решетка", которые позволяли совместно использовать автономные вычислительные системы между учреждениями и географическими точками. Несколько академических и научных учреждений могли сотрудничать и объединять свои ресурсы для достижения общей цели. Затем каждое учреждение присоединялось к "виртуальной организации", выделяя ресурсы определенного набора с помощью четко определенных правил совместного использования. Ресурсы часто бывали разнородными и слабо связанными, что требовало сложных программных конструкций для соединения. Сетки были направлены на поддержку некоммерческих исследовательских и академических проектов и опирались на существующие технологии с открытым исходным кодом.
Облако стало логическим преемником, объединившим многие из функций решений, описанных выше. Например, вместо того, чтобы университеты предоставляли и совместно использовали доступ к пулу ресурсов с использованием сетки, облако позволяет им арендовать вычислительную инфраструктуру, которая централизованно администрируется поставщиком облачных служб. Поскольку центральный поставщик поддерживает большой пул ресурсов для удовлетворения потребностей всех клиентов, облачное хранилище облегчает динамическое масштабирование и уменьшение спроса за короткий период времени. Однако вместо открытых стандартов, таких как сетка, облачные вычисления основаны на частных протоколах и требуют от пользователя определенного уровня доверия к CSP.
Ссылки
- IBM (2017). Что такое большие данные?https://www.ibm.com/analytics/hadoop/big-data-analytics
- Google Inc. (2015 г.). Как выполняется поиск. https://www.google.com/insidesearch/howsearchworks/thestory/
- Гамильтон, Джеймс Р. и др. (2007). О разработке и развертывании служб интернет-масштабирования