Проблемы в облаке: отказоустойчивость
Одной из основных особенностей, отличающих облака и другие распределенные системы от однопроцессорных, является концепция частичных сбоев. В частности, в случае сбоя одного узла или компонента в распределенной системе вся система может продолжать работать. С другой стороны, если один из компонентов (например, ОЗУ) перестает работать в однопроцессорной системе, вся система также выходит из строя. Важнейшей задачей при проектировании распределенных систем или программ является их разработка таким образом, чтобы они могли автоматически допускать частичные сбои без существенного влияния на производительность. Основной метод маскирования сбоев в распределенных системах заключается в использовании аппаратной избыточности, например технологии RAID (см. схему обучения 3 в этом курсе). Однако в большинстве случаев распределенные программы не могут зависеть только от базовых вариантов обеспечения отказоустойчивости в распределенных системах. К распространенным методам, подходящим для распределенных программ, относится избыточность программного обеспечения.
 .
.
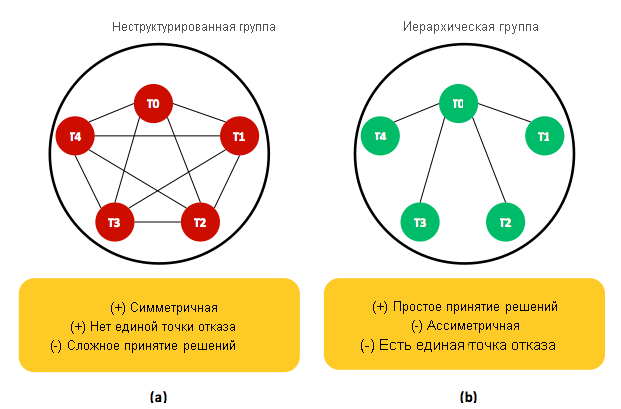
Рис. 15. Два классических способа использования избыточности задач. (a) Неструктурированная группа задач. (б) Иерархическая группа задач с главным процессом (то есть T0, где T1 означает задачу 1).
Одним из распространенных типов избыточности программного обеспечения является избыточность задач (также называемая устойчивостью или репликацией), которая обеспечивает защиту от сбоев и медленной работы задач. Задачи могут быть реплицированы в виде неструктурированных или иерархических групп, как показано на рис. 15. В неструктурированных группах (см. рис. 15 (a)) все задачи идентичны в том, что все они выполняют одну и ту же работу. В итоге принимается результат выполнения только одной задачи, а остальные результаты отбрасываются. Очевидно, что неструктурированные группы являются симметричными и исключают наличие единой точки отказа (SPOF): если одна задача завершается сбоем, приложение остается в рабочем состоянии, но группа становится меньше и будет такой до восстановления. Однако если необходимо принять решение в отношении некоторых приложений (например, получить блокировку), может потребоваться механизм голосования. Как обсуждалось ранее, механизмы голосования сопряжены со сложностями реализации, задержками при взаимодействии и снижением производительности.
Иерархическая группа (см. рис. 15 (б)) обычно использует задачу координатора и определяет остальные задачи как рабочие роли. Когда в этой модели создается запрос пользователя, он пересылается координатору, который, в свою очередь, решает, какая рабочая роль лучше всего подходит для его выполнения. Вполне понятно, что иерархические и неструктурированные группы имеют противоположные характеристики. В частности, координатор является единой точкой отказа и потенциальным узким местом производительности (особенно в крупномасштабных системах с миллионами пользователей). И напротив, до тех пор, пока координатор защищен, вся группа остается функциональной. Кроме того, координатор может самостоятельно принимать решения без обращения к рабочим ролям, без задержек при обмене данными и без снижения производительности. В Hadoop MapReduce реализовано сочетание неструктурированных и иерархических групп задач, которое работает только для сбоев задач. Подробные сведения об этом приводятся в разделе о Hadoop MapReduce.
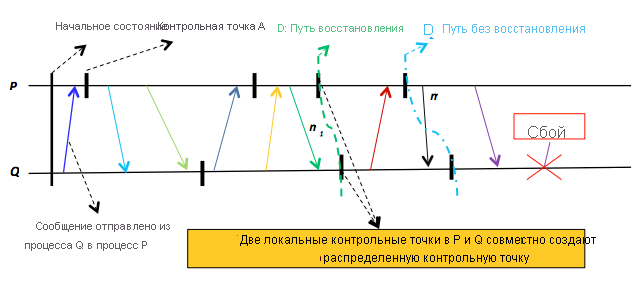
Рис. 16. Демонстрация распределенных контрольных точек. D1 является допустимой распределенной контрольной точкой, а D2 — нет, так как является несогласованной. В частности, контрольная точка D2 в процессе Q указывает на получение сообщения m2, а контрольная точка D2 в процессе P не указывает на отправку сообщения m2.
В распределенных программах отказоустойчивость связана не только с сохранением работоспособности при сбоях, но и восстановлением после сбоев. Основная идея заключается в замене сбойного состояния работоспособным, и одним из способов достижения этой цели является обратное восстановление. Для реализации этой стратегии необходимо перевести распределенную программу или систему из текущего сбойного состояния в прежнее рабочее состояние. Кроме того, требуется периодически записывать состояние системы в каждом процессе, что называется получением контрольной точки. При возникновении сбоя можно запустить восстановление из последнего записанного правильного состояния, обычно называемого строкой восстановления.
Контрольные точки распределенной программы в различных процессах распределенной системы образуют распределенную контрольную точку. Процесс записи распределенной контрольной точки непрост по одной основной причине. В частности, распределенная контрольная точка должна поддерживать устойчивое глобальное состояние, то есть она должна обеспечивать возможность, которая заключается в том, что если процесс $P$ записал получение сообщения $m$, то должен существовать другой процесс $Q$, который записал отправку $m$. В конечном счете сообщение $m$ должно поступать из известного процесса. На рис. 16 показаны две распределенные контрольные точки — $D_{1}$, которая поддерживает устойчивое глобальное состояние, и $D_{2}$, которая не поддерживает его. Контрольная точка $D_{1}$ в процессе $Q$ указывает, что процесс $Q$ получил сообщение $m_{1}$, а контрольная точка $D_{1}$ в $P$ указывает, что процесс $P$ отправил сообщение $m_{1}$, поэтому точка $D_{1}$ становится согласованной. Напротив, контрольная точка $D_{2}$ в процессе $Q$ указывает, что сообщение $m_{2}$ было получено, а контрольная точка $D_{2}$ в процессе $P$ не указывает, что сообщение $m_{2}$ было отправлено из процесса $P$. Таким образом, $D_{2}$ следует считать несогласованной и нельзя использовать в качестве строки восстановления.
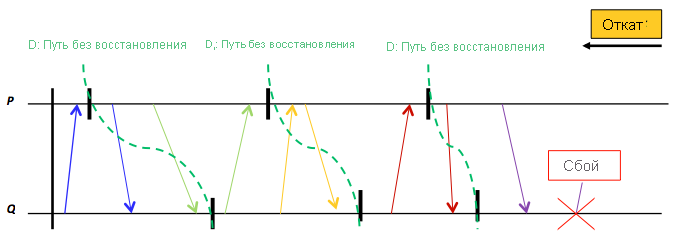
Рис. 17. Эффект домино, который может возникнуть в результате отката каждого процесса (например, процессов P и Q) к сохраненной локальной контрольной точке для поиска строки восстановления. D1, D2 и D3 не являются строками восстановления, так как имеют несогласованные глобальные состояния.
Выполняя откат каждого процесса до его последнего сохраненного состояния, распределенная программа или система может проверить потенциальную распределенную контрольную точку, чтобы определить ее согласованность. Если локальные состояния совместно формируют согласованное глобальное состояние, считается, что строка восстановления найдена. Например, после сбоя система, приведенная на рис. 16, будет выполнять откат до достижения $D_{1}$. Поскольку $D_{1}$ отражает глобальное согласованное состояние, можно сказать, что строка восстановления получена. К сожалению, процесс каскадных откатов является сложной задачей, так как может вызвать эффект домино. На рис. 17 приводится случай, когда не удается найти строку восстановления. В частности, каждая распределенная контрольная точка на рис. 17 является несогласованной. Установка распределенных контрольных точек становится дорогостоящей операцией, которая не гарантирует приемлемое решение по восстановлению. Многие отказоустойчивые распределенные системы позволяют объединять контрольные точки с ведением журнала сообщений, когда каждое сообщение процесса записывается перед отправкой и после установки контрольной точки. Например, эта тактика решает проблему $D_{2}$ на рис. 16. В частности, после установки контрольной точки $D_{2}$ в процессе $P$ отправка сообщения $m_{2}$ будет зафиксирована в сообщении журнала в процессе $P$, что, в случае объединения с контрольной точкой $D_{2}$ в процессе $Q$, позволит сформировать глобально согласованное состояние. Распределенная файловая система (HDFS) Hadoop объединяет распределенные контрольные точки (файл образа) и ведение журнала сообщений (файл изменения) для восстановления NameNode после сбоев (см. схему обучения 3 в этом курсе). Pregel и GraphLab, рассматриваемые в последующих разделах, применяются только к распределенным контрольным точкам.