Модели программирования для облаков
Модели программирования воплощают в себе концепции и предлагают инструменты для разработки крупных вычислительных систем. Модель распределенного программирования, в частности, облегчает преобразование последовательных алгоритмов в распределенные программы, которые могут выполняться в распределенных системах. Возможность указания алгоритма в качестве распределенной программы определяется структурой модели. Модель, которая абстрагирует сведения об архитектуре и оборудовании, автоматически распараллеливает и распределяет вычисления, а также прозрачно поддерживает отказоустойчивость, считается простой в использовании.
Однако эффективность модели зависит от эффективности ее базовых методов. Одним из основных требований для распределенной программы, работающей в системе распределенных компьютеров, является наличие механизма взаимодействия, позволяющего координировать задачи компонентов среди нескольких сетевых ресурсов. Этому условию, хотя и в относительно базовой форме, отвечают две традиционные модели — на основе общей памяти и передачи сообщений. Дополнительные трудности в распределенных программах, типичных для облачных сред, привели к более сложным моделям программирования, которые при реализации в качестве модулей распределенной аналитики могут автоматически распараллеливать и распределять задачи, а также допускать сбои.
Модель с общей памятью
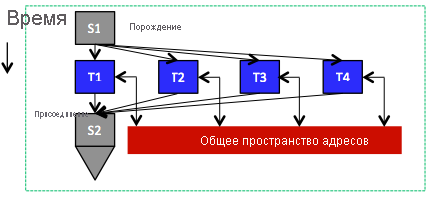
Рис. 4. Задачи, выполняемые параллельно и совместное использование адресного пространства
В соответствии с ключевым принципом модели с общей памятью каждая задача может получить доступ к любому расположению в распределенной памяти приложения. Таким образом, задачи взаимодействуют путем чтения и записи в ячейки памяти в области распределенной памяти, как это происходит в случае с потоками в одном процессе, где все потоки совместно используют адресное пространство процесса (рис. 4). При использовании общей памяти задачи неявным образом обмениваются данными путем совместного использования, а не явной отправки и получения сообщений. Следовательно, модель с общей памятью поддерживает механизмы синхронизации, которые распределенные программы должны использовать для управления порядком выполнения операций чтения и записи различными задачами. В частности, несколько задач не должны одновременно записывать данные в расположение общих данных, иначе данные могут быть повреждены или стать несогласованными. Как правило, эта цель может быть достигнута с помощью семафоров, блокировок и (или) барьеров. Семафор представляет собой механизм синхронизации "точка-точка", который предполагает использование двух параллельных или распределенных задач. Семафоры используют две операции: post и wait. Операция post действует аналогично установке токена, сообщающего о наличии созданных данных. Операция wait блокируется до получения сигнала от операции post о том, что она может продолжать использовать данные. Блокировки защищают критически важные разделы — регионы, к которым получить доступ (обычно для записи) одновременно может только одна задача. Блокировки используют две операции — lock и unlock — для получения и снятия блокировки, связанной с критическим разделом. Блокировка может содержаться только в одной задаче одновременно. Другие задачи смогут получить блокировку только после ее снятия. Барьер определяет точку, далее которой задача не может продолжать выполнение до тех пор, пока все остальные задачи не достигнут этой точки. Обеспечение эффективности семафоров, блокировок и барьеров является важной и сложной задачей при разработке распределенных или параллельных программ для модели программирования с общей памятью.
На рис. 5 показан пример преобразования простой последовательной программы в распределенную с использованием модели программирования с общей памятью. Последовательная программа добавляет элементы двух массивов, b и c, сохраняя результаты в массив a. Впоследствии к общей сумме добавляется любой элемент, превышающий 0 в a. Соответствующая распределенная версия предполагает использование только двух задач и равномерно разделяет работу между ними. Для правильного индексирования (общих) массивов, получения данных и применения заданного алгоритма в каждой задаче задаются начальная и конечная переменные. Очевидно, что общая сумма является критическим разделом, поэтому она защищена блокировкой. Кроме того, ни одна задача не может вывести общую сумму, пока все остальные задачи не завершат свою работу. Таким образом, перед инструкцией вывода данных устанавливается барьер. Как показано в программе, обмен данными между двумя задачами происходит неявно (с помощью операций чтения и записи в общие массивы и переменные), а синхронизация выполняется явным образом (с помощью блокировок и барьеров). Наконец, как отмечалось ранее, базовая распределенная система должна обеспечивать функциональность общего доступа к данным. В частности, инфраструктура должна создавать иллюзию того, что памяти всех компьютеров в системе образуют единое общее пространство, к которому могут обращаться все задачи. Общим примером систем, которые предлагают такое базовое общее (виртуальное) адресное пространство на кластере с несколькими компьютерами (соединенных локальной сетью), можно назвать DSM1, 2. Распространенным языком программирования, который можно использовать в DSM и других распределенных системах с общим доступом, является OpenMP3.

Рис. 5. Последовательные (a) и версии общей памяти (b)
Модель программирования с передачей сообщений
В модели программирования с передачей сообщений распределенные задачи обмениваются данными путем отправки и получения сообщений. В этом случае распределенные задачи не используют общее адресное пространство, в котором они могут обращаться к данным друг друга (см. рис. 6). Ключевая абстракция напоминает процессы, каждый из которых, в отличие от потоков, поддерживает частную область памяти. При отправке и получении данных с помощью явных сообщений в этой модели возникают издержки взаимодействия (например, переменная задержка сети и потенциально избыточная передача данных). Для сбалансированного сочетания этих издержек явный обмен сообщениями неявно синхронизирует последовательность операций в задачах обмена данными. На рис. 7 приведен пример преобразования последовательной программы, показанной на рис. 5 (а), в распределенную версию, использующую передачу сообщений. Изначально доступ к массивам b и c может получить только главная задача с id = 0. Таким образом, при условии, что существует только две задачи, главная задача сначала отправляет части массивов в другую задачу (используя операцию явной отправки), чтобы равномерно разделить работу между двумя задачами. Вторая задача получает необходимые данные (с помощью операции явного получения) и вычисляет локальную сумму. После этого она отправляет эту сумму в главную задачу. Аналогично, главная задача вычисляет локальную сумму в своей части данных и принимает локальную сумму другой задачи перед агрегированием и выводом общей суммы. Как показано на рисунке, для каждой операции отправки существует соответствующая операция получения, и никакой явной синхронизации не требуется. И, наконец, модели программирования с передачей сообщений не нужна поддержка со стороны базовой распределенной системы. В частности, для взаимодействующих задач не требуется иллюзия единого общего адресного пространства. Распространенным примером модели программирования с передачей сообщений является интерфейс передачи сообщений (MPI)4. MPI — это стандартная отраслевая библиотека передачи сообщений (точнее, спецификация того, что может делать библиотека) для написания программ, передающих сообщения. Популярной высокопроизводительной и переносимой реализацией MPI является MPICH5.
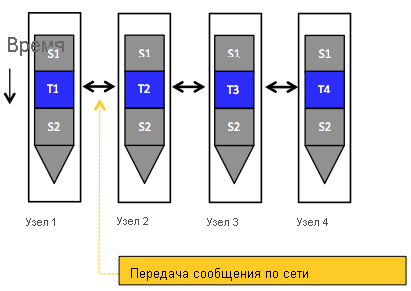
Рис. 6. Задачи, выполняемые параллельно с помощью модели программирования передачи сообщений, при этом взаимодействие происходит только с помощью отправки и получения сообщений по сети.
В следующей таблице сравниваются модели программирования с общей памятью и модели с передачей сообщений с точки зрения пяти аспектов: действия по разработке, настройке, взаимодействию, синхронизации и поддержке оборудования.
Программы с общей памятью изначально легче разрабатывать, потому что программистам не нужно беспокоиться о размещении или передаче данных. Более того, структура кода программы с общей памятью часто очень похожа на структуру ее последовательного аналога. Как правило, программисты только вставляют дополнительные директивы для указания параллельных и распределенных задач, области переменных и точек синхронизации. Напротив, при разработке программ с передачей сообщений программисты должны изменить способ мышления, чтобы априори учесть, как секционировать данные между задачами, собрать данные, а также агрегировать результаты с помощью явного обмена сообщениями.
По мере увеличения масштаба данных и ресурсов значительное влияние на производительность начинают оказывать способ размещения данных и место их хранения. Например, крупномасштабные распределенные системы, такие как облако, предполагают неравномерные задержки доступа (например, доступ к удаленным данным занимает гораздо больше времени, чем доступ к локальным данным), поэтому программисты предпочитают хранить данные вблизи задач, в которых они используются. Несмотря на то, что разработчики программ, передающих сообщения, должны заранее планировать секционирование данных между задачами, разработчики решений с общей памятью будут (в большинстве случаев) решать этот вопрос после разработки, как правило, путем переноса данных или репликации. В этом случае могут потребоваться значительные усилия по настройке.
В крупномасштабных системах точки синхронизации могут стать узким местом производительности: при увеличении числа пользователей, пытающихся получить доступ к критическому разделу, увеличивается время связанных задержек и ожиданий. Мы вернемся к синхронизации и другим проблемам, связанным с программированием в облаке, в одном из последующих модулей.

Рис. 7. Распределенная программа, соответствующая последовательной программе на рис. 5 (a) и закодирована с помощью модели программирования передачи сообщений.
| Аспект | Модель с общей памятью | Модель с передачей сообщений |
|---|---|---|
| Связь | Неявный | Явный |
| Синхронизация | Явный | Неявный |
| Поддержка оборудования | Обычно требуется | Необязательное |
| Усилия по начальной разработке | Lower | Выше |
| Усилия по настройке после вертикального увеличения масштаба | Выше | Lower |
Ссылки
- A. S. Tanenbaum (September 4, 1994). Distributed Operating Systems Prentice Hall, First Edition
- K. Li (1986). Shared Virtual Memory on Loosely Coupled Multiprocessors Yale University, New Haven, CT (USA)
- OpenMP
- Message Passing Interface
- MPICH