Тип параллелизма
При разработке распределенных программ требуется указать тип параллелизма: параллелизм данных или графа. Структура параллелизма данных подчеркивает распределенную природу данных и рассредоточивает их по нескольким компьютерам. В то же время вычисления могут оставаться одинаковыми на всех узлах и применяться к разным данным. В свою очередь, задачи на разных компьютерах могут выполнять разные вычислительные действия. Когда задачи идентичны, распределенная программа классифицируется по принципу "одна программа — много данных" (SPMD). В противном случае действует принцип "много программ — много данных" (MPMD).
Основная идея параллелизма данных проста: распределяя большой файл между несколькими компьютерами, становятся возможными параллельный доступ и обработка различных частей файла. Как обсуждалось в одном из предыдущих модулей, одним из популярных методов распределения данных является чередование файлов, когда один файл секционируется и распределяется по нескольким серверам. Другой формой параллелизма данных является распределение целых файлов (без секционирования) по компьютерам, особенно если файлы небольшие, и содержащиеся в них данные имеют очень нестандартные структуры. Заметим, что данные могут быть распределены между распределенными задачами либо явно (с помощью передачи сообщений), либо неявно (с использованием общей памяти) при условии, что базовая распределенная система поддерживает общую память.
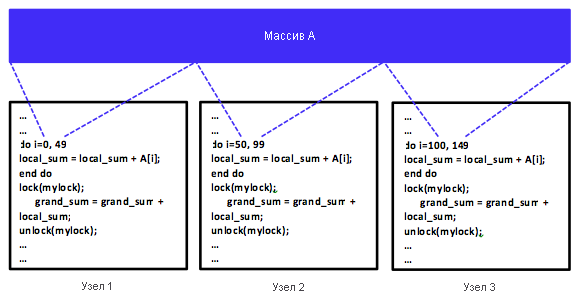
Рис. 9. Распределенная программа SPMD с использованием модели программирования общей памяти
Параллелизм данных достигается, когда на каждом узле выполняется одна или несколько задач с разными частями распределенных данных. Рассмотрим конкретный пример и предположим, что массив A является общим для трех компьютеров в распределенной системе с общей памятью. Возьмем также распределенную программу, которая просто добавляет все элементы массива A. Можно дать компьютерам 1, 2 и 3 команду выполнить задачу сложения в трети массива A или с 50 элементами, как показано на рис. 9. Данные могут быть распределены между задачами с помощью модели программирования с общей памятью, для которой требуется механизм синхронизации. Очевидно, что такая программа поддерживает модель SPMD. Массив A также может быть равномерно распределен (с помощью передачи сообщений) посредством (главной) задачи между тремя компьютерами, включая главный компьютер, как показано на рис. 10. Каждый компьютер будет выполнять задачу сложения независимо друг от друга. Тем не менее в конечном счете результаты суммирования должны быть агрегированы в главной задаче для создания общего итога. В таком сценарии каждая задача похожа в том смысле, что она выполняет ту же операцию сложения, но в другой части массива A. Однако главная задача также распределяет данные по всем задачам и агрегирует результаты суммирования, и этим она немного отличается от двух других задач. Очевидно, что такая программа поддерживает модель SPMD. MapReduce использует параллелизм данных с программами MPMD. Мы рассмотрим этот вариант на одном из следующих уроков о MapReduce.
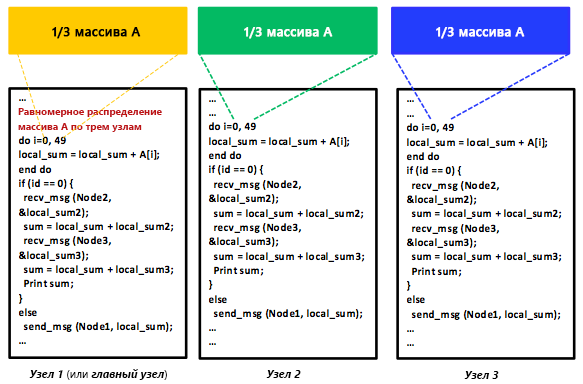
Рис. 10. Распределенная программа MPMD с помощью модели программирования передачи сообщений
Параллелизм графов, с другой стороны, делает акцент на распределении вычислений, а не данных. Большинство распределенных программ фактически находится где-то посередине между двумя формами. Параллелизм графов широко используется во многих областях, таких как машинное обучение, интеллектуальный анализ данных, физика и проектирование электронных схем. Многие проблемы в этих сферах можно моделировать как графы, в которых вершины представляют собой вычисления, а ребра определяют зависимости данных или взаимодействия. Напомним, что граф $G$ является парой $(V,E)$, где $V$ — это конечный набор вершин, а $E$ — конечный набор парных связей $E \subset (V \times V)$, называемых ребрами. Веса можно связать с вершинами и ребрами, чтобы показать объем работ на каждой вершине и данные обмена сообщениями на каждом ребре.
Рассмотрим классическую проблему проектирования цепи: общая цель — обеспечить электрическую эквивалентность определенных контактов нескольких компонентов при их соединении проводами. Если взять $n$ контактов, то можно использовать $(n – 1)$ проводов, каждый из которых соединяет два контакта. Из всех таких вариантов наиболее целесообразным, как правило, является тот, который требует минимального количества проводов. Эту проблему можно смоделировать в виде графа. Каждый контакт может быть представлен в виде вершины, а каждое подключение между парой контактов $(u, v)$ может быть представлено как ребро. Вес $w(u, v)$ может быть задан между $u$ и $v$ для определения затрат (необходимого количества проводов) для подключения $u$ и $v$. Задача в том, как найти ациклическое подмножество $S$ ребер $E$, соединяющих все вершины $V$, и их общий вес.
$$ w(S) = \Sigma_{(u, v)\in S} w(u, v) $$
является минимальным значением.
Так как $S$ является ациклическим и полностью подключенным, должно быть сформировано дерево, известное как минимальное связующее дерево. Следовательно, решение проблемы с подключением преобразуется в решение проблемы минимального связующего дерева, классической проблемы, требующей применения алгоритмов Крускала и Прима.
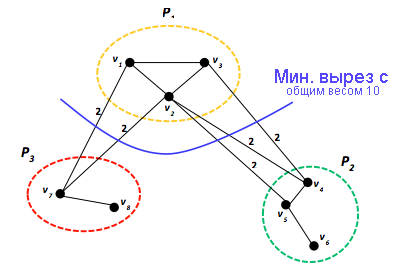
Рис. 11. Диаграмма, секционированная с помощью метрики ребра
Смоделированную в виде графа программу можно распределить между компьютерами в распределенной системе с помощью технологии секционирования графа, которая предполагает разделение работы (вершин) по распределенным узлам для эффективного выполнения распределенных вычислений. Как и в случае параллелизма данных, основная идея параллелизма графа проста: распределяя большой граф между несколькими компьютерами, можно параллельно обрабатывать его различные части. Стандартная цель секционирования графа заключается в равномерном распределении работы по p процессорам путем секционирования вершин на p секций одинакового веса и минимизации межузлового взаимодействия, представленного ребрами. Такая цель обычно называется стандартной метрикой обрезки ребер. Несмотря на то, что проблема секционирования графа является NP-трудной, эвристика позволит достичь практически оптимальных решений. На рис. 11 показаны три секции $P_{1}$, $P_{2}$ и $P_{3}$, в которых вершины $ \lbrace v_{1}, \cdots, v_{8} \rbrace $ разделены с помощью метрики обрезки ребер. Вес каждого ребра равен двум, что соответствует одной единице данных, передаваемых в каждом направлении. Следовательно, общий вес показанной обрезки ребра равен десяти. Другие обрезки приведут к увеличению трафика обмена данными. Очевидно, что для приложений с интенсивным обменом данными секционирование графов имеет важное значение и может играть значительную роль в определении общей производительности приложений. Pregel и GraphLab используют секционирование графов. Мы рассмотрим каждый вариант на следующих уроках.
Ссылки
- T. H. Cormen, C. E. Leiserson, R. L. Rivest, and C. Stein (July 31, 2009). Introduction to Algorithms MIT Press, Third Edition
- B. Hendrickson and T. G. Kolda (2000). Graph Partitioning Models for Parallel Computing Parallel Computing
- M. R. Garey, D. S. Johnson, and L. Stockmeyer (1976). Some Simplified NP-Complete Graph Problems Theoretical Computer Science
- B. Hendrickson and R. Leland (1995). The Chaco User's Guide Version 2.0 Technical Report SAND95-2344, Sandia National Laboratories
- G. Karypis and V. Kumar (1998). A Fast and High Quality Multilevel Scheme for Partitioning Irregular Graphs SIAM Journal on Scientific Computing