Проблемы с облаком: масштабируемость
При проектировании и реализации распределенной программы требуется, как мы видели, выбрать модель программирования и решить проблемы, связанные синхронизацией, параллелизмом и архитектурой. Помимо этих вопросов, при разработке облачных программ разработчик должен также уделять пристальное внимание ряду других задач, имеющих важное значение для облачных сред. Далее мы обсудим проблемы с масштабируемостью, взаимодействием, разнородностью, синхронизацией, отказоустойчивостью и планированием.
Масштабируемость
Распределенная программа считается масштабируемой, если она остается эффективной при значительном увеличении количества пользователей, объема данных и ресурсов. Чтобы получить представление о масштабах проблемы, рассмотрим множество популярных приложений и платформ, которые в настоящее время предлагаются миллионам пользователей в качестве интернет-сервисов. В эпоху распространения больших объемов данных ("эпоха терабайт" — фраза Intel)1 распределенные программы обычно работают с данными глобального масштаба — порядка сотен или тысяч гигабайт, терабайт или петабайт. В 2010 году во всем мире источники данных создали приблизительно 1,2 ЗБ (1,2 млн петабайтов) данных, а в 2020 году ожидается приблизительно в 44 раза больше.2 Интернет-службы, такие как электронная коммерция и социальные сети, обрабатывают данные, создаваемые миллионами пользователей ежедневно. Что касается ресурсов, облачные центры обработки данных уже размещают десятки сотен тысяч компьютеров. Согласно прогнозам, их число еще увеличится в несколько раз.
Фактическое выполнение на n узлах никогда не достигнет идеального n-кратного увеличения производительности. На это есть несколько причин.
- Как показано на рис. 13, некоторые части программы не могут быть распараллелены (например, инициализация).
- Высока вероятность неравномерного распределения нагрузки между задачами, особенно в распределенных системах, таких как облака, где разнородность является основным фактором. Как показано на рис. 13 (б), неравномерное распределение нагрузки обычно задерживает выполнение программ, поэтому программа привязывается к самой медленной задаче. В частности, даже если все задачи в программе завершены, программа не может считаться выполненной до завершения последней задачи.
- Затруднить масштабирование могут и другие серьезные проблемы, связанные с взаимодействием и синхронизацией.
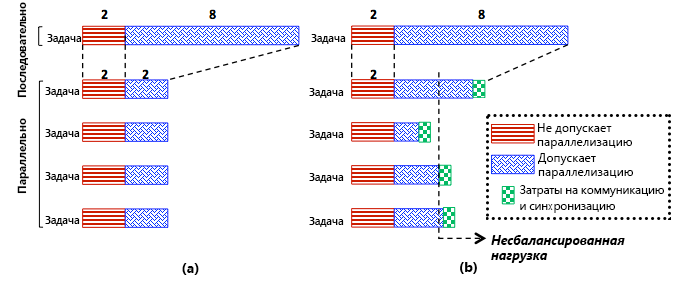
Рис. 13. Параллельное ускорение: (a) идеальный случай и (b) реальный случай
Эти проблемы важны для сравнения производительности распределенных и последовательных программ. Широко используемым выражением, которое описывает ускорения и при этом учитывает различные издержки, является закон Амдала. Чтобы проиллюстрировать вычисление, предположим, что для выполнения последовательной версии программы $T$ требуется $T_{s}$ единиц времени, а для выполнения параллельной или распределенной версии требуется $T_{p}$ единиц времени и кластер с $n$ узлами. Кроме того, предположим, что часть $f$ программы не поддерживает параллелизм, поэтому распараллеливается оставшаяся часть $(1 – f)$. В соответствии с законом Амдала ускорение выполнения параллельной или распределенной версии программы $P$ по сравнению с последовательной версией можно определить следующим образом:
$$ Speedup_{p} = \frac{T_{s}}{T_{p}} = \frac{T_{s}}{T_{s} \times {f + T_{s}} \times \frac{1 - f}{n}} = \frac{1}{f + \frac{1 - f}{n}} $$
Несмотря на то, что формула кажется несложной, она имеет большое значение: если взять кластер с неограниченным количеством компьютером и постоянным значением $s$, можно выразить максимально достижимое ускорение простым вычислением ускорения программы $P$ с бесконечным числом процессоров следующим образом:
$$ \lim_{n\to\infty} Speedup_{p} = \lim_{n\to\infty} \frac{1}{f + \frac{1 - f}{n}} = \frac{1}{f} $$
Чтобы понять суть этого анализа, предположим, что доля последовательной версии $f$ составляет всего 2 %. Применение формулы с неограниченным числом компьютеров приведет к максимальному ускорению, составляющему всего 50. Если сократить $f$ до 0,5 %, максимальное ускорение будет равно 200. Следовательно, мы видим, что достижение нужного уровня масштабируемости в распределенных системах является чрезвычайно сложной задачей, так как для этого необходимо, чтобы доля $f$ была практически равна 0, и в данном анализе не учитываются издержки неравномерного распределения нагрузки, синхронизации и взаимодействия. На практике издержки синхронизации (например, выполнение барьерной синхронизации и получение блокировок) увеличиваются с ростом числа компьютеров, часто сверхлинейно3. В крупномасштабных распределенных системах также значительно растут издержки взаимодействия, так как все компьютеры не могут использовать общие короткие физические подключения. Неравномерное распределение нагрузки становится большой проблемой в разнородных средах, и мы вскоре рассмотрим этот момент. Следует подчеркнуть, что при использовании входных данных для веб-масштабирования издержки синхронизации и взаимодействия могут быть значительно снижены, если они занимают гораздо меньшую часть общего времени выполнения по сравнению с вычислениями, но добиться этого непросто. К счастью, для многих приложений, работающих с большими данными, эта ситуация складывается именно так.
Ссылки
- S. Chen and S. W. Schlosser (2008). MapReduce Meets Wider Varieties of Applications IRP-TR-08-05, Intel Research
- M. Zaharia, A. Konwinski, A. Joseph, R. Katz, and I. Stoica (2008). Improving MapReduce Performance in Heterogeneous Environments OSDI
- Y. Solihin (2009). Fundamentals of Parallel Computer Architecture Solihin Books