Проблемы с облаком: обмен данными
Даже в распределенных системах с общей памятью, таких как DSM, сообщения передаются между компьютерами внутренним, но полностью прозрачным для пользователей образом. Следовательно, все сводится к передаче сообщений. Можно возразить, что единственным способом взаимодействия распределенных систем является передача сообщений. На самом деле, Кулурис и соавторы используют именно это определение для распределенных систем1. Быстрая скорость доставки сообщений распределенными системами, такими как облако, в значительной степени зависит от базовой сети по следующим трем основным причинам: производительность, затраты и качество обслуживания (QoS). В частности, быстрая доставка сообщений сокращает время выполнения, снижает затраты (поскольку облачные приложения могут выполняться быстрее) и повышает качество обслуживания, особенно для аудио- и видеоприложений. Это условие делает вопрос взаимодействия главной темой при разработке облачных программ. Более того, некоторые могут утверждать, что взаимодействие занимает центральное место в облаке и является одним из его основных узких мест.
Для устранения проблем взаимодействия в облаке распределенные программы могут применять два метода.
Совместное размещение
Попыткой совместного размещения тесно взаимодействующих сущностей можно считать распределение или разделение работы между компьютерами. Эта стратегия может снизить нагрузку на облачную сеть и впоследствии повысить производительность. Однако реализовать эту цель не так просто, как может показаться. Например, стандартная стратегия обрезки ребер стремится секционировать вершины графа на p одинаково взвешенных секций по p процессорам таким образом, чтобы свести к минимуму общий вес пересечения ребер между секциями.
Внимательно изучив эту стратегию, мы признаем наличие серьезного недостатка, который оказывает непосредственное влияние на взаимодействие. Как было показано ранее на рис. 10, при минимальной обрезке, полученной в результате использования метрики обрезки ребер, упускается из виду тот факт, что некоторые ребра могут представлять собой один и тот же поток информации. В частности, $v_{2}$ в $P_{1}$ на рисунке дважды отправляет одно и то же сообщение в $P_{2}$ (специально для $v_{4}$ и $v_{5}$ в $P_{2}$), хотя достаточно передать сообщение только один раз, так как $v_{4}$ и $v_{5}$ будут существовать на одном компьютере. Аналогичным образом, $v_{4}$ и $v_{7}$ могут передавать сообщения в $P_{1}$ только один раз, но они делают это дважды.
Таким образом, стандартная метрика обрезки ребер, переоценивает объем обмена данными и, следовательно, приводит к избыточному сетевому трафику. В результате пропускная способность взаимосвязей может подвергаться нагрузке, а производительность снижаться. Даже если общий объем обмена данными (или количество сообщений) значительно уменьшается, неравномерное распределение нагрузки может привести к появлению узких мест. В частности, может случиться так, что, несмотря на сокращение объема обмена данными, одни компьютеры будут получать более крупные секции (с большим количеством вершин), чем другие. Идеальным и в то же время сложным подходом является минимизация потерь пропускной способности с одновременным обходом неравномерного распределения вычислительных операций между компьютерами. Последняя стратегия направлена на эффективное распределение работы между компьютерами, чтобы обеспечить совместное размещение тесно взаимодействующих сущностей.
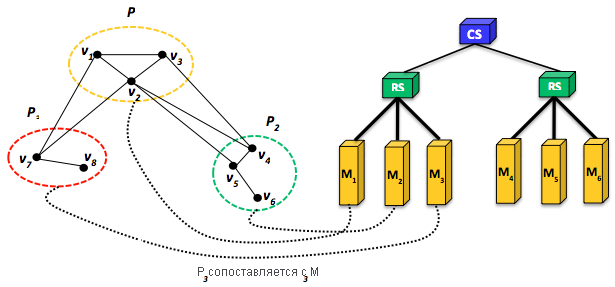
Рис. 14. Эффективное сопоставление секций графа с компьютерами кластера. Сопоставление P1 с другой стойкой, в то время как P2 и P3 остаются в той же стойке, что приводит к большему объему сетевого трафика и потенциальному снижению производительности.
Эффективное сопоставление секций
Для достижения максимально эффективно результата стратегия сопоставления секций (секций графа или данных) с компьютерами должна быть полностью осведомлена о базовой топологии сети. Для решения этой задачи обычно требуется определить количество коммутаторов, на которые будет передано сообщение, прежде чем оно достигнет места назначения. На рис. 14 показан тот же граф, что и на рис. 10 (на более раннем уроке), и упрощенный кластер с сетью в стиле дерева и шестью компьютерами. Сеть кластера состоит из двух стоечных коммутаторов (RS), каждый из которых соединяет три компьютера, и основного коммутатора (CS), соединяющего два стоечных коммутатора. Обратите внимание, что пропускная способность между двумя компьютерами зависит от их относительного расположения в топологии сети. Например, компьютеры в одной стойке используют подключение с более высокой пропускной способностью в отличие от компьютеров вне стойки. Таким образом, сокращается сетевой трафик между стойками. Если $P_{1}$, $P_{2}$ и $P_{3}$ сопоставлены с $M_{1}$, $M_{2}$ и $M _{3}$, то при взаимодействии $P_{1}$, $P_{2}$ и $P_{3}$ будет отмечаться более низкая сетевая задержка по сравнению с тем, как если бы они сопоставлялись между двумя стойками. Точнее, для взаимодействия $P_{1}$ с $P_{2}$ в одной стойке требуется только один прыжок, чтобы направить сообщение от $P_{1}$ к $P_{2}$. Напротив, для взаимодействия $P_{1}$ с $P_{2}$ в разных стойках для каждого сообщения требуется два прыжка. Совершенно очевидно, что меньшее количество прыжков способствует сокращению сетевой задержки и повышению общей производительности. К сожалению, достичь этой цели в облаке не так просто, как это может показаться, по одной главной причине: в общедоступных облачных системах сетевые топологии остаются скрытыми. Тем не менее топологию сети можно по-прежнему изучать (хотя и неэффективно) с помощью теста производительности, такого как Netperf, предназначенного для измерения пропускной способности TCP-потока "точка — точка" между всеми парами узлов кластера. Такой подход позволяет оценивать относительное расположение узлов и делать обоснованные выводы о топологии стоек кластера.
Ссылки
- G. Coulouris, J. Dollimore, T. Kindberg, and G. Blair (май 2011 г.). Distributed Systems: Concepts and Design Addison-Wesley
- Netperf
- M. Hammoud, M. S. Rehman, and M. F. Sakr (2012). Center-of-Gravity Reduce Task Scheduling to Lower MapReduce Network Traffic CLOUD