Архитектуры реального времени на практике
Многие интернет-компании начали использовать в своих приложениях очереди сообщений и платформы потоковой обработки. В основном это связано с тем, что таким компаниям стало выгодно использовать свежие данные. Теперь, когда мы разобрали основные понятия — очереди сообщений, потоковая обработка и лямбда-архитектуры, — рассмотрим реальный пример того, как архитектура, способная справляться с большими объемами данных при низкой задержке, приносит пользу крупной компании. В частности, мы покажем, как внедрение Kafka и Samza позволило LinkedIn транслировать данные сразу в множество разных систем в режиме реального времени.
Внедрение Kafka и Samza в LinkedIn
LinkedIn, как молодая технологическая компания, постоянно создает и внедряет разнообразные инновационные технологии, каждая из которых призвана решать определенную задачу. Службы компании работали на заказном сервере, который использовал принадлежавшие компании LinkedIn распределенное хранилище пар "ключ-значение" (Voldemort) с низкой задержкой, распределенное хранилище документов (Espresso) и ОРСУБД Oracle. Клиентские веб-службы, аналитика, электронная почта и уведомления управлялись с задачами разной степени сложности. В их число входили пакетные задания с использованием Hadoop, запросы к большому складу данных и отдельная инфраструктура для поисковых запросов, все это поддерживалось слоем ведения журналов, мониторинга и отслеживания пользователей и метрик.
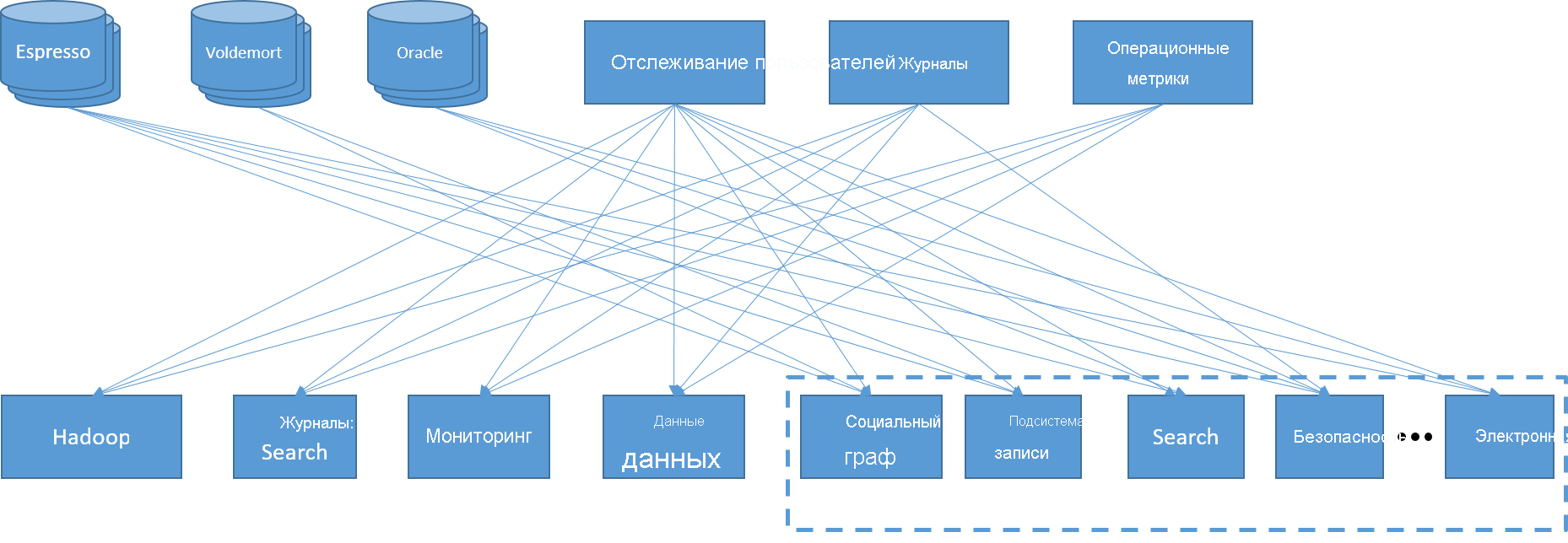
Рис. 19. Катастрофа интеграции данных в LinkedIn
Несколько лет назад инженеры LinkedIn осознали, что их система стала слишком сложной. Обмен данными между службами, внешними интерфейсами и серверами осуществлялся по принципу "все ко всем", поскольку каждый компонент имел свою собственную задержку и требования к пропускной способности. Если нужно было добавить одну единственную службу, ее приходилось подключать к большому количеству компонентов, из-за чего появлялись крайне уязвимые конечные точки. Кроме того, это вело к изоляции, поскольку отдельные владельцы служб не хотели делиться своими данными.
Первым изменением в LinkedIn стал переход к централизованному конвейеру данных под управлением Kafka. Это позволило каждой службе создавать и выдавать данные, используя определенную тему. Доступ к данным из другой службы упростился до подписки на определенную тему. Поскольку конвейер выполнялся в распределенном кластере, он был заведомо масштабируемым.
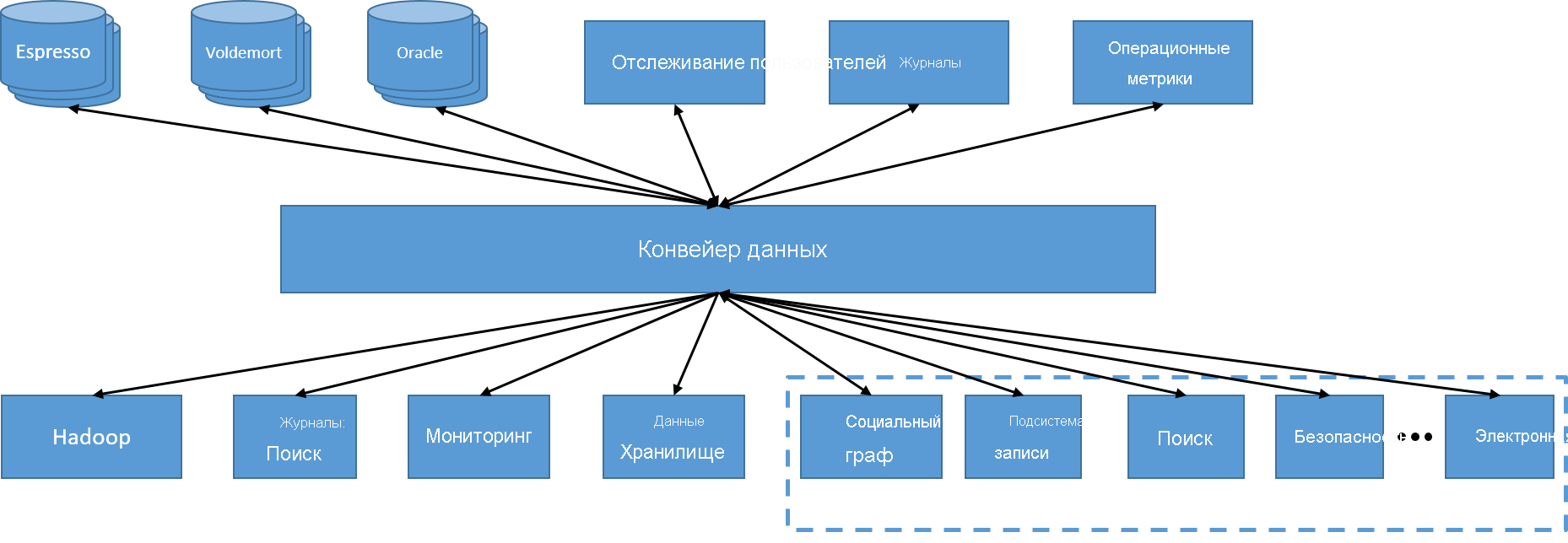
Рис. 20. Один распределенный, асинхронный конвейер данных
Теперь для управления членством узлов в центре обработки данных потребовалась другая служба. Поскольку для увеличения и уменьшения масштаба теперь было достаточно просто добавить или убрать из системы узлы, новая служба под названием ZooKeeper использовалась для управления членством в кластере, передачи владения разделами и темами на уровне брокеров и правильной обработки смещений на уровне потребителей.
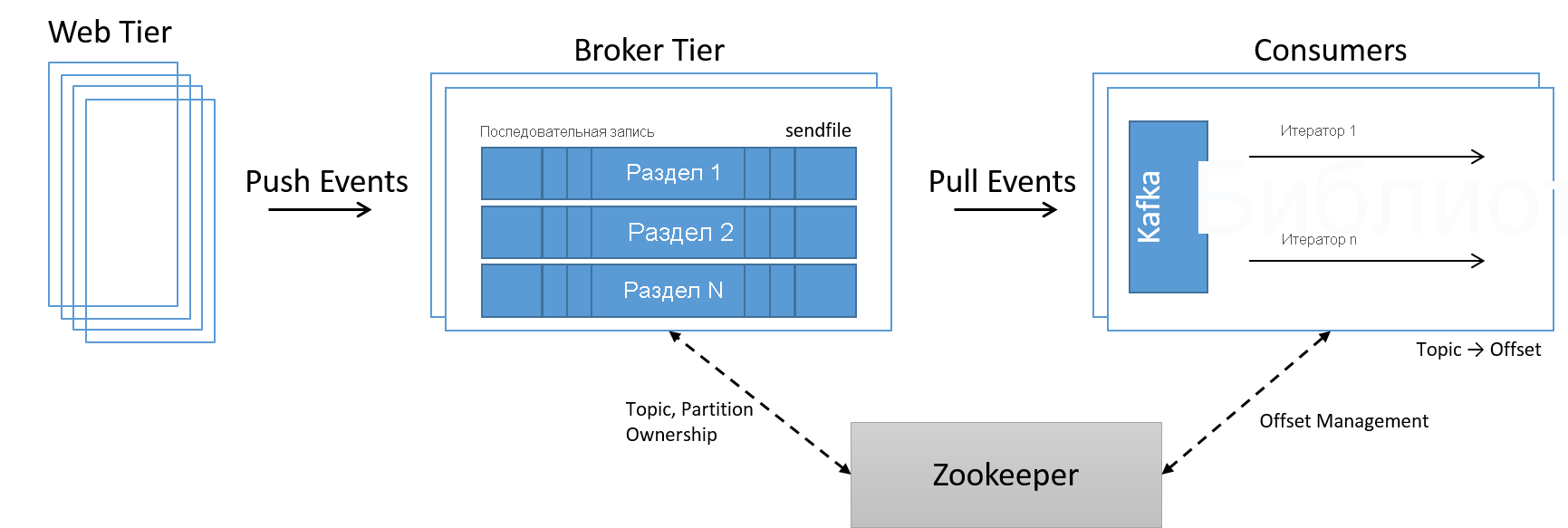
Рис. 21. Обработка данных высокой скорости с помощью разделов Kafka
Изменения в архитектуре LinkedIn также были связаны с переходом на более реактивные системы. В исходной архитектуре (примерно 2010 года) все журналы действий пользователей обрабатывались пакетным процессом через каждые несколько часов — на основе полученных данных во внешнем интерфейсе создавались новые графы и панели мониторинга. Она давала LinkedIn ежечасное или ежедневное обновление данных по количеству просмотров, рекомендациям пользователей и популярным темам.
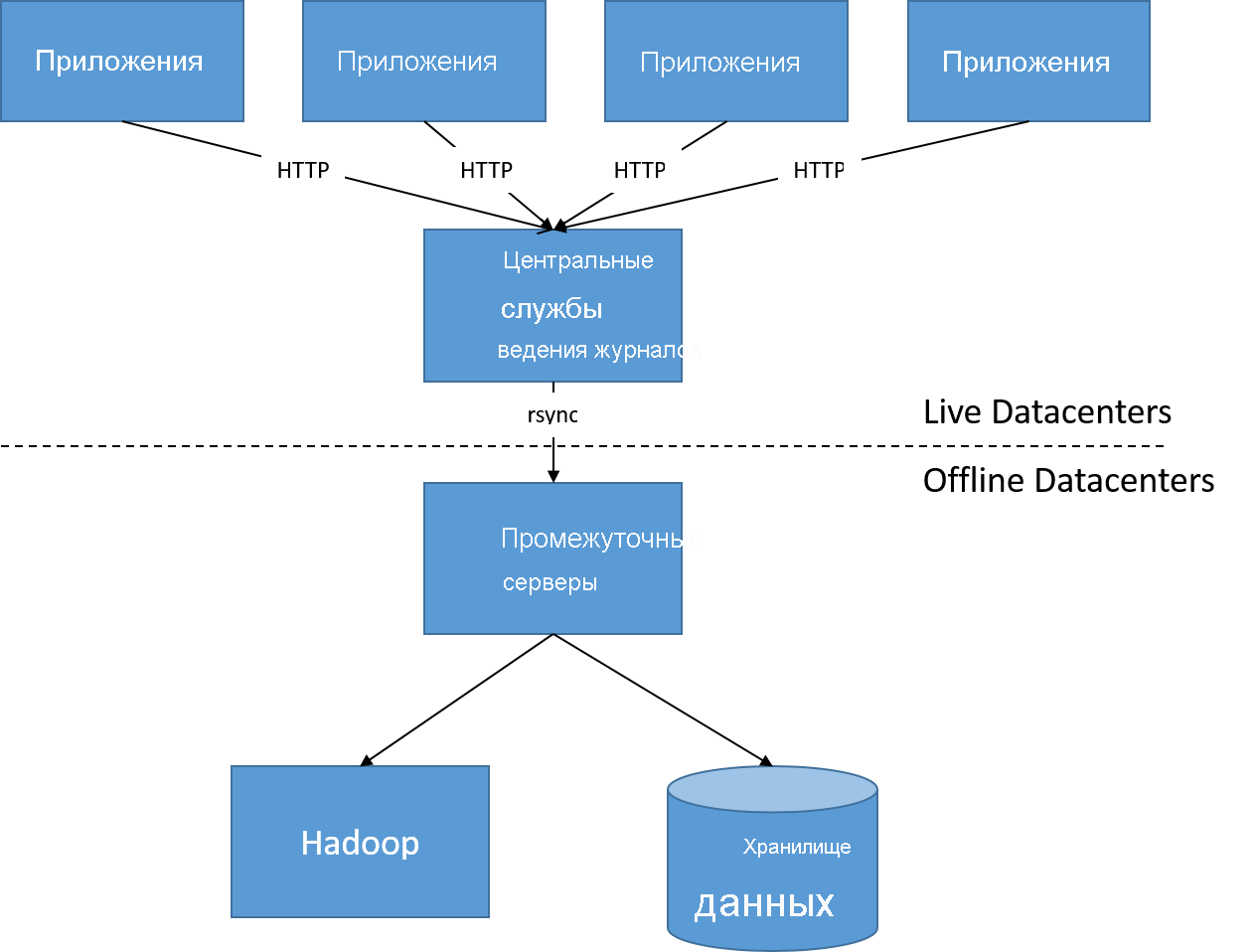
Рис. 22. Перед автономной обработкой журналов действий пользователей
Со временем задержки в несколько часов стали недопустимы ни для пользователей, которые хотели знать статистику просмотра их страниц и тенденции за последние пять минут, ни для рекламодателей и аналитиков данных, которым нужна была возможность отображать необходимую информацию в режиме реального времени. Показ объявлений перестал опираться только на автономный анализ потоков кликов в хранилищах данных и стал все больше зависеть от моделей реального времени, обновляемых онлайн.
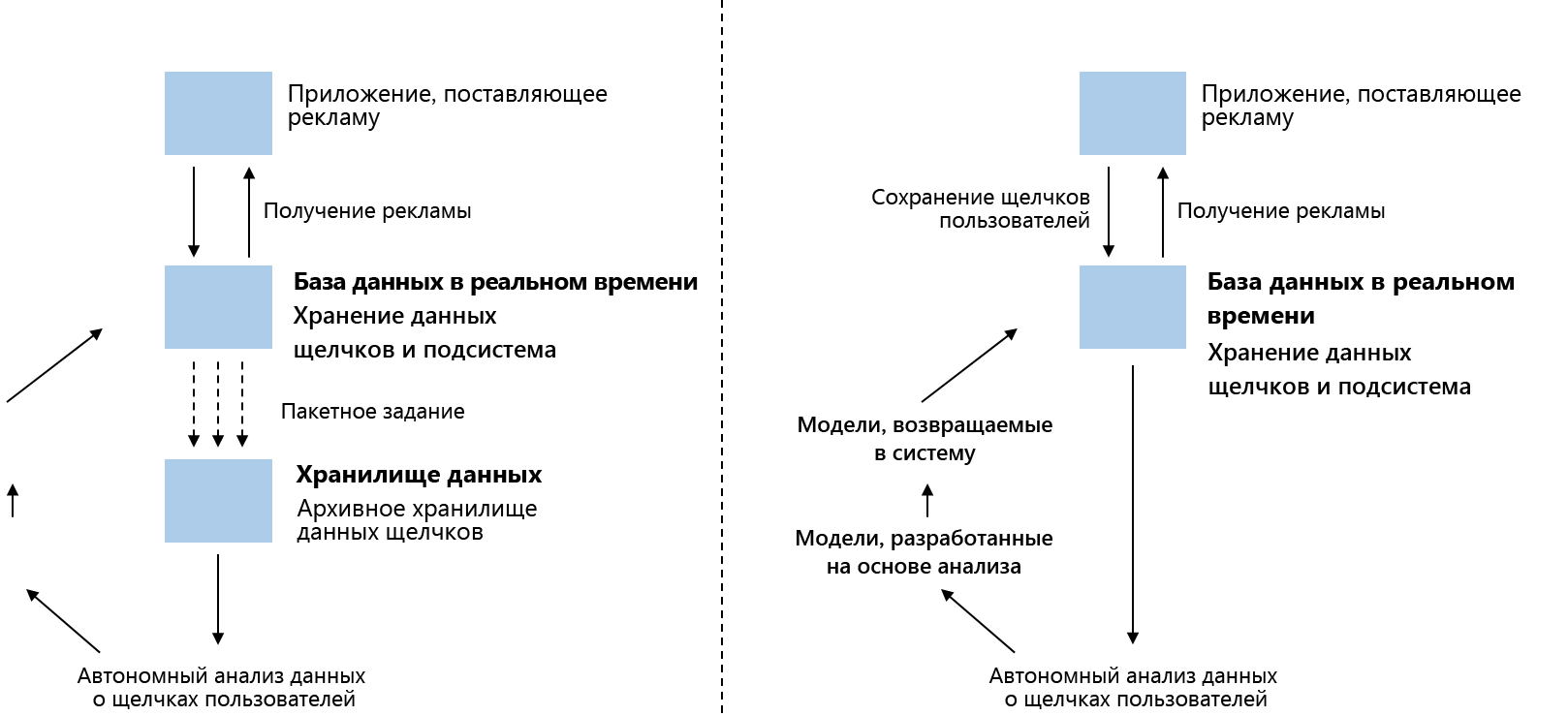
Рис. 23. Слева: традиционная доставка рекламы. Право: модель рекламной службы.
Этого позволяет добиться потоковая передача с отслеживанием состояния на базе Samza. Раньше источником достоверных данных всегда было одно из центральных хранилищ данных. Однако базы данных не могут обслуживать такое большое количество одновременных запросов, которого требует соотнесение комплексных запросов рекомендаций в режиме реального времени и комплексных аналитических систем. Кроме того, это требует от центра обработки данных большой пропускной способности сечения. Вместо этого компания LinkedIn решила использовать один и тот же поток данных для обновления сразу нескольких серверов. За счет того, что каждый потребительский узел имел свою локальную встроенную базу данных, одно-единственное событие обновления просто запускало все соответствующие обновления в такой локальной базе данных в режиме реального времени.
Ниже показан простой пример события обновления для профиля пользователя. Когда профиль обновляется, добавляется запись в соответствующую тему UserProfileUpdate, которая считывается каналом новостей (чтобы сообщить о переходе пользователя в другую компанию в режиме реального времени) и хранилищем данных для поиска (чтобы не выдавать устаревшие данные), а также используется для автономной обработки (например, для выявления тенденций по количеству разработчиков программного обеспечения, присоединяющихся к определенной компании в день).
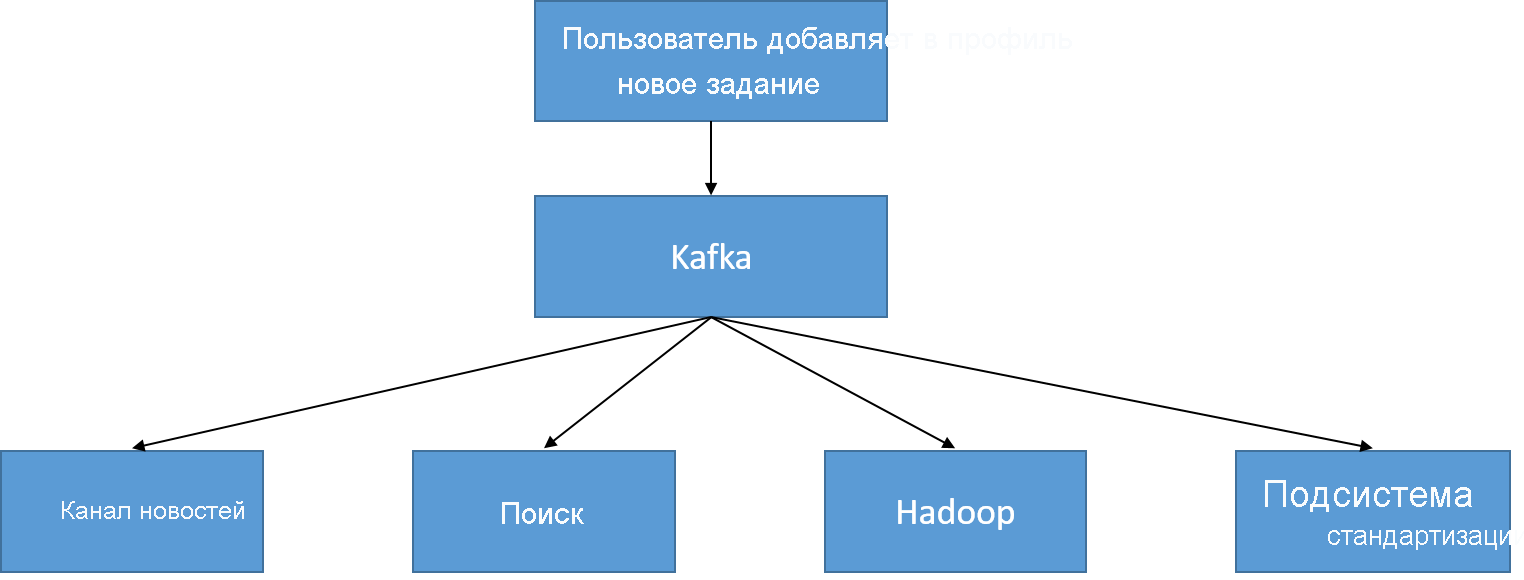
Рис. 24. Раздел UserProfileUpdate используется в LinkedIn
При работе с такими крупными распределенными веб-системами, как во многих технологических гигантах, в проектных решениях возникает парадокс. Эти компании создали большое количество специализированных систем, таких как хранилища данных, сетевые соединения, платформы для пакетной, интерактивной и потоковой обработки и так далее. Это связано с тем, что прошлые универсальные решения больше не отвечают специфическим жестким требованиям современных пользователей. Однако у такого подхода есть недостаток — многочисленные попытки "изобрести колесо", разработать индивидуальные решения для таких проблем, как обнаружение неполадок, восстановление и управление кластерами. Движение к таким системам стимулируется, в первую очередь, необходимостью гибкости, простоты управления и масштабируемости.
Кратко говоря, понятно, какие преимущества дал LinkedIn переход на систему, ориентированную на ведение журналов. Он позволил упростить неструктурированную работу и интеграцию данных. Организовав масштабируемое пропускание сообщений журналов через объект первого класса в центре обработки данных, компания LinkedIn построила модульную, гибкую систему.