Подготовка и преобразование данных в Azure Synapse Analytics
С помощью задачи потока данных для сопоставления можно собственными средствами выполнять преобразования данных с использованием конвейеров Azure Synapse без единой строчки кода. Потоки данных для сопоставления осуществляются в полностью визуальном интерфейсе без единой строчки кода. Потоки данных будут выполняться в вашем собственном кластере выполнения для обработки данных с горизонтальным увеличением масштаба. Действия потока данных можно применять через уже существующие средства планирования, управления, потока и мониторинга в Фабрике данных.
При создании потоков данных можно включить режим отладки, который включает небольшой интерактивный кластер Spark. Чтобы включить режим отладки, используйте соответствующий переключатель в верхней части модуля разработки. Отладка кластеров занимает несколько минут, однако ее можно использовать для интерактивного предварительного просмотра выходных данных логики преобразования.

После добавления потока данных для сопоставления и запуска кластера Spark вы сможете выполнить преобразование, а также запустить и просмотреть данные. Вам не потребуется вводить ни единой строчки кода — Фабрика данных Azure сама обрабатывает все преобразование кода, оптимизацию пути и выполнение заданий потока данных.
Добавление исходных данных в поток данных для сопоставления
Откройте холст потока данных для сопоставления. Нажмите кнопку "Добавить источник" на холсте потока данных. В раскрывающемся списке исходных данных выберите источник (в этом примере — набор данных ADLS 2-го поколения)
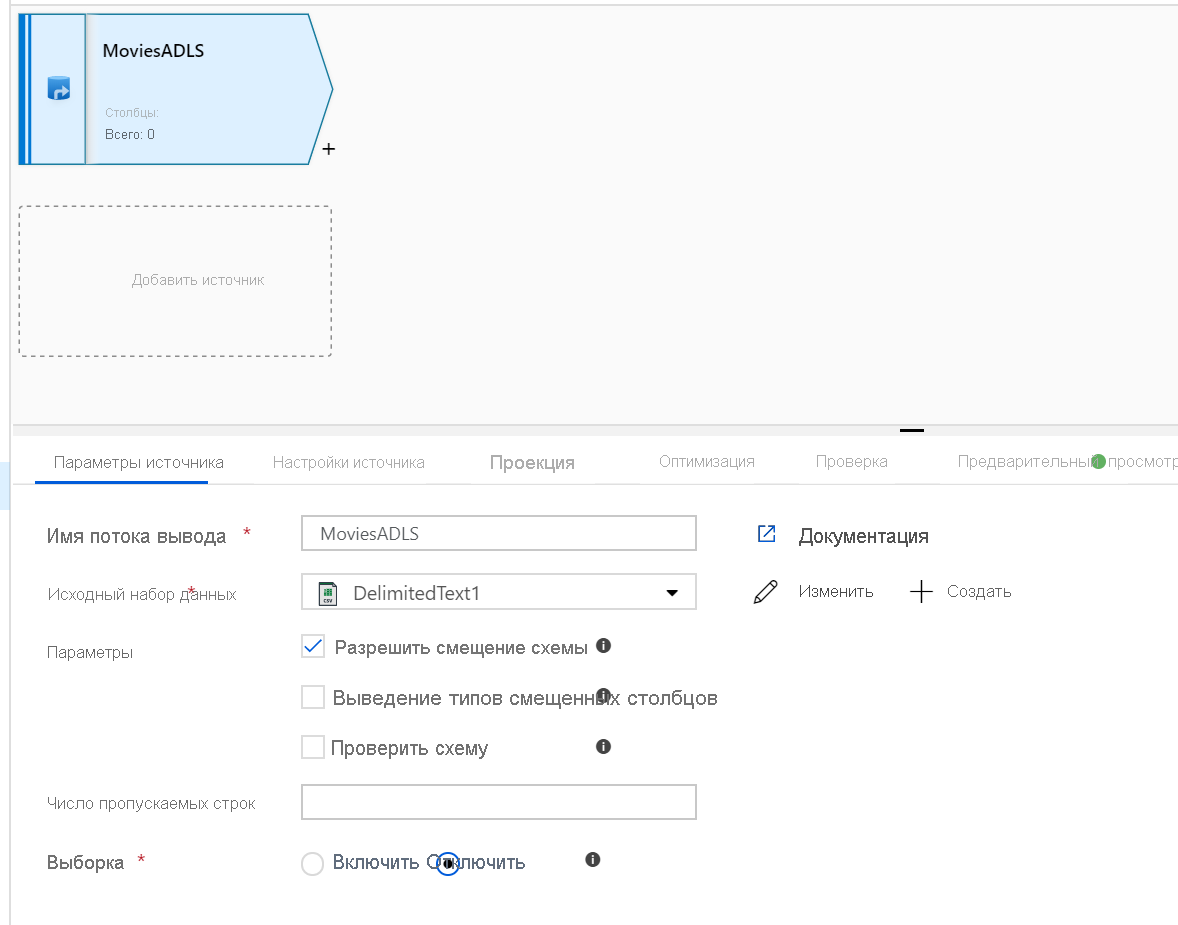
Обратите внимание на несколько моментов.
- Если набор данных указывает на папку с другими файлами и необходимо использовать только один файл, может потребоваться создать другой набор данных или использовать параметризацию, чтобы гарантировать чтение только определенного файла.
- Если вы не импортировали схему в ADLS, но уже получили данные, перейдите на вкладку "Схема" набора данных и нажмите кнопку "Импорт схемы", чтобы поток данных знал о проекции схемы.
Поток данных для сопоставления соответствует подходу "извлечение, загрузка и преобразование" (ELT) и работает с промежуточными наборами данных, которые находятся в Azure. В настоящее время в преобразовании источника можно использовать следующие наборы данных:
- хранилище BLOB-объектов Azure (JSON, Avro, текстовый формат, Parquet);
- Azure Data Lake Storage 1-го поколения (JSON, Avro, текстовый формат, Parquet);
- Azure Data Lake Storage 2-го поколения (JSON, Avro, текстовый формат, Parquet);
- Azure Synapse Analytics
- База данных SQL Azure
- Azure Cosmos DB
Фабрике данных Azure доступно более 80 собственных соединителей. Чтобы включить в поток данных данные из этих других источников, используйте действие копирования для загрузки данных в одну из поддерживаемых промежуточных областей.
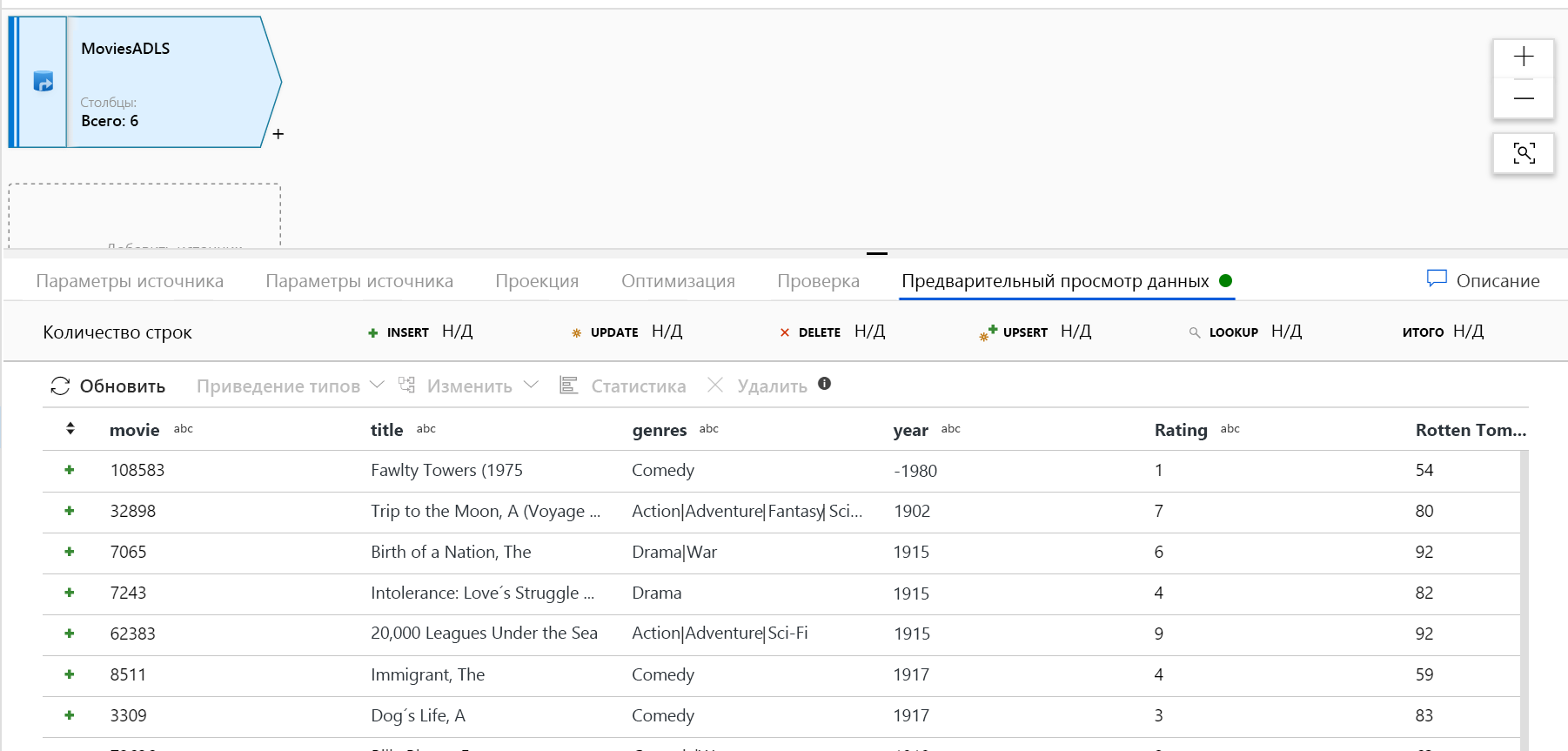
После разогрева кластера отладки убедитесь, что данные загружаются правильно с помощью вкладки "Предварительный просмотр данных". После нажатия кнопки обновления сопоставление Поток данных отобразит моментальный снимок того, как выглядят данные при каждом преобразовании.
Использование преобразований в потоке данных для сопоставления
Теперь, когда данные перемещены в Azure Data Lake Store 2-го поколения, можно приступать к созданию потока данных для сопоставления, который будет преобразовывать данные в масштабе через кластер Spark, а затем загружать их в хранилище данных.
Ниже перечислены основные задачи в рамках этого процесса.
Подготовка среды
Добавление источника данных
Использование преобразования потока данных для сопоставления
Запись в приемник данных
Задача 1. Подготовка среды
Включите отладку потока данных. Для этого воспользуйтесь переключателем Отладка потока данных в верхней части модуля разработки.
Примечание.
Подготовка кластеров потока данных занимает 5–7 минут.
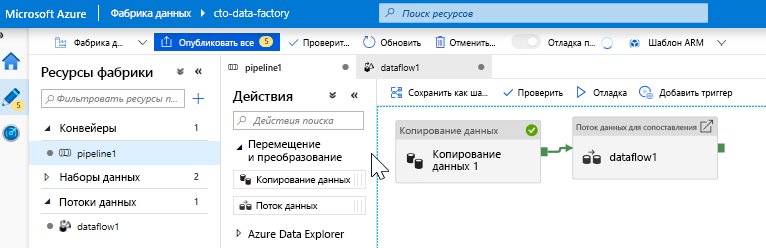
Добавьте действие потока данных. На панели действий на холсте конвейера откройте меню-гармошку "Перемещение и преобразование" и перетащите действие Поток данных на холст конвейера. В появившейся колонке щелкните Создать новый поток данных и выберите Поток данных для сопоставления, а затем нажмите кнопку ОК. Перейдите на вкладку pipeline1 и перетащите зеленую рамку из действия копирования в действие потока данных, чтобы создать условие успешного выполнения. Холст будет выглядеть следующим образом.
Задача 2. Добавление источника данных
Добавьте источник ADLS. Дважды щелкните объект потока данных для сопоставления на холсте. Нажмите кнопку "Добавить источник" на холсте потока данных. В раскрывающемся списке Исходный набор данных выберите набор данных ADLSG2, используемый в действии копирования.
- Если набор данных указывает на папку с другими файлами, может потребоваться создать другой набор данных или использовать параметризацию, чтобы гарантировать считывание только файла moviesDB.csv.
- Если вы не импортировали схему в ADLS, но уже получили данные, перейдите на вкладку "Схема" набора данных и нажмите кнопку "Импорт схемы", чтобы поток данных знал о проекции схемы.
После разогрева кластера отладки убедитесь, что данные загружаются правильно с помощью вкладки "Предварительный просмотр данных". После нажатия кнопки обновления сопоставление Поток данных отобразит моментальный снимок того, как выглядят данные при каждом преобразовании.
Задача 3. Использование преобразования потока данных для сопоставления
Добавьте преобразование "Выбор" для переименования и удаления столбца. При предварительном просмотре данных вы могли заметить, что название столбца Rotton Tomatoes написано неправильно. Чтобы присвоить ему правильное имя и удалить неиспользуемый столбец Rating (Рейтинг), можно добавить Преобразование "Выбор", щелкнув значок "+" рядом с исходным узлом ADLS и выбрав пункт "Выбор" в разделе "Модификатор схемы".
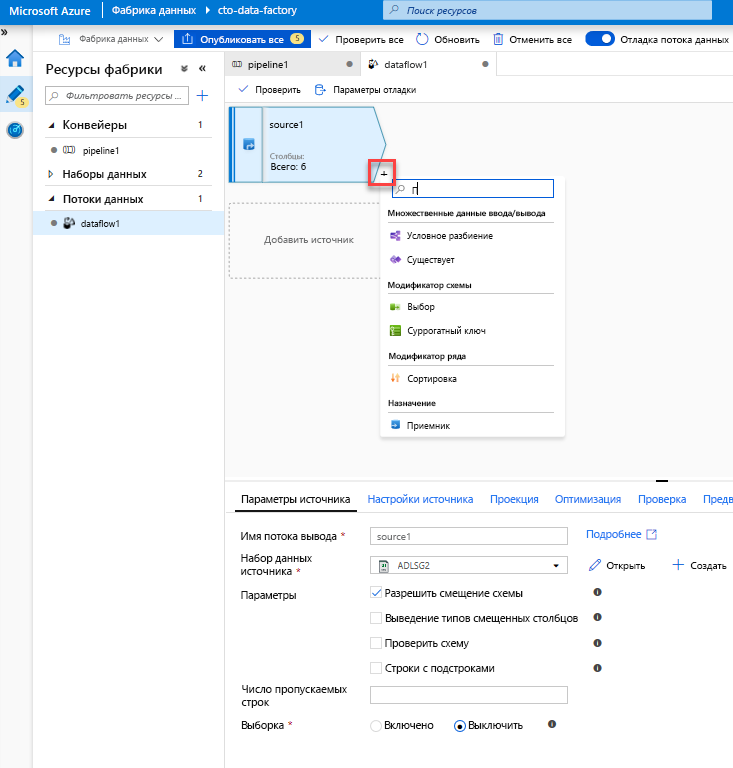
В поле Имя измените Rotton на Rotten. Чтобы удалить столбец Rating (Рейтинг), наведите на него указатель мыши и щелкните значок корзины.
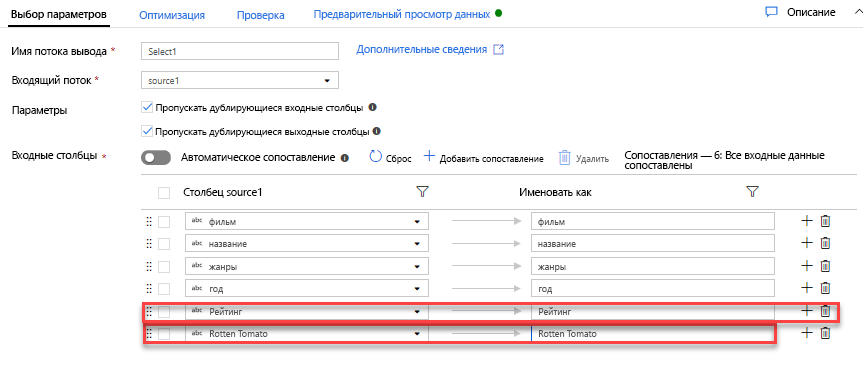
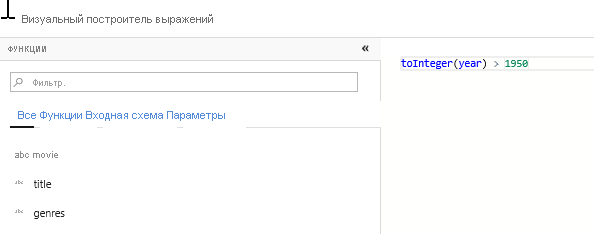
Добавьте преобразование "Фильтр", чтобы отфильтровать нежелательные годы. Скажем, вас интересуют только фильмы, снятые после 1951 г. Можно добавить Преобразование "Фильтр", чтобы указать условие фильтра, щелкнув значок "+" рядом с преобразованием "Выбор" и выбрав Фильтр в разделе "Модификатор строки". Щелкните поле выражения, чтобы открыть конструктор выражений и ввести условие фильтра. Синтаксис языка выражений потока данных для сопоставления, toInteger(year) > 1950, преобразует значение года строки в целое число и фильтрует строки, если это значение превышает "1950".
Для проверки правильности работы условия можно использовать встроенную область предварительного просмотра данных в конструкторе выражений.
Добавьте преобразование "Производное", чтобы вычислить основной жанр. Как вы могли заметить, столбец жанров является строкой, разделенной символом "|". Если вас интересует только первый жанр в каждом столбце, можно создать новый столбец с именем PrimaryGenre посредством преобразования Производный столбец, щелкнув значок "+" рядом с преобразованием "Фильтр" и выбрав пункт "Производное" в разделе "Модификатор схемы". Как и в случае с преобразованием "Фильтр", производный столбец использует конструктор выражений потока данных для сопоставления для указания значений нового столбца.

В этом сценарии вы пытаетесь извлечь первый жанр из столбца жанров, который имеет формат "жанр1|жанр2|...|жанрN". Используйте функцию locate, чтобы получить первый индекс "|", отсчитываемый от 1, в строке жанров. При использовании функции iif, если этот индекс больше 1, основной жанр можно вычислить с помощью функции left, которая возвращает все символы в строке слева от индекса. В противном случае значение PrimaryGenre будет равно значению в поле жанров. Проверить выходные данные можно с помощью области предварительного просмотра данных в конструкторе выражений.
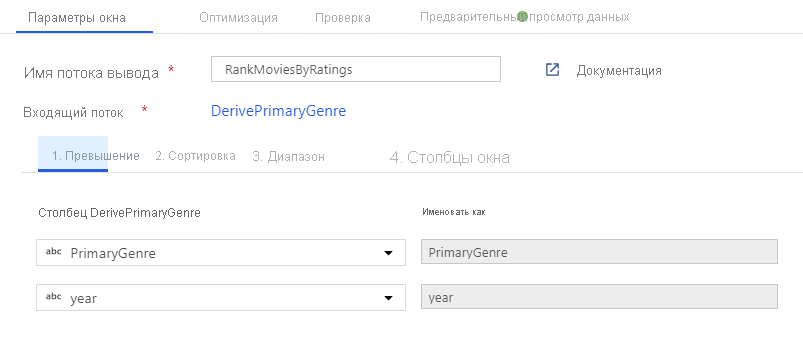
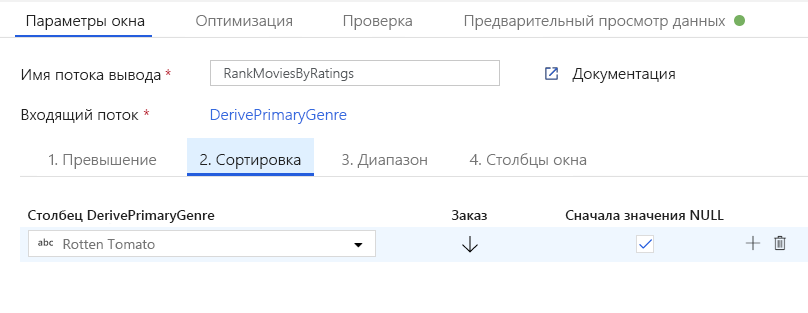
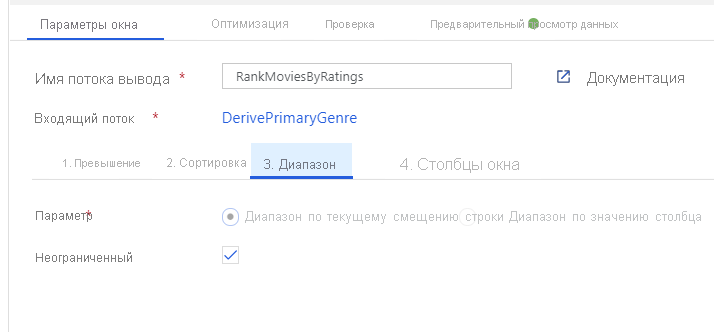
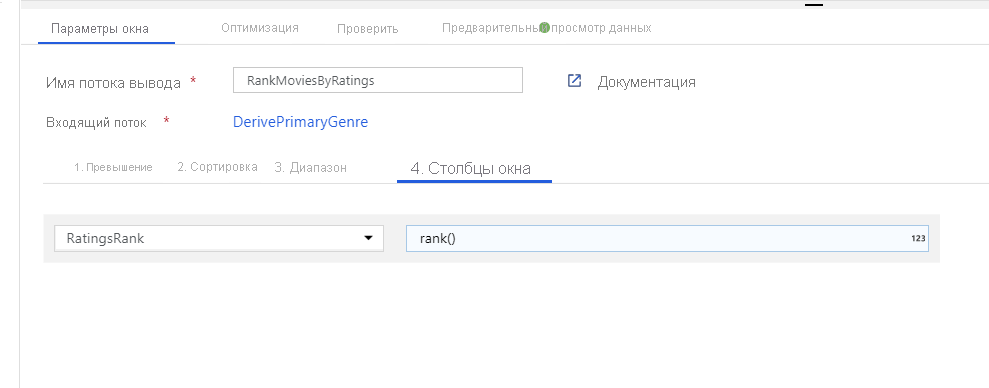
Присвойте фильмам рейтинг с помощью преобразования "Окно". Предположим, что вас интересует рейтинг фильма в его жанре в год его производства. Можно добавить преобразование "Окно" для определения агрегатов, основанных на окне, щелкнув значок "+" рядом с преобразованием "Производный столбец" и выбрав пункт "Окно" в разделе "Модификатор схемы". Для этого укажите окно, условие сортировки, диапазон и способ вычисления столбцов нового окна. В этом примере нас интересует окно по PrimaryGenre и год с неограниченным диапазоном, сортировка Rotten Tomato по убыванию и вычисление нового столбца с именем RatingsRank, соответствующего рейтингу каждого фильма в своем жанре в году его производства.
Агрегируйте рейтинги с помощью преобразования "Статистическая обработка". Теперь, когда вы собрали все необходимые данные и создали производные, можно добавить Преобразование "Статистическая обработка" для вычисления метрик на основе нужной группы, щелкнув значок "+" рядом с преобразованием "Окно" и выбрав пункт "Статистическая обработка" в разделе "Модификатор схемы". Как и в случае с преобразованием "Окно", давайте сгруппируем фильмы по PrimaryGenre и году.
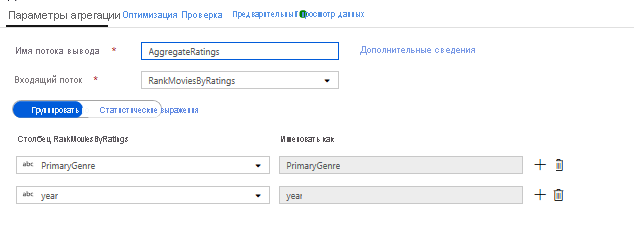
На вкладке "Агрегаты" можно просмотреть статистические выражения, вычисленные на основе определенных столбцов группировки. Для каждого жанра и года необходимо получить средний рейтинг Rotten Tomatoes, самый высокий и самый низкий рейтинг фильма (с использованием функции окон) и количество фильмов в каждой группе. Статистическая обработка значительно сокращает количество строк в вашем потоке преобразования и распространяет только столбцы группировки и статистической обработки, указанные в преобразовании.
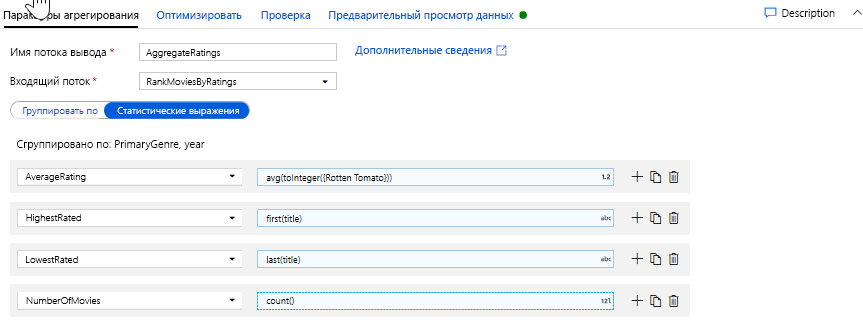
- Чтобы увидеть, как изменяются данные в результате преобразования "Статистическая обработка", перейдите на вкладку "Просмотр данных".
Укажите условие Upsert с помощью преобразования "Изменение строки". При записи в табличный приемник можно указать политики вставки, удаления и обновления для строк с помощью преобразования "Изменение строки", щелкнув значок "+" рядом с преобразованием "Статистическая обработка" и выбрав пункт "Изменение строки" в разделе "Модификатор строки". Поскольку вы всегда вставляете и обновляете данные, можно указать, что все строки всегда будут вставляться с помощью операции upsert.

Задача 4. Запись в приемник данных
- Запишите данные в приемник Azure Synapse Analytics. Теперь, когда вы завершили всю логику преобразования, можно приступать к записи в приемник.
Добавьте приемник, щелкнув значок "+" рядом с преобразованием Upsert и выбрав "Приемник" в разделе "Назначение".
На вкладке "Приемник" создайте новый набор данных хранилища данных с помощью кнопки "+ Создать".
В списке плиток выберите Azure Synapse Analytics.
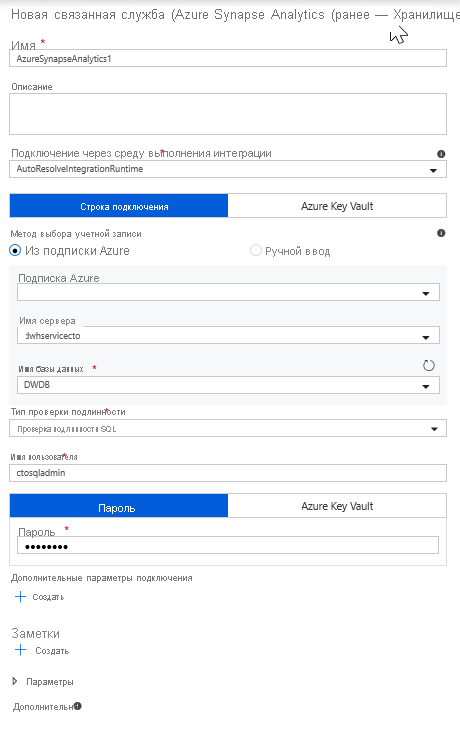
Выберите новую связанную службу и настройте подключение Azure Synapse Analytics для подключения к базе данных базе DWDB, созданной в модуле 5. После завершения нажмите Создать.
В конфигурации набора данных выберите Создать новую таблицу и введите в схеме dbo и имя таблицы Ratings. После завершения операции нажмите кнопку ОК.
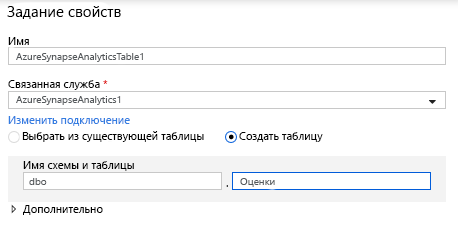
Поскольку было указано условие upsert, необходимо открыть вкладку "Параметры" и выбрать "Разрешить upsert" на основе ключевых столбцов PrimaryGenre и года.
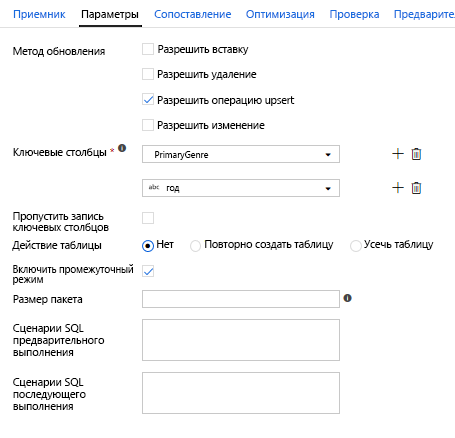
На этом этапе создание потока данных для сопоставления, включающего 8 преобразований, завершено. Пора запустить конвейер и просмотреть результаты!

Задача 5. Запуск конвейера
Перейдите на вкладку "pipeline1" на холсте. Поскольку Azure Synapse Analytics в потоке данных использует PolyBase, необходимо указать большой двоичный объект или промежуточную папку ADLS. На вкладке параметров действия "Выполнить поток данных" откройте меню-гармошку "PolyBase" и выберите связанную службу ADLS, а также укажите путь к промежуточной папке.
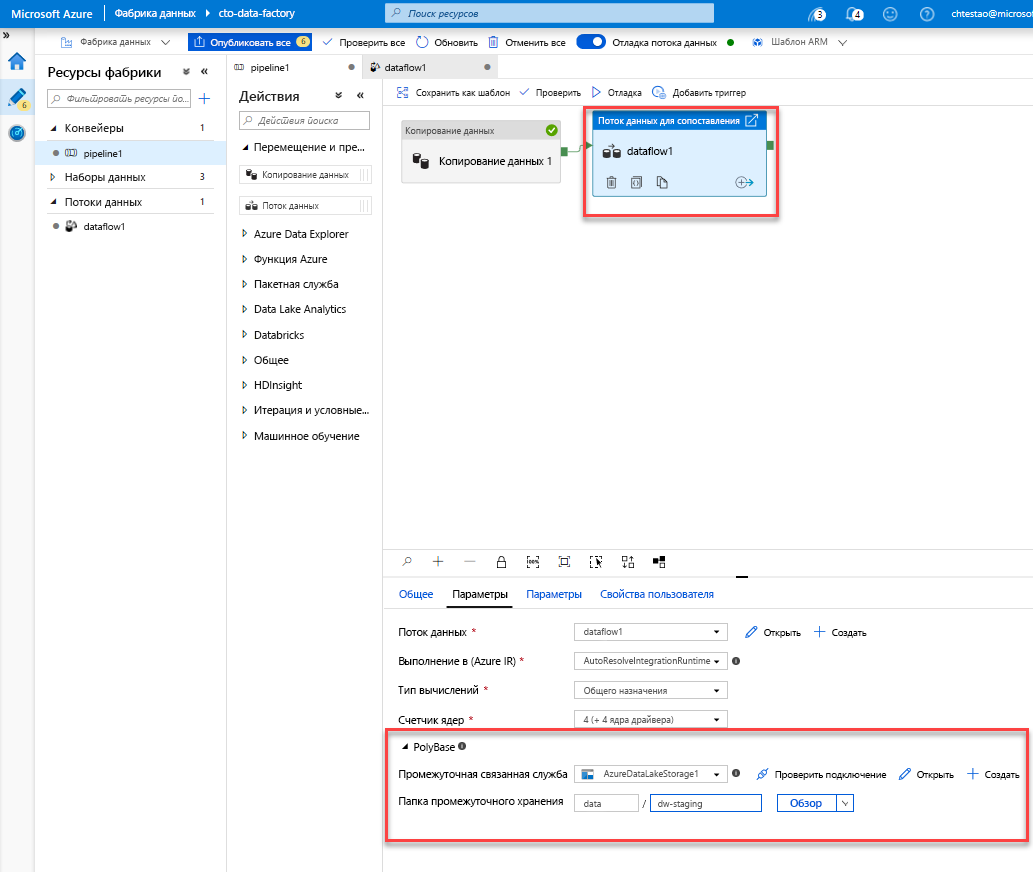
Перед публикацией конвейера запустите еще одну отладку, чтобы убедиться, что он работает правильно. На вкладке "Вывод" можно отслеживать состояние обоих действий по мере их выполнения.
После того как оба действия выполнены успешно, можно щелкнуть значок очков рядом с действием потока данных, чтобы получить более подробные сведения о выполнении потока данных.
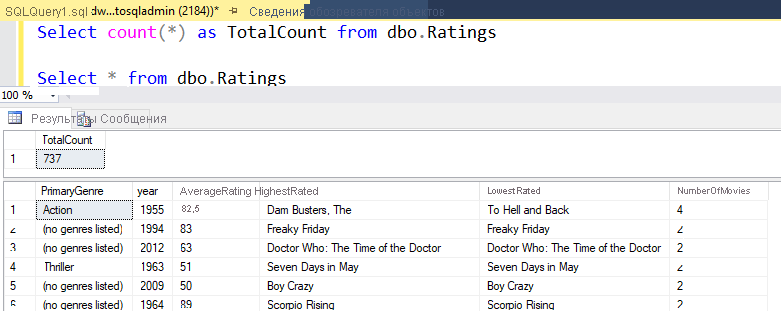
Если вы использовали ту же логику, которая описана в этом задании, поток данных запишет 737 строк в хранилище SQL. Можно перейти в SQL Server Management Studio, чтобы убедиться, что конвейер сработал правильно, и узнать, что было записано.