Что такое машинное обучение?
Машинное обучение имеет свое происхождение в статистике и математическом моделировании данных. Основная идея машинного обучения заключается в использовании данных из прошлых наблюдений для прогнозирования неизвестных результатов или значений. Например:
- Владелец магазина мороженого может использовать приложение, которое объединяет исторические продажи и погодные записи, чтобы предсказать, сколько мороженого они, скорее всего, будут продаваться в течение определенного дня на основе прогноза погоды.
- Врач может использовать клинические данные от прошлых пациентов для выполнения автоматизированных тестов, которые прогнозируют, подвержен ли новый пациент риску от диабета на основе таких факторов, как вес, уровень глюкозы крови и другие измерения.
- Исследователь в Антарктиде может использовать прошлые наблюдения автоматизирует идентификацию различных видов пингвинов (таких как Adelie, Gentoo или Chinstrap) на основе измерений птичьих ласт, счета и других физических атрибутов.
Машинное обучение в качестве функции
Так как машинное обучение основано на математике и статистике, обычно речь идет о моделях машинного обучения в математических терминах. По сути, модель машинного обучения — это программное приложение, инкапсулирующее функцию для вычисления выходного значения на основе одного или нескольких входных значений. Процесс определения этой функции называется обучением. После определения функции его можно использовать для прогнозирования новых значений в процессе, называемом выводом.
Давайте рассмотрим шаги, связанные с обучением и выводом.
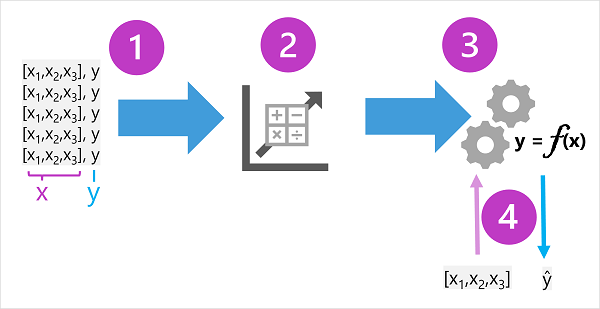
Данные обучения состоят из прошлых наблюдений. В большинстве случаев наблюдения включают в себя наблюдаемые атрибуты или признаки наблюдаемого объекта, а также его известное значение, для прогнозирования которого вы хотите обучить модель (известное как метка).
В математических терминах часто отображаются функции, называемые сокращенным именем переменной x, и метка, называемая y. Обычно наблюдение состоит из нескольких значений признаков, поэтому x фактически является вектором(массив с несколькими значениями), как показано ниже: [x1,x 2,x 3,...].
Чтобы сделать это более понятным, рассмотрим примеры, описанные ранее:
- В сценарии продаж мороженого наша цель заключается в обучении модели, которая может предсказать количество продаж мороженого на основе погоды. Погодные измерения для дня (температура, осадки, ветер и т. д.) будут признаками (x), а количество мороженого, проданных в каждый день, будет меткой (y).
- В медицинском сценарии цель заключается в прогнозировании того, подвержен ли пациент риску развития диабета на основе его клинических измерений. Измерения пациента (вес, уровень глюкозы крови и т. д.) являются признаками (x), а вероятность диабета (например, 1 для риска, 0 для не подверженного риску) является меткой (y).
- В сценарии исследования Антарктиды мы хотим предсказать вид пингвина на основе его физических особенностей. Ключевые измерения пингвина (длина его ласт, ширина счета и т. д.) являются признаками (x), а виды (например, 0 для Adelie, 1 для Gentoo или 2 для Chinstrap) является меткой (y).
Алгоритм применяется к данным, чтобы попытаться определить связь между функциями и меткой, и обобщить эту связь как вычисление, которое можно выполнить на x для вычисления y. Используемый алгоритм зависит от типа прогнозной проблемы, которую вы пытаетесь решить (подробнее об этом позже), но основной принцип заключается в том, чтобы попытаться вписать функцию в данные, в которой значения функций можно использовать для вычисления метки.
Результатом алгоритма является модель, которая инкапсулирует вычисление, полученное алгоритмом в качестве функции, — давайте вызовем его f. В математической нотации:
y = f(x)
Теперь, когда фаза обучения завершена, обученную модель можно использовать для вывода. Модель — это, по сути, программное обеспечение, которое инкапсулирует функцию, полученную в процессе обучения. Вы можете ввести набор значений признаков и получить в качестве вывода прогноз соответствующей метки. Так как выходные данные модели — это прогноз, вычисляемый функцией, а не наблюдаемое значение, вы часто увидите выходные данные функции, показанные как ŷ (это довольно восхитительно словесно, как "y-hat").