Регрессия
Замечание
Дополнительные сведения см. на вкладке "Текст и изображения ".
Модели регрессии обучены прогнозировать числовые значения меток на основе обучающих данных, которые включают как функции, так и известные метки. Процесс обучения модели регрессии (или, действительно, любой защищенной модели машинного обучения) включает несколько итераций, в которых используется соответствующий алгоритм (обычно с некоторыми параметризованными параметрами) для обучения модели, оценки прогнозной производительности модели и уточнения модели путем повторения процесса обучения с различными алгоритмами и параметрами, пока вы не достигнете приемлемого уровня прогнозной точности.
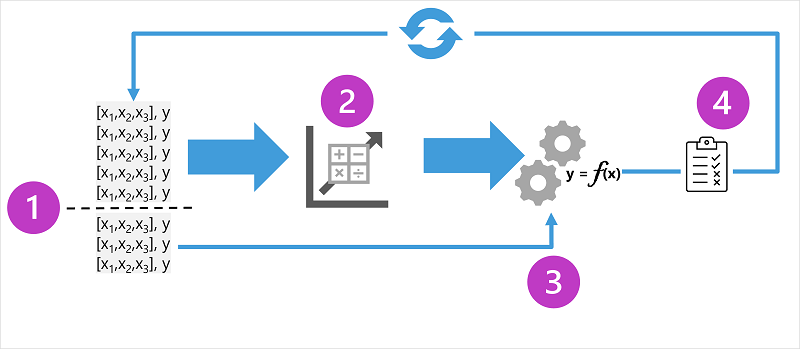
На схеме показаны четыре основных элемента процесса обучения для защищенных моделей машинного обучения:
- Разделите обучающие данные (случайным образом) для создания набора данных, с помощью которого модель будет обучаться, отложив подмножество данных, которые будут использоваться для проверки обученной модели.
- Используйте алгоритм для соответствия обучающих данных модели. В случае модели регрессии используйте алгоритм регрессии, например линейную регрессию.
- Используйте данные валидации, которые вы отложили, чтобы протестировать модель, прогнозируя метки для признаков.
- Сравните известные фактические метки в наборе данных проверки с метками, прогнозируемыми моделью. Затем агрегируют различия между прогнозируемыми и фактическими значениями меток, чтобы вычислить метрику, которая указывает, насколько точно модель прогнозировала данные проверки.
После каждого обучения, проверки и оценки итерации можно повторить процесс с различными алгоритмами и параметрами до достижения приемлемой метрики оценки.
Пример — регрессия
Рассмотрим регрессию с упрощенным примером, в котором мы обучим модель для прогнозирования числовых меток (y) на основе одного значения признаков (x). Большинство реальных сценариев включают несколько значений признаков, что приводит к некоторой сложности. но принцип тот же.
В нашем примере мы будем придерживаться сценария продаж мороженого, который мы обсуждали ранее. Для нашей функции мы рассмотрим температуру (предположим, что это значение является максимальной температурой в данный день), и меткой, которую мы хотим, чтобы модель предсказывала, является количество проданных в тот день мороженых. Начнем с некоторых исторических данных, которые включают записи о ежедневных температурах (x) и продажах мороженого (y):

|

|
|---|---|
| Температура (x) | Продажи мороженого (y) |
| 51 | 1 |
| 52 | 0 |
| 67 | 14 |
| 65 | 14 |
| 70 | двадцать три |
| 69 | 20 |
| 72 | двадцать три |
| 75 | 26 |
| 73 | двадцать два |
| восемьдесят один | 30 |
| 78 | 26 |
| 83 | 36 |
Обучение модели регрессии
Начнем с разделения данных и использования подмножества для обучения модели. Вот набор данных для обучения:
| Температура (x) | Продажи мороженого (y) |
|---|---|
| 51 | 1 |
| 65 | 14 |
| 69 | 20 |
| 72 | двадцать три |
| 75 | 26 |
| восемьдесят один | 30 |
Чтобы получить представление о том, как эти значения x и y могут быть связаны друг с другом, мы можем представить их как координаты вдоль двух осей, как показано ниже:
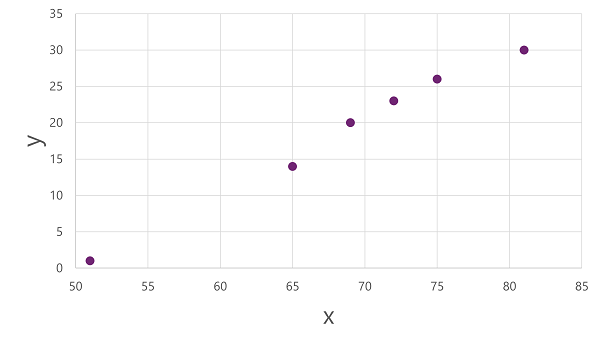
Теперь мы готовы применить алгоритм к данным обучения и поместить его в функцию, которая применяет операцию к x для вычисления y. Один из таких алгоритмов — линейная регрессия, которая работает путем получения функции, которая создает прямую линию через пересечения значений x и y при минимизации среднего расстояния между линией и графиками точек, как показано ниже:
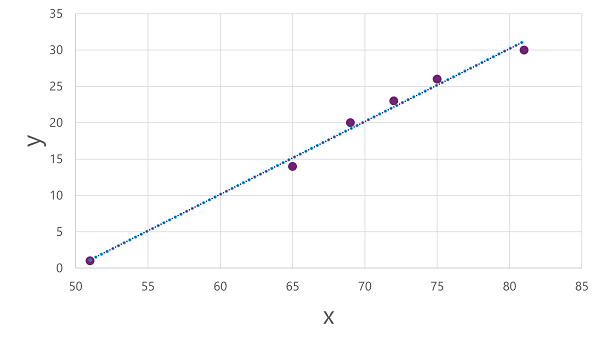
Строка представляет собой визуальное представление функции, в которой наклон строки описывает вычисление значения y для заданного значения x. Линия перехватывает ось x в 50, поэтому если x равно 50, y — 0. Как видно из маркеров оси на графике, линия наклонена так, что каждое увеличение на 5 вдоль оси x приводит к увеличению на 5 по оси y; таким образом, если x равно 55, y равно 5; когда x равно 60, y — 10, и так далее. Чтобы вычислить значение y для заданного значения x, функция просто вычитает 50; Другими словами, функцию можно выразить следующим образом:
f(x) = x-50
Эту функцию можно использовать для прогнозирования количества мороженого, проданного в день с любой заданной температурой. Например, предположим, прогноз погоды говорит нам, что завтра это будет 77 градусов. Мы можем применить нашу модель, чтобы вычислить 77-50 и предсказать, что мы будем продавать 27 мороженого завтра.
Но насколько точно наша модель?
Оценка модели регрессии
Чтобы проверить модель и оценить, насколько хорошо она прогнозирует, мы удержали некоторые данные, чьи метки (y) нам известны. Вот данные, которые мы удержали:
| Температура (x) | Продажи мороженого (y) |
|---|---|
| 52 | 0 |
| 67 | 14 |
| 70 | двадцать три |
| 73 | двадцать два |
| 78 | 26 |
| 83 | 36 |
Мы можем использовать модель для прогнозирования метки для каждого наблюдения в этом наборе данных на основе значения функции (x); а затем сравните прогнозируемую метку (ŷ) с известным фактическим значением метки (y).
Использование модели, которую мы обучили ранее, которая инкапсулирует функцию f(x) = x-50, приводит к следующим прогнозам:
| Температура (x) | Фактические продажи (y) | Прогнозируемые продажи (ŷ) |
|---|---|---|
| 52 | 0 | 2 |
| 67 | 14 | 17 |
| 70 | двадцать три | 20 |
| 73 | двадцать два | двадцать три |
| 78 | 26 | 28 |
| 83 | 36 | 33 |
Мы можем построить график как прогнозируемых, так и фактических меток на основе значений признаков, как показано ниже:
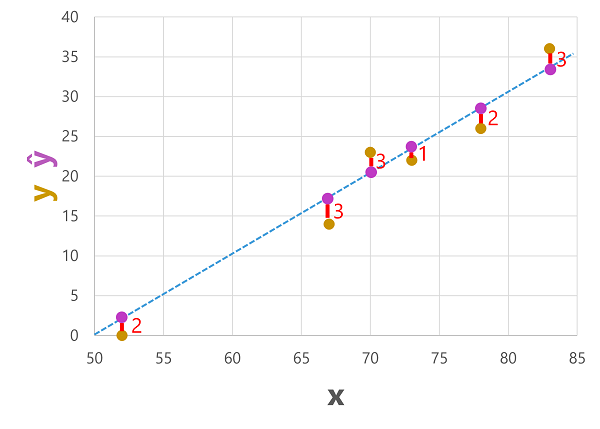
Прогнозируемые метки вычисляются моделью, поэтому они находятся на линии функции. Однако между значениями ŷ, вычисляемыми функцией, и фактическими значениями y из набора данных проверки существует некоторое отклонение. Это на графике отображается линией между значениями ŷ и y, показывающей, насколько предсказание отклонилось от фактического значения.
Метрики оценки регрессии
На основе различий между прогнозируемыми и фактическими значениями можно вычислить некоторые распространенные метрики, используемые для оценки модели регрессии.
Средняя абсолютная погрешность (MAE)
Дисперсия в этом примере показывает, насколько количество мороженого в каждом прогнозе отличается от фактического значения. Это не имеет значения, если прогноз был превышен или под фактическим значением (например, -3 и +3 оба указывают на дисперсию 3). Эта метрика называется абсолютной ошибкой для каждого прогноза и может быть обобщена для всего набора проверки в виде средней абсолютной ошибки (MAE).
В примере мороженого среднее (среднее) абсолютных ошибок (2, 3, 3, 1, 2 и 3) равно 2,33.
Средняя квадратная ошибка (MSE)
Средняя абсолютная метрика ошибок принимает все несоответствия между прогнозируемыми и фактическими метками в равной степени. Тем не менее, может быть более желательно иметь модель, которая последовательно ошибается на небольшую величину, чем модель, совершающая меньше, но более крупные ошибки. Один из способов создания метрики, которая "усилит" большие ошибки, сравляя отдельные ошибки и вычисляя среднее значение квадратных значений. Эта метрика называется среднеквадратической ошибкой (MSE).
В нашем примере мороженого среднее значение квадратных абсолютных значений (4, 9, 9, 1, 4 и 9) равно 6.
Корень среднеквадратической погрешности (RMSE)
Средняя квадратная ошибка помогает учитывать величину ошибок, но поскольку она квадратирует значения ошибок, результирующая метрика больше не представляет количество, измеряемое меткой. Другими словами, мы можем сказать, что MSE нашей модели составляет 6, но это не измеряет её точность с точки зрения количества неправильно предсказанных мороженых; 6 — это просто числовая оценка, указывающая уровень ошибки в прогнозах валидации.
Если мы хотим измерить ошибку с точки зрения количества мороженого, необходимо вычислить квадратный корень MSE; который создает метрику, называемую непреднамеретельно, корневой среднеквадратической ошибкой. В этом случае √6, что составляет 2,45 (мороженое).
Коэффициент определения (R2)
Все метрики до сих пор сравнивают несоответствие между прогнозируемыми и фактическими значениями, чтобы оценить модель. Однако в действительности в ежедневных продажах мороженого есть некоторые естественные случайные дисперсии, которые учитывает модель. В модели линейной регрессии алгоритм обучения соответствует прямой линии, которая сводит к минимуму среднее отклонение между функцией и известными значениями меток. Коэффициент определения (чаще называемый R2 или R-Squared) — это метрика, которая измеряет долю дисперсии в результатах проверки, которые можно объяснить моделью, в отличие от некоторых аномальных аспектов данных проверки (например, день с очень необычным количеством продаж мороженого из-за местного фестиваля).
Вычисление для R2 сложнее, чем для предыдущих метрик. Он сравнивает сумму квадратных различий между прогнозируемыми и фактическими метками с суммой квадратных различий между фактическими значениями меток и средним значением фактических значений меток, вот так:
R2 = 1- ∑(y-ŷ)2 ÷ ∑(y-ȳ)2
Не беспокойтесь слишком много, если это выглядит сложно; Большинство средств машинного обучения могут вычислить метрики для вас. Важно отметить, что результатом является значение от 0 до 1, описывающее долю дисперсии, объясняемой моделью. Проще говоря, чем ближе к 1 этому значению, тем лучше модель подходит для данных проверки. В случае модели регрессии мороженого R2 , вычисляемая из данных проверки, составляет 0,95.
Итеративное обучение
Описанные выше метрики обычно используются для оценки модели регрессии. В большинстве реальных сценариев специалист по обработке и анализу данных будет использовать итеративный процесс для многократного обучения и оценки модели, изменяющейся:
- Выбор компонентов и подготовка (выбор функций, которые следует включить в модель, и вычисления, применяемые к ним, чтобы обеспечить лучшее соответствие).
- Выбор алгоритма (мы изучили линейную регрессию в предыдущем примере, но есть много других алгоритмов регрессии).
- Параметры алгоритма (числовые параметры для управления поведением алгоритма, более точно называемые гиперпараметрами , чтобы отличить их от параметров x и y ).
После нескольких итераций выбирается модель, которая дает наилучшую метрику оценки, приемлемую для конкретного сценария.