Матрица смешения
Данные можно рассматривать как непрерывные, категориальные, порядковые (категориальные, но с порядком). Матрицы смешения — это средство оценки качества работы моделей категоризации. Чтобы получить контекст их работы, мы сначала обновим знания о непрерывных данных. Таким образом, мы видим, что матрицы смешения являются просто расширением уже известных гистограмм.
Распределение непрерывных данных
Когда мы хотим понять непрерывные данные, первый шаг часто заключается в том, чтобы узнать, как она распределена. Рассмотрим следующую гистограмму:
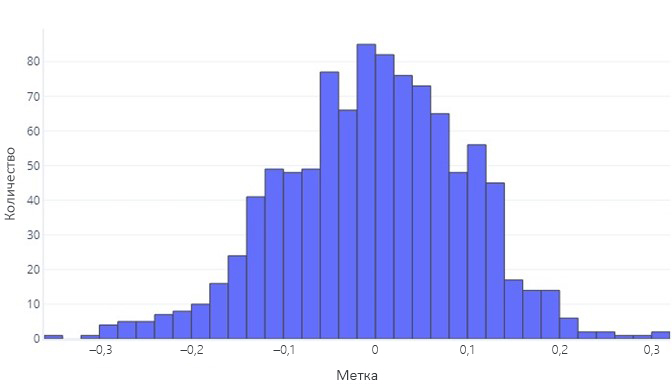
Мы видим, что метка в среднем, имеет значение около нуля, и большинство точек данных находятся в диапазоне от-1 до 1. Он появляется как симметричный; Есть приблизительно даже количество чисел меньше и больше, чем среднее. При желании мы могли бы использовать таблицу, а не гистограмму, но это может быть неудобно.
Распределение категорийных данных
В некоторых аспектах категорийные данные не так уж отличаются от непрерывных. Мы все еще можем создавать гистограммы, чтобы оценить, насколько часто отображаются значения для каждой метки. Например, двоичная метка (true/false) может отображаться со следующей частотой:
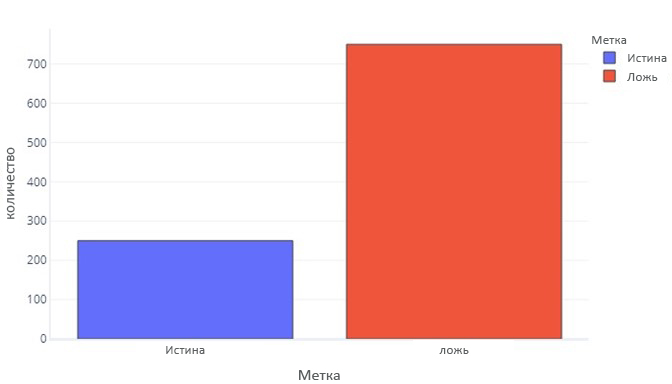
Это говорит нам, что есть 750 примеров с "false" как метка, и 250 с "true" в качестве метки.
Метка для трех категорий выглядит аналогично:
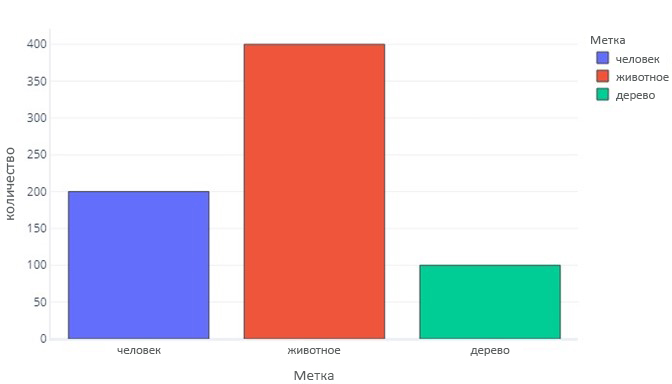
Это говорит нам, что есть 200 выборок, которые являются "person", 400, которые являются "животными", и 100, которые являются "деревом".
Как категориальные метки проще, мы часто можем показать их как простые таблицы. Два предыдущих графа будут выглядеть следующим образом:
| Подпись | False | Истина |
|---|---|---|
| Count | 750 | 250 |
И:
| Подпись | Лицо | Животное | декомпозиции |
|---|---|---|---|
| Count | 200 | 400 | 100 |
Анализ прогнозов
Мы можем проанализировать прогнозы, которые модель составляет так же, как мы добавляем эталонные метки в наших данных. Например, мы можем увидеть, что в тестовом наборе модели прогнозировали "false" 700 раз и "true" 300 раз.
| Прогноз модели | Count |
|---|---|
| False | 700 |
| Истина | 300 |
Это дает прямую информацию о прогнозах, которые делает наша модель, но она не говорит нам, какие из них правильны. Хотя мы можем использовать функцию затрат, чтобы понять, насколько часто заданы правильные ответы, функция затрат не скажет нам, какие виды ошибок выполняются. Например, модель может правильно угадать все значения true, но и угадать "true", когда она должна угадать "false".
Матрица смешения
Ключом к оценке производительности модели является объединение таблицы для прогнозов модели с таблицей для эталонных меток данных.
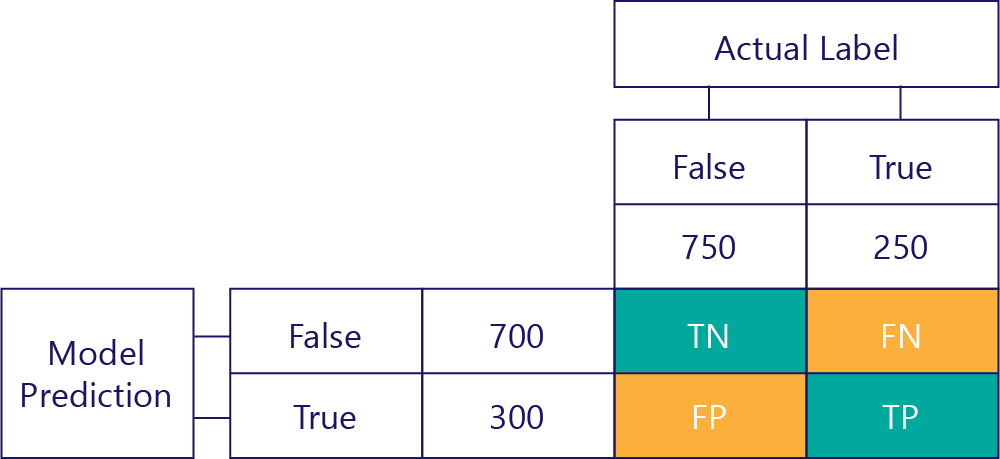
Квадрат, который мы не заполняли, называется матрицей путаницы.
Каждая ячейка в матрице смешения сообщает нам один параметр производительности модели. Эти истинные отрицательные результаты (TN), ложные отрицательные результаты (FN), ложноположительные результаты (FP) и истинные положительные результаты (TP).
Давайте подробно рассмотрим их по очереди, заменив эти акронимы фактическими значениями. Голубые зеленые квадраты означают, что модель сделала правильный прогноз, и оранжевые квадраты означают, что модель сделала неправильный прогноз.
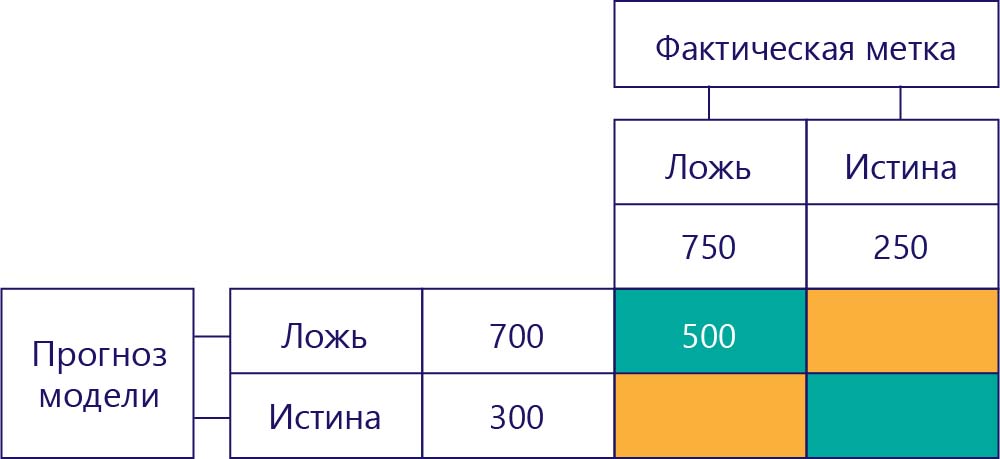
Истинные отрицательные результаты (TN)
В левом верхнем углу будет указано, сколько раз модель cпрогнозировала значение false, и при этом фактическая метка также имела значение false. Иными словами, здесь указывается, сколько раз модель правильно спрогнозировала значение false. Предположим, что в нашем примере это произошло 500 раз.
Ложноотрицательные результаты (FN)
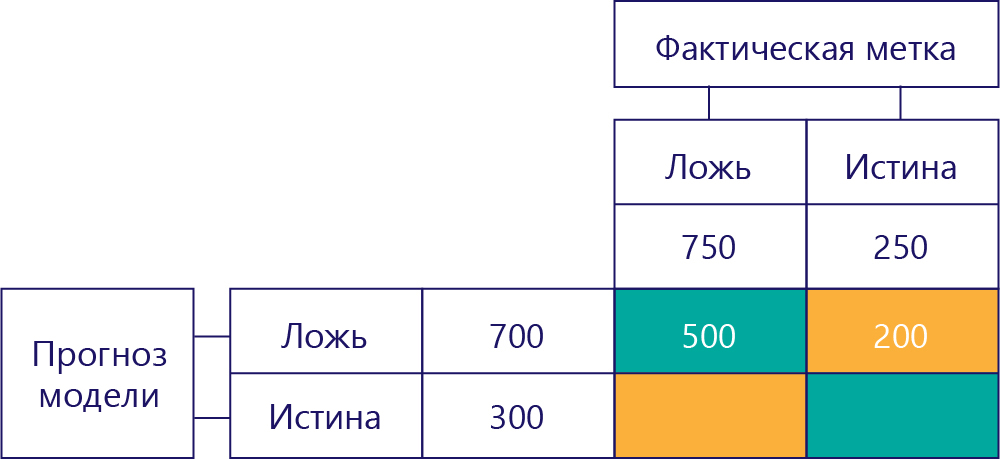
Значение в правом верхнем углу указывает, сколько раз модель дала прогноз false, но при этом фактическая метка была true. Теперь мы знаем, что это значение равно 200. Как это сделать? Учитывая, что модель предсказала на значение false 700 раз, и 500 такой прогноз был верным. Таким образом, 200 раз он должен предсказать false, когда он не должен иметь.
Ложноположительные результаты (FP)
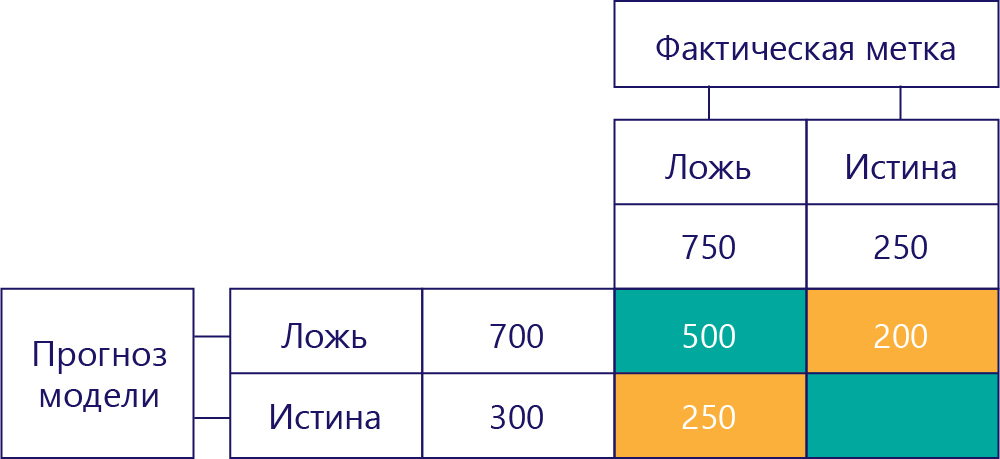
Нижнее левое значение содержит ложные срабатывания. Оно указывает, сколько раз модель спрогнозировала значение true, но фактическая метка при этом была false. Теперь мы знаем, что это 250, потому что было 750 раз, что правильный ответ был ложным. Эти 500 результатов отображаются в верхней левой ячейке (TN).
Истинные положительные результаты (TP)
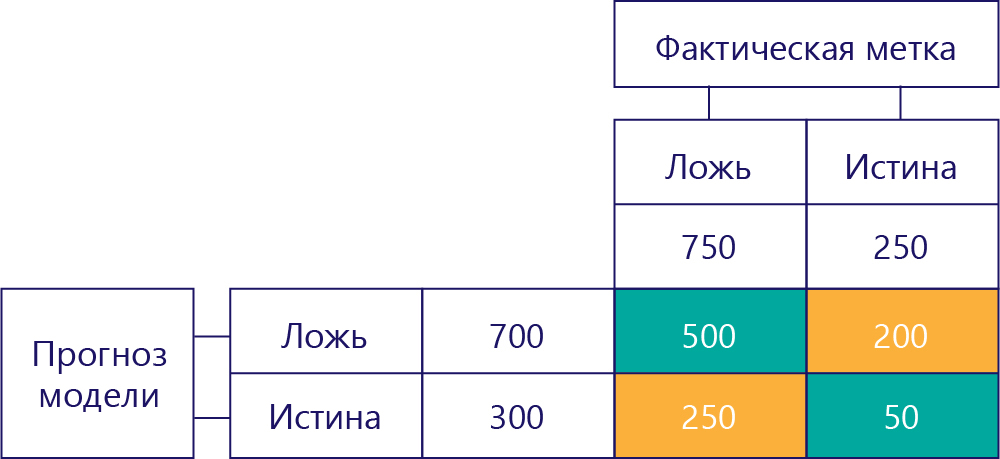
И наконец, у нас есть истинные положительные результаты. Показывает, сколько раз модель правильно спрогнозировала значение true. Мы видим, что это значение равно 50 по двум причинам. Во-первых, модель спрогнозировала значение true 300 раз, но 250 раз этот прогноз был неверным (нижняя левая ячейка). Во вторых, 250 раз значение true было правильным ответом, однако модель 200 раз спрогнозировала значение false.
Окончательный вариант матрицы
Как правило, мы немного упрощаем нашу матрицу смешения:
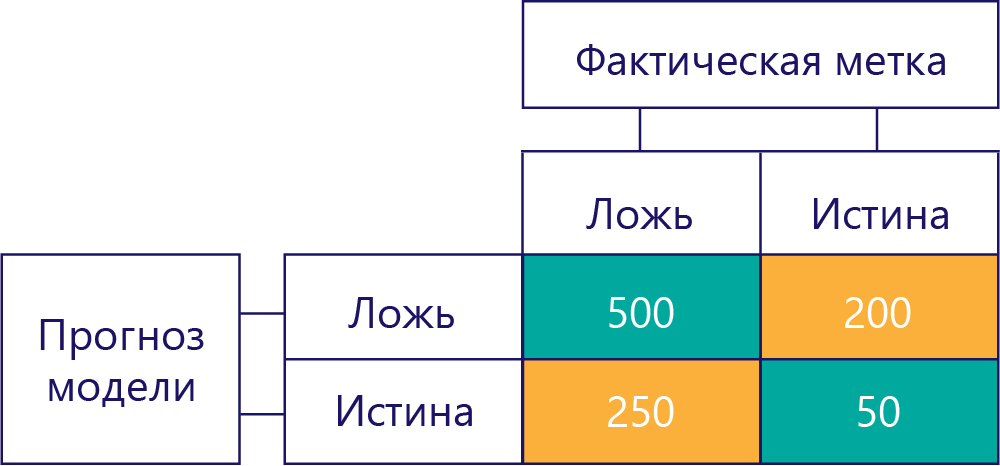
Мы закрасили ячейки, чтобы выделить те случаи, когда модель предоставила правильные прогнозы. Из этого мы знаем не только, как часто модель сделала определенные типы прогнозов, но и насколько часто эти прогнозы были правильными или неправильными.
Матрицы смешения также могут создаваться при наличии дополнительных меток. Например, для нашего примера "человек/животное/дерево" можно получить такую матрицу:
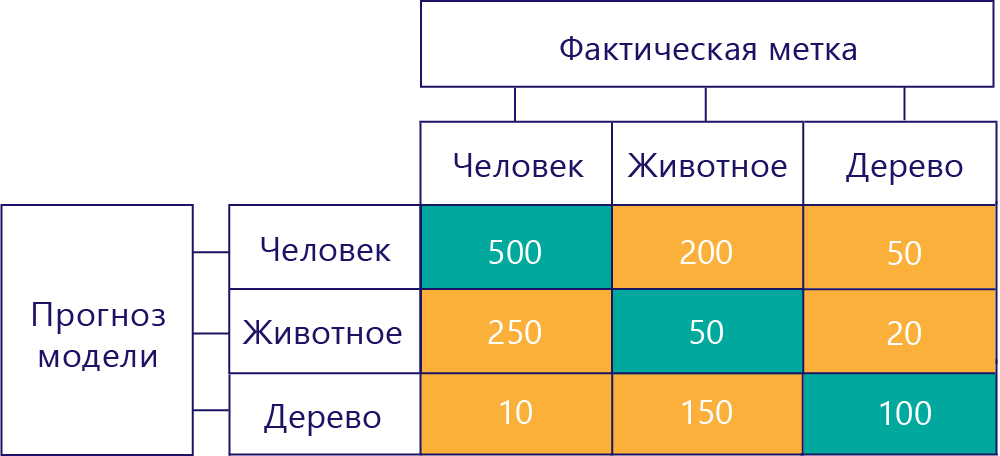
При наличии трех категорий метрики, такие как "истинно положительные результаты", больше не применяются, но мы по-прежнему видим, как часто модель совершала те или иные ошибки. Например, мы видим, что модель предсказала, что "person" 200 раз, когда фактически правильный результат был "животным".