Дисбаланс данных
Когда метки данных имеют несколько категорий, чем другая, мы говорим, что у нас есть дисбаланс данных. Например, вспомним, что в нашем сценарии мы пытаемся определить объекты, найденные датчиками дронов. Наши данные несбалансированы, потому что в наших обучающих данных имеются значительно разные числа туристов, животных, деревьев и пород. Это можно увидеть, организовав такие данные в таблицу.
| Подпись | Пеший турист | Животное | декомпозиции | Камень |
|---|---|---|---|---|
| Count | 400 | 200 | 800 | 800 |
Или нанести их на график:
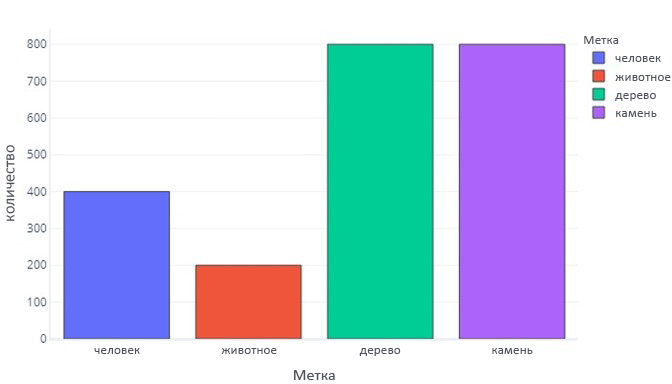
Обратите внимание, что большая часть данных имеет метки "дерево" или "скала". Для сбалансированного набора данных нет этой проблемы.
Например, если мы пытались предсказать, является ли объект туристом, животным, деревом или скалой, мы бы в идеале хотели бы равное число всех категорий, например:
| Подпись | Пеший турист | Животное | декомпозиции | Камень |
|---|---|---|---|---|
| Count | 550 | 550 | 550 | 550 |
Если бы мы просто пытались предсказать, был ли объект туристом, мы бы в идеале хотели бы равное количество туристов и не-туристов объектов:
| Подпись | Пеший турист | Не пеший турист |
|---|---|---|
| Count | 1 100 | 1 100 |
Почему дисбаланс данных имеет значение?
Дисбаланс данных имеет значение, поскольку модели могут научиться имитировать такие дисбалансы, когда это нежелательно. Предположим, например, что мы обучили модель логистической регрессии для распознавания объектов как "пеший турист" и "не пеший турист". Если данные обучения были сильно доминированы метками "турист", то обучение будет предвзят модель, чтобы почти всегда возвращать "походник" метки. Однако в реальной жизни мы можем обнаружить, что большинство объектов, которые обнаруживают дроны, являются деревьями. Модель со смещением, вероятно, будет помечать многие из этих деревьев как "пеший турист".
Это объясняется тем, что функции потерь по умолчанию определяют, был ли дан правильный ответ. То есть при наличии смещенного набора данных, чтобы достичь оптимальной производительности, модели проще всего фактически игнорировать указанные компоненты и всегда (или почти всегда) возвращать один и тот же ответ. Последствия могут быть печальными. Например, представьте, что наша модель туриста/не-туриста обучена по данным, где только один на 1000 примеров содержит туриста. Модель, которая научилась возвращать "не-поход" каждый раз имеет точность 99,9%! Эта статистика, как представляется, выдающаяся, но модель бесполезна, потому что она никогда не скажет нам, если кто-то находится на горе, и мы не будем знать, чтобы спасти их, если лавина хитов.
Смещение в матрице смешения
Матрицы смешения являются ключевым фактором при выявлении дисбалансов данных или смещения модели. В идеале тестовые данные содержат примерно равное количество меток, и прогнозы, сделанные моделью, также приблизительно равномерно распределены между различными метками. При наличии 1000 выборок модель без смещения, которая тем не менее часто дает неверные ответы, может выглядеть примерно так:
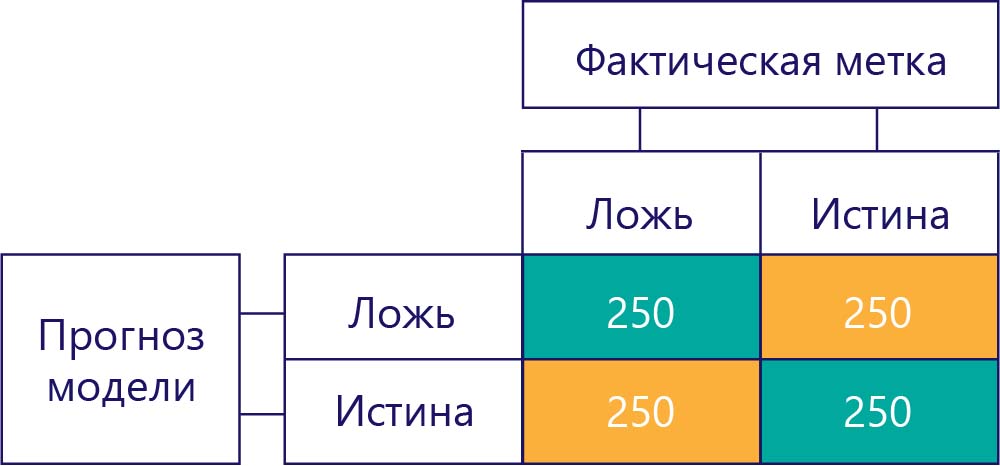
Мы можем сказать, что входные данные необязаны, так как суммы строк одинаковы (500 каждый), указывая, что половина меток имеет значение true, а половина — false. Аналогичным образом, мы видим, что модель предоставляет ответы без смещения, так как в половине случаев она возвращает метки true, а в половине — метки false.
И наоборот, данные со смещением в основном содержат один вид метки, например:
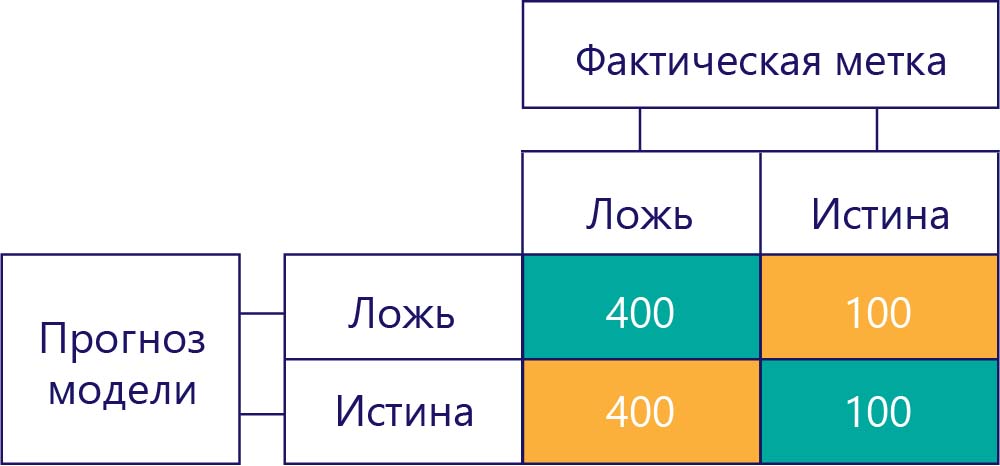
Точно так же, модель со смещением в основном создает один тип метки, например:
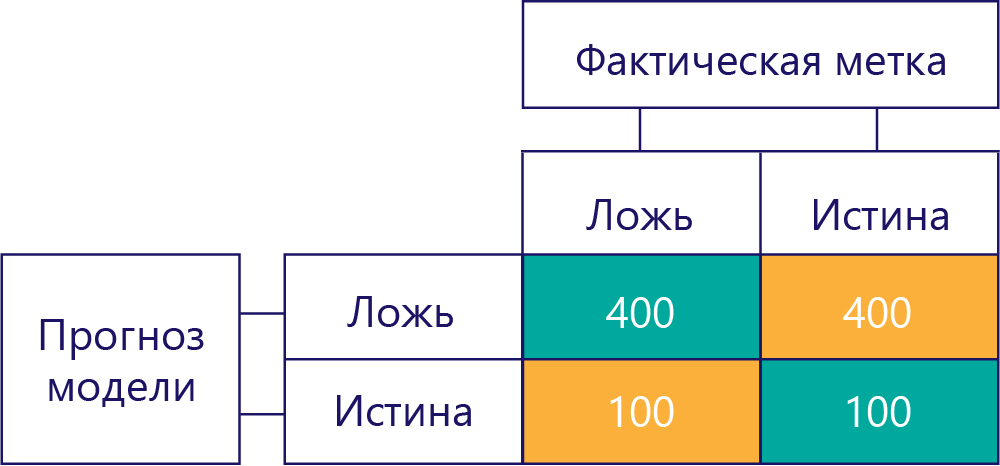
Смещение модели не свидетельствует о ее точности.
Помните, что смещение — это не точность. Например, некоторые из предыдущих примеров предвзяты, и другие не являются, но все они показывают модель, которая получает ответ правильно 50% времени. В качестве еще более показательного примера в приведенной ниже матрице показана неточная модель без смещения:
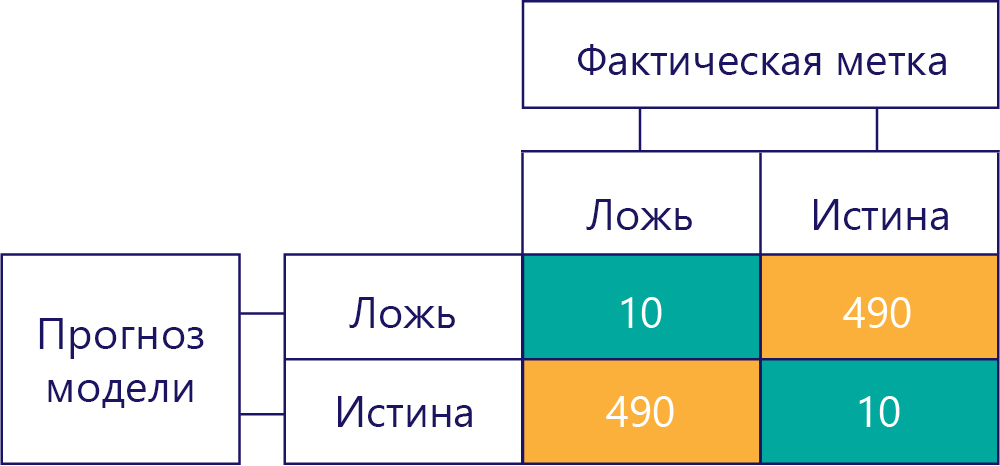
Обратите внимание, что число строк и столбцов входят в эти 500 случаев, указывая на то, что данные сбалансированы, а модель не имеет смещения. Впрочем, такая модель дает практически всегда неправильные ответы!
Конечно, наша цель состоит в том, чтобы модели были точными и не имели смещения, например:
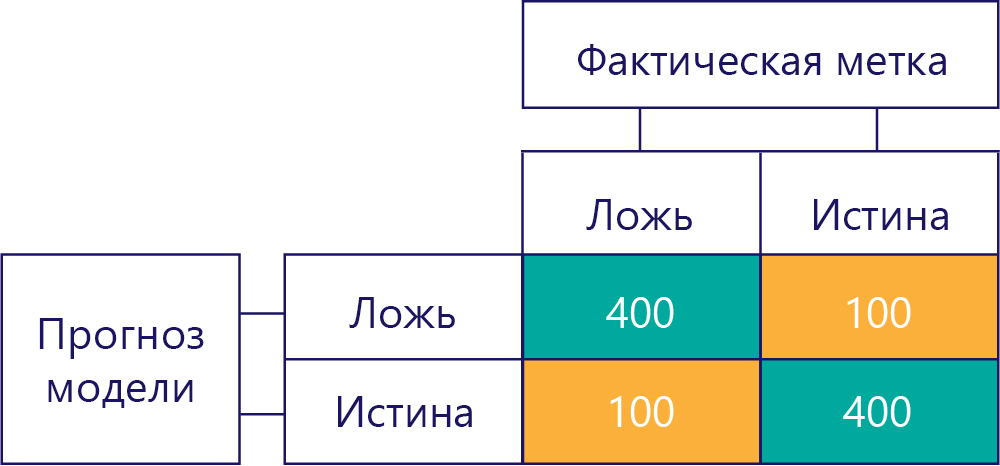
...однако нам нужно убедиться, что наши точные модели не имеют смещения, просто потому что данные:
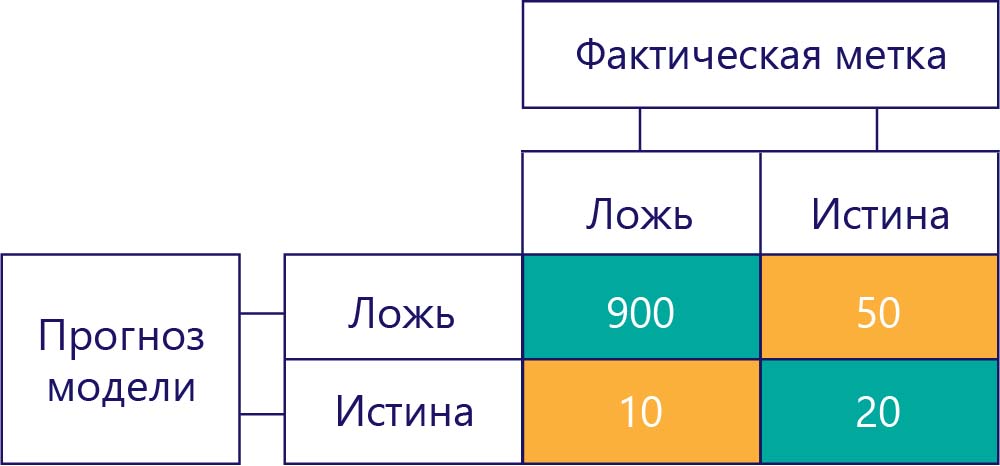
В этом примере обратите внимание, что фактические метки в основном имеют значение false (левый столбец, где показан дисбаланс данных), а модель часто возвращает значение false (верхняя строка, показывающая смещение модели). Эта модель вряд ли годится для того, чтобы давать верные ответы с меткой true.
Предотвращение последствий дисбаланса данных
Далее рассмотрим ряд простейших способов, которые позволяют избежать последствий дисбаланса данных.
- Например, можно более качественно отбирать данные.
- "Resample" ваши данные, чтобы он содержал дубликаты класса меток меньшинства.
- Измените функцию потерь, чтобы она определяла приоритеты менее распространенных меток. Например, если неправильный ответ дан в дерево, функция затрат может вернуть 1; в то время как, если неправильный ответ сделан для туриста, он может вернуть 10.
Мы изучим эти методы в ходе следующих упражнений.