Создание архитектуры Kafka и Spark
Чтобы использовать Kafka и Spark вместе в Azure HDInsight, их необходимо поместить в одну виртуальную сеть или одноранговый узел виртуальных сетей, чтобы кластеры работали с разрешением DNS-имен.
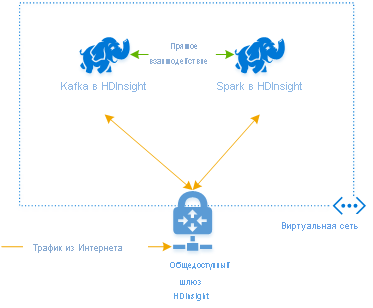
Для создания кластеров в одной виртуальной сети применяется следующая процедура.
- Создание или изменение группы ресурсов
- Добавление виртуальной сети в группу ресурсов
- Добавление кластера Kafka и кластера Spark в ту же виртуальную сеть или в одноранговый узел виртуальных сетей, в которой эти службы работают с разрешением DNS-имен.
Для подключения к кластеру Kafka и Spark в HDInsight рекомендуется использовать собственный соединитель Spark-Kafka, который позволяет кластеру Spark получать доступ к отдельным секциям данных в кластере Kafka, что повышает степень параллелизма в задании обработки в режиме реального времени и обеспечивает очень высокую пропускную способность.
Если оба кластера находятся в одной виртуальной сети, можно также использовать полные доменные имена брокера Kafka в коде потоковой передачи Spark, и вы можете создать правила NSG в виртуальной сети для обеспечения безопасности на уровне предприятия.
Архитектура решения
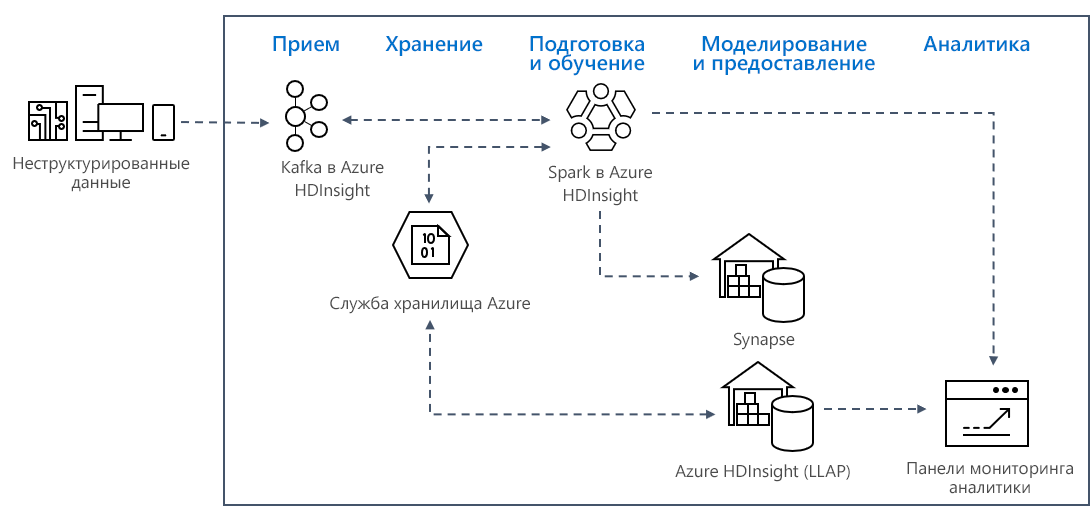
Шаблоны потоковой аналитики в режиме реального времени в Azure обычно используют следующую архитектуру решения.
- Прием: неструктурированные или структурированные данные принимаются в кластер Kafka в Azure HDInsight.
- Подготовка и обучение: данные подготавливаются и обучаются с помощью Spark в HDInsight.
- Моделирование и обслуживание: данные помещаются в хранилище данных, например в Azure Synapse, или в интерактивный запрос HDInsight.
- Аналитика: данные передаются на панель мониторинга аналитики, например Power BI или Tableau.
- Хранение: данные помещаются в решение холодного хранилища, например в хранилище Azure, и обслуживаются позже.
Архитектура для примера сценария
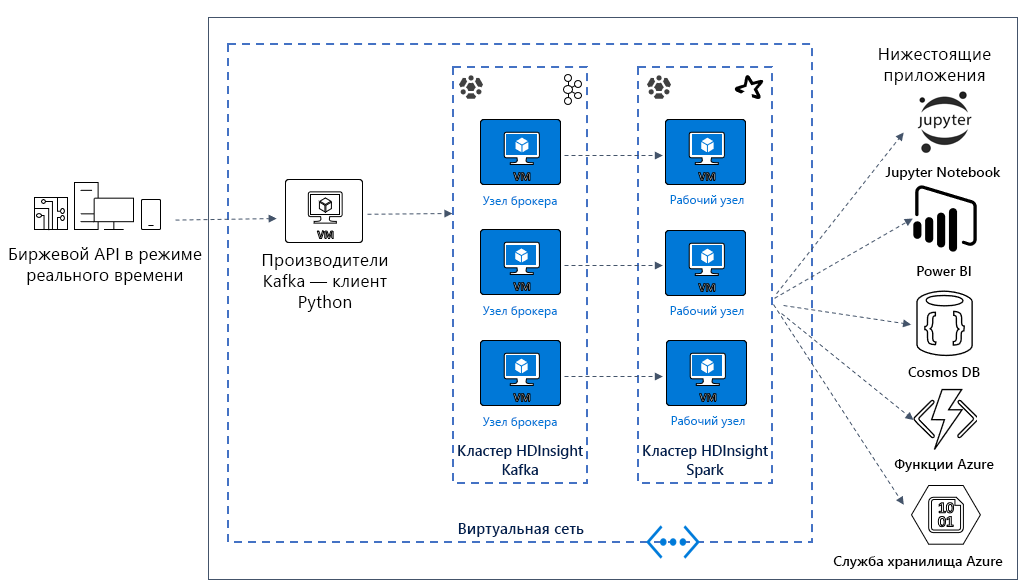
В следующем уроке вы приступите к созданию архитектуры решения для примера приложения. В этом примере используется файл шаблона Azure Resource Manager для создания группы ресурсов, виртуальной сети, кластера Spark и кластера Kafka.
После развертывания кластеров вы подключитесь по протоколу SSH к одному из брокеров Kafka и скопируете файл производителя Python на головной узел. Этот файл производителя предоставляет искусственно создаваемые цены на акции каждые 10 секунд, а также записывает номер секции и смещение сообщения в консоль.
После запуска производителя можно отправить записную книжку Jupyter в кластер Spark. В записной книжке вы подключите кластеры Spark и Kafka и выполните некоторые примеры запросов к данным, включая поиск высоких и низких значений цены акции в окне события.