Упражнение. Прием данных в Azure Data Lake Storage 2-го поколения с помощью Фабрики данных Azure
Открытие пользовательского интерфейса Фабрики данных Azure
Откройте портал Azure в браузере.
Перейдите к группе ресурсов, в которой развернута Фабрика данных Azure. Вы перейдете на следующую страницу.

Выберите "Создание и мониторинг", чтобы перейти на следующую страницу.

Создание связанной службы базы данных SQL Azure
На странице редактирования создаются такие ресурсы фабрики данных, как конвейеры, наборы данных, потоки данных, триггеры и связанные службы. Чтобы создать связанную службу, нажмите кнопку "Управлять".

Щелкните "Создать", чтобы добавить новую связанную службу. Вы перейдете на следующую страницу.

Первой связанной службой, которую вы настроите, будет База данных SQL Azure. С помощью строки поиска можно отфильтровать список хранилищ данных.
Щелкните плитку База данных SQL Azure и нажмите "Продолжить".

Нажав кнопку, вы перейдете на следующую страницу, где необходимо заполнить некоторые параметры Базы данных SQL.

В панели конфигурации базы данных SQL введите "SQLDB" в качестве имени связанной службы. Введите учетные данные, чтобы разрешить Фабрике данных подключаться к базе данных.
Если вы используете проверку подлинности SQL, введите имя сервера, базу данных, имя пользователя и пароль. Правильность сведений о подключении можно проверить, нажав Тестирование подключения. После завершения нажмите Создать.
Создание связанной службы Azure Synapse Analytics
Повторите этот же процесс, чтобы добавить связанную службу Azure Synapse Analytics. Щелкните Новый на вкладке подключений. Выберите плиткуAzure Synapse Analytics (ранее — Хранилище данных SQL) и нажмите "Продолжить".

Нажмите Azure Synapse Analytics, чтобы перейти на следующий экран.

Заполните параметры и нажмите кнопку "Создать". Подключение к связанной службе установлено для ресурса Azure Synapse Analytics.
Создание связанной службы Azure Data Lake Storage 2-го поколения
Последней необходимой связанной службой является Azure Data Lake Storage 2-го поколения. Щелкните Новый на вкладке подключений. Выберите плитку Azure Data Lake Storage 2-го поколения и нажмите "Продолжить".

Откроется следующий экран.

После нажатия кнопки "Создать" откроется следующий экран.

Включите отладку потоков данных.
Включение режима отладки потоков данных
Теперь мы создадим поток данных сопоставления. Перед построением потоков данных сопоставления рекомендуется включить режим отладки, который позволяет в считаные секунды протестировать логику преобразования на активном кластере Spark.
Чтобы включить отладку, щелкните ползунок Data flow debug (Отладка потока данных) в верхней панели фабрики.
Нажмите кнопку "ОК", когда появится всплывающее диалоговое окно подтверждения. Запуск кластера займет 5–7 минут.

Передача данных из базы данных SQL Azure в ADLS 2-го поколения, используя действие копирования
Теперь создадим конвейер с действием копирования, который будет принимать одну таблицу из Базы данных SQL Azure в учетную запись хранения ADLS 2-го поколения. Для этого добавим конвейер, настроим набор данных и выполним отладку конвейера через интерфейс ADF.
Создание конвейера с действием копирования
Щелкните значок "плюс" на панели ресурсов фабрики, чтобы открыть меню нового ресурса. Выберите Конвейер.

Откроется следующий экран.

Присвойте конвейеру имя и сохраните.
В панели действий холста конвейера откройте меню-гармошку Move and Transform (Перемещение и преобразование) и перетащите действие Копирование данных на холст.
Назовите действие копирования описательным именем, например "IngestIntoADLS".

Настройка исходного набора данных базы данных SQL Azure
Выберите вкладку Источник действия копирования. Щелкните Создать, чтобы создать набор данных.
Вашим источником будет таблица dbo.TripData, расположенная в связанной службе SQLDB, настроенной в предыдущем упражнении.

Выполните поиск по База данных SQL Azure и щелкните "Продолжить".

Вызовите набор данных "TripData".
Выберите "SQLDB" в качестве связанной службы.
Выберите "dbo.TripData" из раскрывающегося списка имени таблицы.
Импортируйте схему From connection/store (из подключения/хранилища).
Щелкните "OK", когда все будет готово.
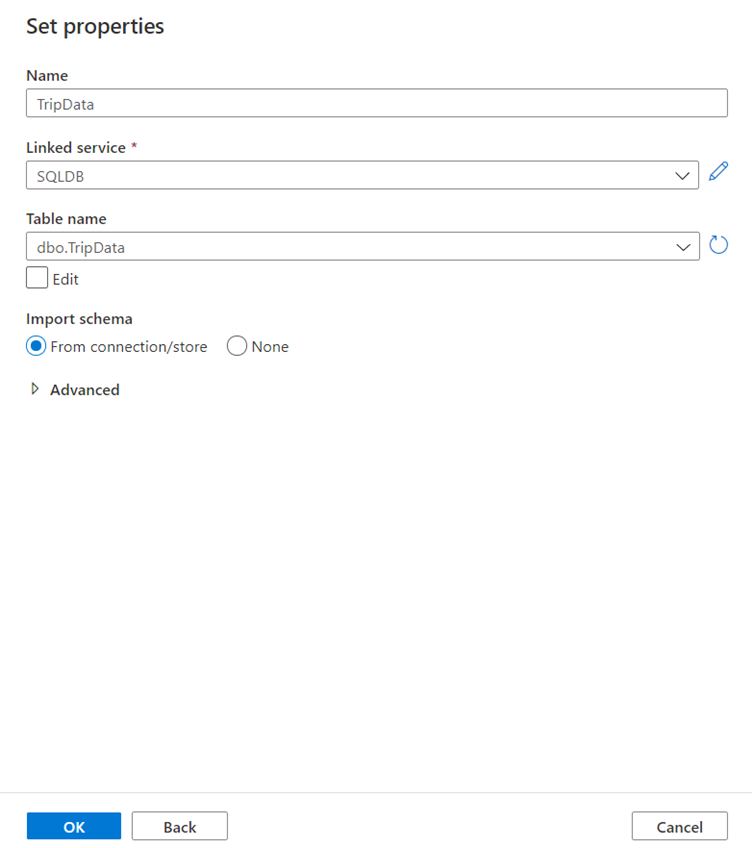
Вы успешно создали свой первый исходный набор данных!
Убедитесь, что в настройках источника в поле запроса на использование выбрано значение по умолчанию Таблица.
Настройка приемного набора данных ADLS 2-го поколения
Выберите вкладку Приемник действия копирования.
Щелкните Создать, чтобы создать набор данных.

Выберите ADLS 2-го поколения и нажмите кнопку "Продолжить".

Во время записи в CSV-файл выберите DelimitedText на панели выбора формата.
Нажмите кнопку Продолжить.

Назовите приемный набор данных "TripDataCSV".
Выберите "ADLSGen2" в качестве связанной службы.
Введите расположение для записи CSV-файла. Например, вы можете записать данные в файл trip-data.csv в контейнере промежуточного хранения.
Установите Использовать первую строку в качестве заголовка на true, если хотите, чтобы выходные данные имели заголовки.
Поскольку в месте назначения еще нет файла, установите для пункта Импорт схемы значение Нет.
Щелкните "OK", когда все будет готово.

Тестирование действия копирования с помощью запуска отладки конвейера
Выполните отладку, чтобы проверить корректность работы действия копирования, нажав Отладка в верхней части холста конвейера. Выполнение отладки позволяет выполнить сквозную проверку конвейера, либо проверку до точки останова, прежде чем опубликовать его в службе фабрики данных.

Чтобы следить за выполнением отладки, перейдите на вкладку Выходные данные холста конвейера.
Экран мониторинга будет обновляться автоматически каждые 20 секунд или после ручного нажатия кнопки обновления.
У действия копирования есть специальное представление мониторинга. Чтобы получить к нему доступ, щелкните значок очков в колонке "Действия".

Нажмите значок очков, чтобы перейти на следующий экран.
Представление мониторинга копирования предоставляет сведения о процессе выполнения и характеристиках производительности. Вы можете просматривать такие сведения, как прочитанные/записанные данные, прочитанные/записанные строки, прочитанные/записанные файлы и пропускная способность.

Здесь вы можете опубликовать изменения в службе фабрики данных, нажав "Опубликовать все" в верхней панели фабрики. Фабрика данных Azure поддерживает полную git-интеграцию. Интеграция Git позволяет выполнять управление версиями, итеративное сохранение в репозитории, а также совместную работу в фабрике данных. Дополнительные сведения см. Source Control in Azure Data Factory (Система управления версиями в фабрике данных Azure).

Если нажать кнопку "Опубликовать все", вы перейдете на следующий экран для подтверждения.

Нажмите "Опубликовать", и конвейер будет опубликован.