Использование Apache Phoenix в HDInsight HBase
Кластеры HBase в HDInsight поставляются с Apache Phoenix. Apache Phoenix — это уровень реляционной базы данных на основе Apache HBase с открытым кодом и высоким уровнем параллелизма. Apache Phoenix позволяет использовать запросы, подобные SQL, через HBase. Его основу составляют драйверы JDBC, что позволяет пользователям создавать, удалять и изменять таблицы SQL. Кроме того, можно индексировать, создавать представления и последовательности, а также обновлять и вставлять строки по отдельности и в пакетном режиме. Phoenix использует для сборки запросов компиляцию в машинный код noSQL, а не MapReduce, что позволяет создавать на основе HBase приложения с низким уровнем задержки. Кроме того, Phoenix поддерживает сопроцессоры для выполнения пользовательского кода в адресном пространстве сервера, то есть прямо в месте размещения данных. Такой подход сводит к минимуму трафик между клиентом и сервером. Дополнительные сведения см. в документации по Apache Phoenix.
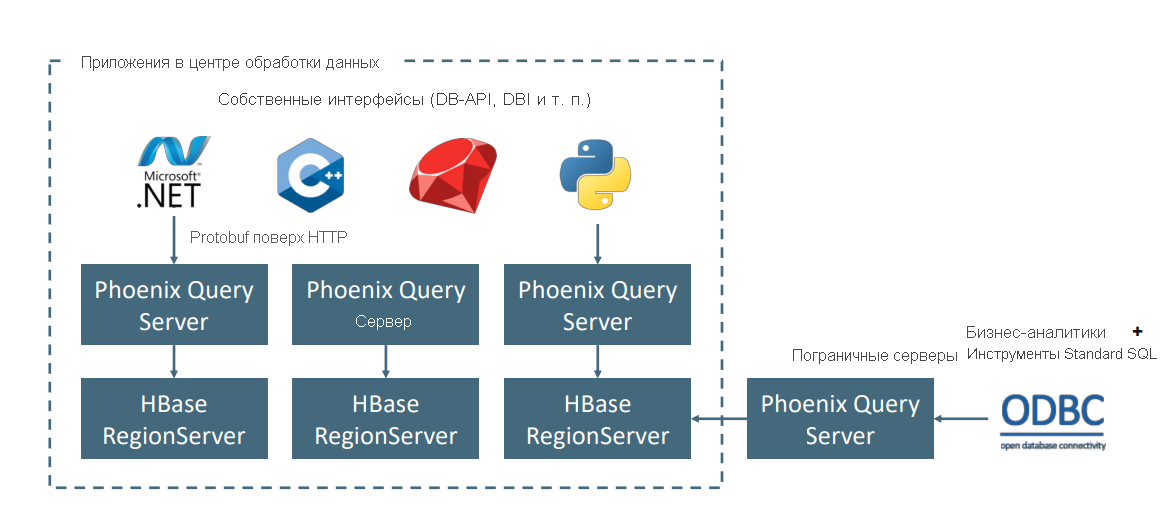
Apache Phoenix в HDInsight HBase обычно используется для обеспечения самостоятельной аналитики и извлечения аналитических сведений, как показано ниже. Phoenix может подключаться к любому средству бизнес-аналитики, совместимому с ODBC, и обеспечивает нерегламентированную аналитику SQL в HBase.

Apache HBase в сочетании с Phoenix можно использовать в качестве хранилища изменяемых данных. Обработчик запросов Apache Phoenix в HBase поставляется с некоторыми важными функциями.
Вторичные индексы
Доступ к записям в HBase осуществляется с помощью ключа первичной строки с помощью одного индекса, лексикографически отсортированного по ключу первичной строки. Если вы попытаетесь получить доступ к записям любым другим способом, отличным от первичной строки, это приведет к неэффективному сканированию всех данных в таблице HBase. Apache Phoenix позволяет создавать вторичные индексы в столбцах и выражениях для создания ключей альтернативных строк, чтобы разрешить уточняющие запросы точек или сканирование диапазонов по этому новому индексу. Дополнительные сведения см. в документации по вторичным индексам Apache Phoenix.
Для создания вторичных индексов в HBase используется команда CREATE INDEX, как показано ниже.
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
Представления
Ограничение количества физических таблиц в HBase и, в свою очередь, ограничение количества регионов, является рекомендуемой стратегией. Представления в Phoenix помогают реализовать эту рекомендуемую стратегию, позволяя создавать несколько виртуальных таблиц, совместно использующих одну и ту же физическую таблицу в HBase. Дополнительные сведения см. в документации по представлениям Apache Phoenix.
Ниже приведено определение таблицы в HBase.
CREATE TABLE product_metrics (
metric_type CHAR(1),
created_by VARCHAR,
created_date DATE,
metric_id INTEGER
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
Можно определить следующее представление.
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS SELECT * FROM product_metric WHERE metric_type = 'm';
Транзакции
Несмотря на то что HBase работает только с транзакциями на уровне строк, Apache Phoenix позволяет выполнять межтабличные и межстрочные транзакции с полной поддержкой ACID за счет интеграции с Apache Tephra.
Дополнительные сведения см. в документации по транзакциям Apache Phoenix.
В следующем примере создается таблица с именем my_table, после чего она изменяется для включения транзакций.
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
Таблицы случайных данных
Если ключи строк увеличиваются однообразно, то при последовательных операциях записи может произойти перегрузка регионального сервера в HBase. Apache Phoenix может снизить перегрузку, предоставляя способ добавления случайных данных в ключ строки с помощью байта случайных данных для определенной таблицы. Дополнительные сведения см. в документации по таблицам случайных данных Apache Phoenix.
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
Просмотр с пропуском
Для указанного набора строк Apache Phoenix использует просмотр с пропуском для сканирования внутри строки вместо сканирования диапазона, чтобы повысить производительность. При просмотре с пропуском используется фильтр HBase SEEK_NEXT_USING_HINT. Он хранит сведения о том, поиск какого набора ключей или диапазонов ключей выполняется в каждом столбце. Затем он принимает ключ (переданный в него во время оценки фильтра) и определяет, находится ли он в одной из комбинаций или диапазонов. Если нет, то он определяет, к какому следующему самому большому ключу следует перейти. Дополнительные сведения см. в документации по проверке с пропуском в Apache Phoenix.
Оптимизация производительности в Apache Phoenix — это дополнительная функция, предоставляемая по запросу, которая в основном используется для оптимизации производительности компонентов, составляющих основу HBase. Оптимизация производительности — это сложная тема, которая выходит за рамки данного курса. Тем не менее, если вам интересно, обратитесь к документации с рекомендациями по повышению производительности Apache Phoenix.