Что такое регрессия?
Регрессия работает путем установления связи между переменными в данных, которые представляют характеристики (называемые признаками) наблюдаемого объекта, и переменной, которую мы пытаемся предсказать (называемой меткой).
Вспомните, что наша компания арендует велосипеды и хочет предсказать ожидаемое количество аренды в данный день. В этом случае нужно учитывать такие признаки, как день недели, месяц и т. д., а меткой будет количество взятых напрокат велосипедов.
Чтобы обучить модель, мы начнем с примера данных, содержащего функции, а также известные значения метки; поэтому в этом случае нам нужны исторические данные, которые включают даты, погодные условия и количество прокатов велосипедов.
Затем этот образец данных будет разбит на два подмножества.
- Набор данных для обучения, к которому мы будем применять алгоритм, определяет функцию, которая инкапсулирует связь между значениями признаков и известными значениями меток.
- Набор данных для проверки или тестирования, который можно использовать для оценки модели с помощью создания прогнозов для метки и их сравнения с фактическими значениями известных меток.
Благодаря использованию данных за прошлые периоды с известными значениями меток для обучения модели регрессия является примером контролируемого машинного обучения.
Простой пример
Давайте рассмотрим простой пример, чтобы понять принцип работы процесса обучения и оценки. Давайте упростим сценарий, чтобы прогнозировать метку количества взятых напрокат велосипедов только по одному признаку — средней дневной температуре.
Начнем с данных, которые включают известные значения для признака средней дневной температуры и метки количества велосипедов, взятых напрокат.
| Температура | Арендная плата |
|---|---|
| 56 | 115 |
| 61 | 126 |
| 67 | 137 |
| 72 | 140 |
| 76 | 152 |
| 82 | 156 |
| 54 | 114 |
| 62 | 129 |
Теперь мы случайным образом выбираем пять из этих наблюдений и используем их для обучения модели регрессии. Говоря об "обучении модели", мы имеем в виду, что нужно найти функцию (математическое уравнение, назовем его f), которая может использовать признак температуры (который мы назовем x) для расчета количества клиентов (которое мы обозначим как y). Иными словами, необходимо определить следующую функцию: f(x) = y.
Наш обучающий набор данных выглядит следующим образом.
| x | y |
|---|---|
| 56 | 115 |
| 61 | 126 |
| 67 | 137 |
| 72 | 140 |
| 76 | 152 |
Начнем с графика обучающих значений для x и y на диаграмме:
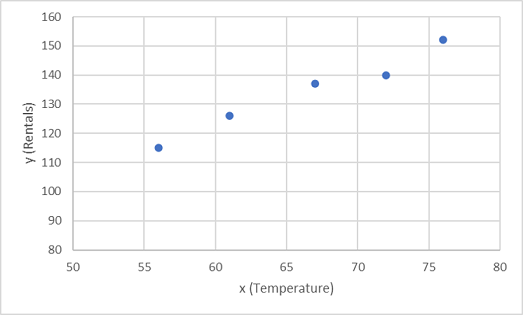
Теперь необходимо разместить эти значения в функции, допуская случайную вариацию. Вероятно, видно, что выложенные точки образуют почти прямую диагональную линию; Другими словами, между x и y есть видимая линейная связь, поэтому нам нужно найти линейную функцию, которая лучше всего подходит для образца данных. Существует несколько алгоритмов, которые мы можем использовать для определения этой функции, которая в конечном итоге найдет прямую линию с минимальным отклонением от точек на графике.
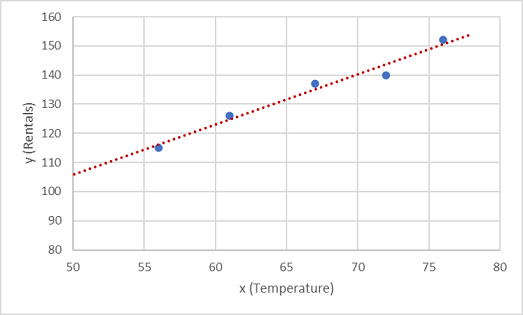
Линия представляет линейную функцию, которую можно использовать с любым значением x для применения наклона линии и отсекаемого отрезка (где линия пересекает ось y, если x равен 0) для вычисления y. В этом случае, если мы расширили линию слева, мы обнаружили, что если x равно 0, y составляет около 20, а наклон линии такой, что для каждой единицы x, перемещаемой вдоль справа, y увеличивается примерно на 1,7. Поэтому мы можем вычислить нашу функцию как 20 + 1,7x.
Теперь, когда мы определили нашу прогнозную функцию, мы можем использовать ее для прогнозирования меток для проверочных данных и сравнения прогнозируемых значений (которые обычно обозначаются символом ŷ) с фактическими известными значениями y.
| x | y | ŷ |
|---|---|---|
| 82 | 156 | 159,4 |
| 54 | 114 | 111,8 |
| 62 | 129 | 125,4 |
Давайте посмотрим, как значения y и ŷ сопоставляются на графике.
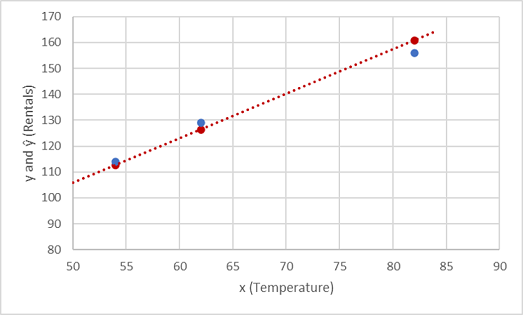
Точки графика на линии функции представляют собой прогнозируемые значения ŷ, вычисленные функцией, а остальные точки — фактические значения y.
Существует множество способов измерения расхождений между прогнозируемыми и фактическими значениями, и мы можем использовать эти метрики для оценки точности прогноза модели.
Примечание.
Машинное обучение основано на статистике и математике, поэтому важно помнить о конкретных терминах, которые используют статистики и математики (и, следовательно, специалисты по обработке и анализу данных). Можно представить разницу между прогнозируемым и фактическим значением метки как меру погрешности. Однако на практике "фактические" значения основаны на примерах наблюдений (которые сами по себе могут быть подвержены некоторым случайным дисперсиям). Чтобы обозначить, что мы сравниваем прогнозируемое значение (ŷ) с наблюдаемым (y), разницу между ними мы называем остатками. Мы можем суммировать остатки для всех прогнозов по проверочным данным, чтобы вычислить общие потери в модели для измерения прогнозной производительности.
Один из наиболее распространенных способов измерения потерь — возвести в квадрат отдельные остатки, суммировать квадраты и рассчитать среднее. Возведение в квадрат позволяет использовать абсолютные значения (без учета положительных и отрицательных чисел) и увеличить вес серьезных различий. Эта метрика называется среднеквадратической погрешностью.
Для наших проверочных данных вычисление выглядит следующим образом.
| y | ŷ | y – ŷ | (y – ŷ)2 |
|---|---|---|---|
| 156 | 159,4 | –3,4 | 11,56 |
| 114 | 111,8 | 2,2 | 4,84 |
| 129 | 125,4 | 3,6 | 12,96 |
| Sum | ∑ | 29,36 | |
| Среднее | x̄ | 9,79 |
Таким образом, потеря модели на основе метрики MSE составляет 9,79.
Итак, это хорошо? Трудно сказать, так как значение MSE не выражается в понятной единице измерения. Мы знаем, что чем ниже значение, тем меньше потери в модели, и, следовательно, лучше это прогнозировать. Полезно сравнить эту метрику у двух моделей и выбрать наиболее подходящую.
Иногда более полезно выразить потерю в той же единице измерения, что и прогнозируемое значение метки; в этом случае количество аренды. Для этого можно вычислить квадратный корень из СКП, чтобы рассчитать метрику, которая называется корнем среднеквадратической погрешности (КСКП).
√9,79 = 3,13
Таким образом, RMSE нашей модели указывает, что потеря составляет чуть более 3, что можно интерпретировать слабо как значение, что в среднем неверные прогнозы неправильно примерно на три аренды.
Существует множество других метрик, которые можно использовать для измерения потерь при регрессии. Например, R2 (R в квадрате) (иногда это называется коэффициентом определения) показывает корреляцию между x и y в квадрате. В результате получается значение от 0 до 1, измеряющее степень расхождений, которую можно объяснить с помощью модели. Как правило, чем ближе это значение к 1, тем выше точность прогнозов модели.