Создание кластера Spark
С помощью портала Azure Databricks можно создать один или несколько кластеров в рабочей области Azure Databricks.
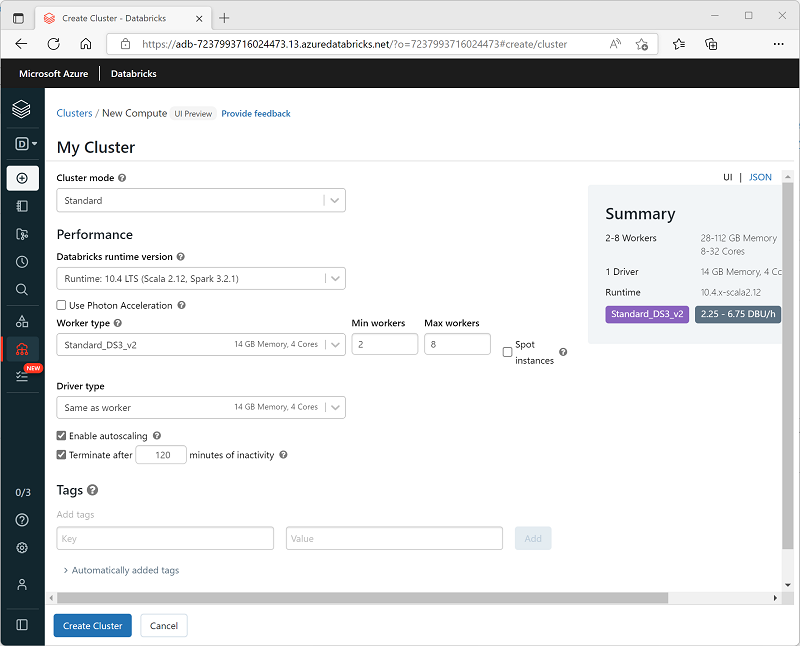
Во время создания кластера можно задать параметры конфигурации, включая следующие:
- Имя кластера.
- Режим кластера, который может быть следующим:
- Стандартный: подходит для рабочих нагрузок с одним пользователем, которым требуется несколько рабочих узлов.
- Высокая степень параллелизма: подходит для рабочих нагрузок, в которых несколько пользователей используют кластер одновременно.
- С одним узлом: подходит для небольших рабочих нагрузок или тестирования, где требуется лишь один рабочий узел.
- Версия Databricks Runtime, которая будет использоваться в кластере. Она определяет версию Spark и таких отдельных установленных компонентов, как Python, Scala и др.
- Тип виртуальной машины, используемой для рабочих узлов в кластере.
- Наименьшее и наибольшее количество рабочих узлов в кластере.
- Тип виртуальной машины, используемой для узла драйвера в кластере.
- Поддержка автомасштабирования для динамического изменения размера кластера.
- Длительность периода простоя кластера перед автоматическим завершением работы.
Управление кластерными ресурсами в Azure
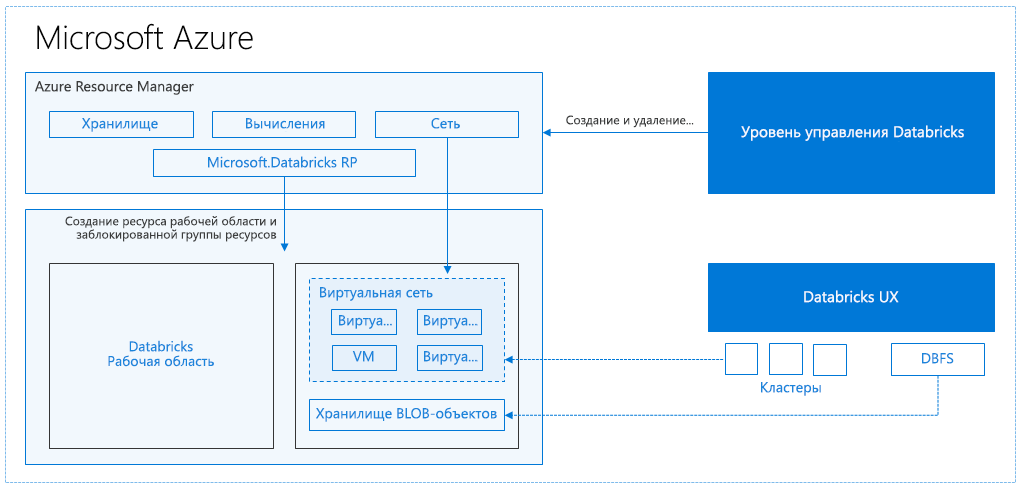
Когда вы создаете рабочую область Azure Databricks, в вашей подписке развертывается устройство Databricks в качестве ресурса Azure. Во время создания кластера в рабочей области вы указываете типы и размеры виртуальных машин, которые будут использоваться для узла драйвера и рабочих узлов, а также некоторые другие параметры конфигурации, но всеми остальными аспектами работы кластера управляет Azure Databricks.
Устройство Databricks развертывается в Azure как группа управляемых ресурсов в вашей подписке. Эта группа ресурсов содержит виртуальные машины для узла драйвера и рабочих узлов ваших кластеров, а также другие необходимые ресурсы, в том числе виртуальную сеть, группу безопасности и учетную запись хранения. Все метаданные для вашего кластера, такие как запланированные задания, хранятся в Базе данных Azure с георепликацией для обеспечения отказоустойчивости.
На внутреннем уровне Служба Azure Kubernetes (AKS) используется для запуска уровня управления и плоскостей данных Azure Databricks с помощью контейнеров, работающих на оборудовании Azure последнего поколения (виртуальных машинах Dv3) с твердотельными накопителями NvMe, способными поддерживать невероятно низкую задержку (100 мс) на высокопроизводительных виртуальных машинах Azure с ускорением сети. Azure Databricks использует эти функции Azure для дальнейшего повышения производительности Spark. Когда службы в группе управляемых ресурсов будут готовы, вы сможете управлять кластером Databricks с помощью пользовательского интерфейса Azure Databricks и таких функций, как автоматическое масштабирование и автоматическое завершение работы.
Примечание.
Также можно подключить кластер к пулу неактивных узлов, чтобы сократить время его запуска. Дополнительные сведения см. в разделе Пулы в документации по Azure Databricks.