Визуализация данных
Одним из самых интуитивно понятных способов анализа результатов запросов к данным является их визуализация в виде диаграмм. Возможности для создания диаграмм доступны в пользовательском интерфейсе записных книжек Azure Databricks, а когда этих функций недостаточно, вы можете воспользоваться любой из множества графических библиотек Python для создания и отображения визуализаций данных в записной книжке.
Использование встроенных диаграмм записных книжек
При отображении кадра данных или выполнении SQL-запроса в записной книжке Spark в Azure Databricks результаты отображаются под ячейкой кода. По умолчанию они представлены в виде таблицы, но можно также просмотреть их визуализацию и настроить отображение диаграммы данных, как показано ниже:
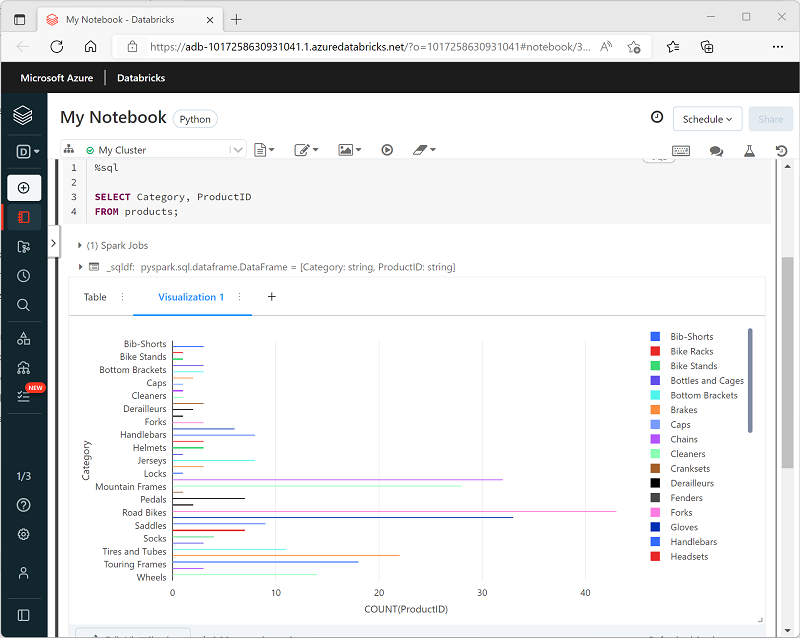
Встроенные функции визуализации в записных книжках удобны для быстрого и наглядного обобщения данных. Если требуется более детальный контроль за форматированием данных или отображение значений, уже агрегированных в запрос, рекомендуется использовать графический пакет для создания собственных визуализаций.
Использование графических пакетов в коде
Для создания визуализаций данных в коде можно использовать множество графических пакетов. В частности, Python поддерживает целый ряд пакетов. В основе большинства из них лежит базовая библиотека Matplotlib. Выходные данные из графической библиотеки можно преобразовать для просмотра в записной книжке. Это упрощает объединение кода для приема и обработки данных с помощью встроенных визуализаций данных и ячеек Markdown для комментариев.
Например, можно использовать следующий код PySpark для агрегирования данных из гипотетических данных продуктов, изученных ранее в этом модуле, и Matplotlib для создания диаграммы на основе агрегированных данных.
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
Библиотека Matplotlib требует, чтобы данные находились в кадре данных Pandas, а не в кадре данных Spark, поэтому для их преобразования применяется метод toPandas. Затем код создает фигуру указанного размера и строит линейчатую диаграмму с некоторой настраиваемой конфигурацией свойств, и только после этого отображается итоговая диаграмма.
Диаграмма, созданная кодом, будет выглядеть примерно так:
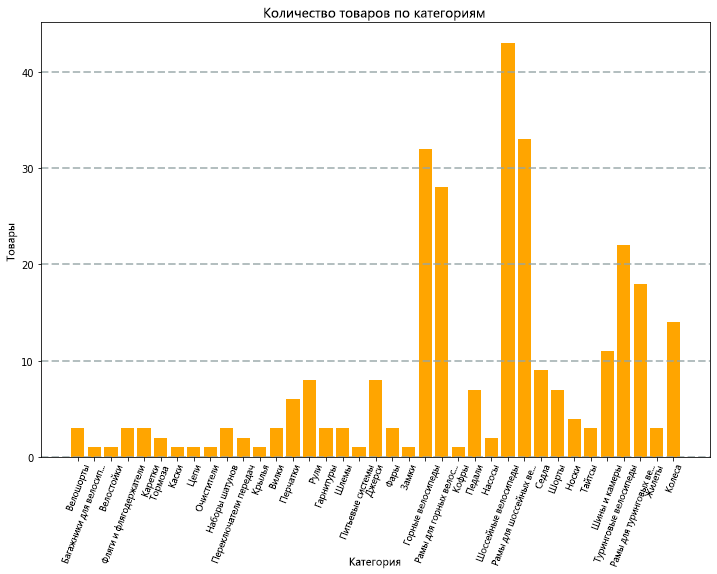
С помощью библиотеки Matplotlib можно создавать самые разные диаграммы; однако для создания диаграмм с высоким уровнем настройки можно использовать и другие библиотеки, такие как Seaborn.
Примечание.
Библиотеки Matplotlib и Seaborn могут быть уже установлены в кластерах Databricks в зависимости от среды Databricks Runtime для кластера. Если они отсутствуют или вы хотите использовать другую библиотеку, которая еще не установлена, добавьте их в кластер. Дополнительные сведения см. в документации Azure Databricks по Библиотекам уровня кластера.