Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
Дополнительные сведения о поддержке операционной системы, поддержке моделей и т. д. см. в обзоре WebNN.
В этом руководстве показано, как использовать WebNN с ONNX Runtime Web для создания системы классификации изображений в Интернете с аппаратным ускорением, с использованием GPU на устройстве. Мы будем использовать модель MobileNetV2 , которая является моделью с открытым исходным кодом в Hugging Face , используемой для классификации изображений.
Если вы хотите просмотреть и запустить окончательный код этого руководства, его можно найти на сайте WebNN Developer Preview GitHub.
Замечание
API WebNN — это рекомендация кандидата W3C и находится на ранних этапах предварительной версии разработчика. Некоторые функции ограничены. У нас есть список текущих состояний поддержки и реализации.
Требования и настройка:
Настройка Windows
Убедитесь, что у вас есть правильные версии драйверов edge, Windows и оборудования, как описано в разделе "Требования к WebNN".
Настройка Edge
Скачайте и установите Microsoft Edge Dev.
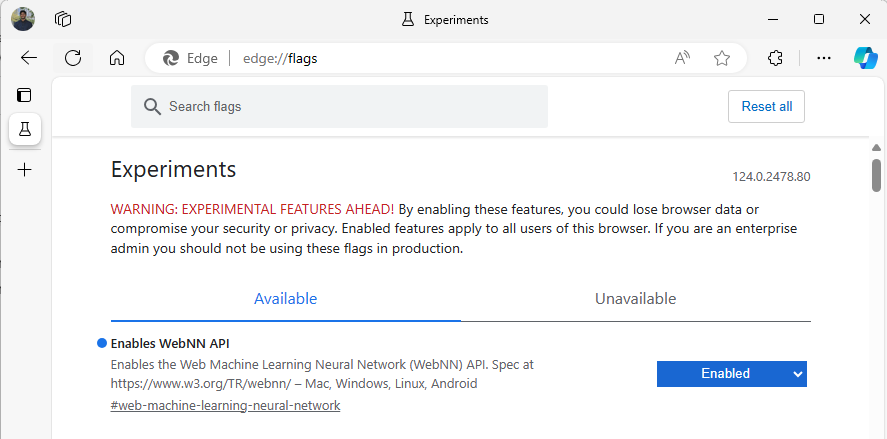
Откройте бета-версию Edge, затем введите
about:flagsв адресной строке.Найдите "API WebNN", щелкните раскрывающийся список и установите значение "Включено".
Перезапустите Edge, как предложено.
Настройка среды разработчика
Скачайте и установите Visual Studio Code (VSCode).
Запустите VSCode.
Скачайте и установите расширение Live Server для VSCode в VSCode .
Выберите
File --> Open Folder, и создайте пустую папку в нужном расположении.
Шаг 1. Инициализация веб-приложения
- Чтобы начать, создайте новую
index.htmlстраницу. Добавьте следующий стандартный код на новую страницу:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>My Website</title>
</head>
<body>
<main>
<h1>Welcome to My Website</h1>
</main>
</body>
</html>
- Проверьте стандартный код и настройку разработчика, нажав кнопку Go Live в нижней правой части VSCode. Это должно запустить локальный сервер в Edge Beta с выполнением шаблонного кода.
- Теперь создайте новый файл с именем
main.js. Это будет содержать код javascript для приложения. - Затем создайте вложенную папку в корневом каталоге с именем
images. Скачайте и сохраните любое изображение в папке. Для этой демонстрации мы будем использовать имяimage.jpgпо умолчанию. - Скачайте модель MobileNet из каталога моделей ONNX. В этом руководстве вы будете использовать файл mobilenet2-10.onnx . Сохраните эту модель в корневой папке веб-приложения.
- Наконец, скачайте и сохраните файл классов изображений.
imagenetClasses.jsЭто предоставляет 1000 распространенных классификаций изображений для использования вашей моделью.
Шаг 2. Добавление элементов пользовательского интерфейса и родительской функции
- В тексте
<main>html-тегов, добавленных на предыдущем шаге, замените существующий код следующими элементами. Они будут создавать кнопку и отображать изображение по умолчанию.
<h1>Image Classification Demo!</h1>
<div><img src="./images/image.jpg"></div>
<button onclick="classifyImage('./images/image.jpg')" type="button">Click Me to Classify Image!</button>
<h1 id="outputText"> This image displayed is ... </h1>
- Теперь вы добавите ONNX Runtime Web на свою страницу. Это библиотека JavaScript, которую вы будете использовать для доступа к API WebNN. В тексте
<head>html-тегов добавьте следующие исходные ссылки javascript.
<script src="./main.js"></script>
<script src="imagenetClasses.js"></script>
<script src="https://cdn.jsdelivr.net/npm/onnxruntime-web@1.18.0-dev.20240311-5479124834/dist/ort.webgpu.min.js"></script>
-
main.jsОткройте файл и добавьте следующий фрагмент кода.
async function classifyImage(pathToImage){
var imageTensor = await getImageTensorFromPath(pathToImage); // Convert image to a tensor
var predictions = await runModel(imageTensor); // Run inference on the tensor
console.log(predictions); // Print predictions to console
document.getElementById("outputText").innerHTML += predictions[0].name; // Display prediction in HTML
}
Шаг 3. Предварительная обработка данных
- Добавленная вами функция вызывает
getImageTensorFromPath, другую функцию, которую необходимо реализовать. Вы добавите его ниже, а также другую асинхронную функцию, которая вызывается для получения самого изображения.
async function getImageTensorFromPath(path, width = 224, height = 224) {
var image = await loadImagefromPath(path, width, height); // 1. load the image
var imageTensor = imageDataToTensor(image); // 2. convert to tensor
return imageTensor; // 3. return the tensor
}
async function loadImagefromPath(path, resizedWidth, resizedHeight) {
var imageData = await Jimp.read(path).then(imageBuffer => { // Use Jimp to load the image and resize it.
return imageBuffer.resize(resizedWidth, resizedHeight);
});
return imageData.bitmap;
}
- Кроме того, необходимо добавить
imageDataToTensorфункцию, на которую ссылается выше, которая будет отображать загруженный образ в тензорном формате, который будет работать с нашей моделью ONNX. Это более связанная функция, хотя это может показаться знакомым, если вы работали с аналогичными приложениями классификации изображений раньше. Дополнительные сведения см. в этом руководстве ONNX.
function imageDataToTensor(image) {
var imageBufferData = image.data;
let pixelCount = image.width * image.height;
const float32Data = new Float32Array(3 * pixelCount); // Allocate enough space for red/green/blue channels.
// Loop through the image buffer, extracting the (R, G, B) channels, rearranging from
// packed channels to planar channels, and converting to floating point.
for (let i = 0; i < pixelCount; i++) {
float32Data[pixelCount * 0 + i] = imageBufferData[i * 4 + 0] / 255.0; // Red
float32Data[pixelCount * 1 + i] = imageBufferData[i * 4 + 1] / 255.0; // Green
float32Data[pixelCount * 2 + i] = imageBufferData[i * 4 + 2] / 255.0; // Blue
// Skip the unused alpha channel: imageBufferData[i * 4 + 3].
}
let dimensions = [1, 3, image.height, image.width];
const inputTensor = new ort.Tensor("float32", float32Data, dimensions);
return inputTensor;
}
Шаг 4. Вызов ONNX Runtime Web
- Теперь вы добавили все функции, необходимые для получения изображения и отрисовки его в виде тензора. Теперь, используя веб-библиотеку среды выполнения ONNX, загруженную выше, вы запустите модель. Обратите внимание, что для использования WebNN здесь вам нужно просто указать
executionProvider = "webnn"— поддержка ONNX Runtime делает процесс подключения WebNN очень простым и понятным.
async function runModel(preprocessedData) {
// Set up environment.
ort.env.wasm.numThreads = 1;
ort.env.wasm.simd = true;
// Uncomment for additional information in debug builds:
// ort.env.wasm.proxy = true;
// ort.env.logLevel = "verbose";
// ort.env.debug = true;
// Configure WebNN.
const modelPath = "./mobilenetv2-10.onnx";
const devicePreference = "gpu"; // Other options include "npu" and "cpu".
const options = {
executionProviders: [{ name: "webnn", deviceType: devicePreference, powerPreference: "default" }],
freeDimensionOverrides: {"batch": 1, "channels": 3, "height": 224, "width": 224}
// The key names in freeDimensionOverrides should map to the real input dim names in the model.
// For example, if a model's only key is batch_size, you only need to set
// freeDimensionOverrides: {"batch_size": 1}
};
modelSession = await ort.InferenceSession.create(modelPath, options);
// Create feeds with the input name from model export and the preprocessed data.
const feeds = {};
feeds[modelSession.inputNames[0]] = preprocessedData;
// Run the session inference.
const outputData = await modelSession.run(feeds);
// Get output results with the output name from the model export.
const output = outputData[modelSession.outputNames[0]];
// Get the softmax of the output data. The softmax transforms values to be between 0 and 1.
var outputSoftmax = softmax(Array.prototype.slice.call(output.data));
// Get the top 5 results.
var results = imagenetClassesTopK(outputSoftmax, 5);
return results;
}
Шаг 5. Данные после обработки
- Наконец, вы добавите
softmaxфункцию, а затем добавьте окончательную функцию для возврата наиболее вероятной классификации изображений. Элементsoftmaxпреобразует ваши значения в промежуток между 0 и 1, что является вероятностной формой, необходимой для этой окончательной классификации.
Сначала добавьте следующие исходные файлы для вспомогательных библиотек Джимп и Lodash в теге main.jsголовы.
<script src="https://cdnjs.cloudflare.com/ajax/libs/jimp/0.22.12/jimp.min.js" integrity="sha512-8xrUum7qKj8xbiUrOzDEJL5uLjpSIMxVevAM5pvBroaxJnxJGFsKaohQPmlzQP8rEoAxrAujWttTnx3AMgGIww==" crossorigin="anonymous" referrerpolicy="no-referrer"></script>
<script src="https://cdn.jsdelivr.net/npm/lodash@4.17.21/lodash.min.js"></script>
Теперь добавьте в main.js следующие функции.
// The softmax transforms values to be between 0 and 1.
function softmax(resultArray) {
// Get the largest value in the array.
const largestNumber = Math.max(...resultArray);
// Apply the exponential function to each result item subtracted by the largest number, using reduction to get the
// previous result number and the current number to sum all the exponentials results.
const sumOfExp = resultArray
.map(resultItem => Math.exp(resultItem - largestNumber))
.reduce((prevNumber, currentNumber) => prevNumber + currentNumber);
// Normalize the resultArray by dividing by the sum of all exponentials.
// This normalization ensures that the sum of the components of the output vector is 1.
return resultArray.map((resultValue, index) => {
return Math.exp(resultValue - largestNumber) / sumOfExp
});
}
function imagenetClassesTopK(classProbabilities, k = 5) {
const probs = _.isTypedArray(classProbabilities)
? Array.prototype.slice.call(classProbabilities)
: classProbabilities;
const sorted = _.reverse(
_.sortBy(
probs.map((prob, index) => [prob, index]),
probIndex => probIndex[0]
)
);
const topK = _.take(sorted, k).map(probIndex => {
const iClass = imagenetClasses[probIndex[1]]
return {
id: iClass[0],
index: parseInt(probIndex[1].toString(), 10),
name: iClass[1].replace(/_/g, " "),
probability: probIndex[0]
}
});
return topK;
}
- Теперь вы добавили все скрипты, необходимые для запуска классификации образов с помощью WebNN в базовом веб-приложении. С помощью расширения Live Server для VS Code теперь можно запустить базовую веб-страницу в приложении, чтобы просмотреть результаты классификации самостоятельно.