Примечание.
Для доступа к этой странице требуется авторизация. Вы можете попробовать войти или изменить каталоги.
Для доступа к этой странице требуется авторизация. Вы можете попробовать изменить каталоги.
На предыдущем этапе этого руководства мы установили PyTorch на компьютере. Теперь с помощью этой библиотеки мы настроим в коде доступ к данным, которые будут использоваться для создания модели.
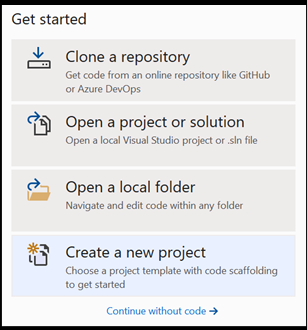
Откройте новый проект в Visual Studio.
- Откройте Visual Studio и выберите
create a new project.
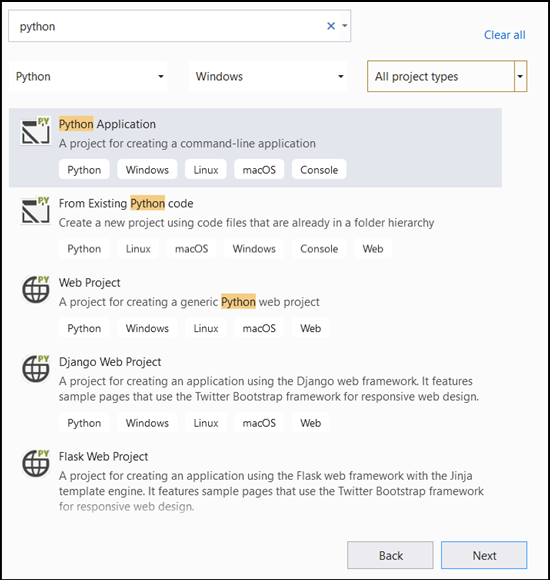
- На панели поиска введите
Pythonи выберитеPython Applicationкак шаблон проекта.
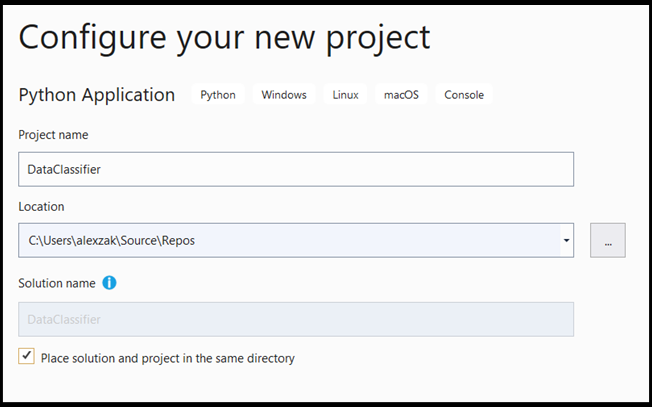
- В окне конфигурации:
- Присвойте проекту имя. Здесь мы называем это DataClassifier.
- Выберите расположение проекта.
- Если вы используете VS 2019, установите флажок
Create directory for solution. - Если вы используете VS2017, убедитесь, что флажок снят с
Place solution and project in the same directory.
Нажмите, create чтобы создать проект.
Создание интерпретатора Python
Теперь вам нужно определить новый интерпретатор Python. Он должен включать недавно установленный пакет PyTorch.
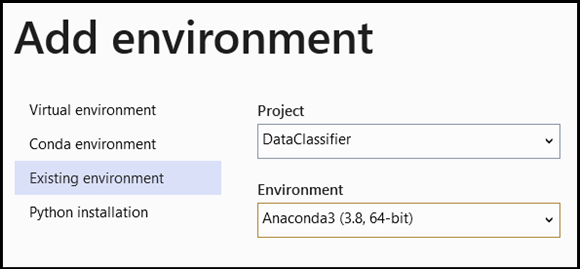
- Перейдите в раздел для выбора интерпретатора и выберите
Add Environment:

- В окне
Add EnvironmentвыберитеExisting environment, а затемAnaconda3 (3.6, 64-bit). Это действие включает пакет PyTorch.
Чтобы протестировать работу интерпретатора Python и пакета PyTorch, введите в файл DataClassifier.py следующий код:
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
В ответ вы должны получить тензор 5×3 со случайными значениями следующего вида.
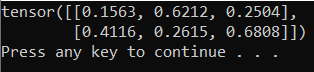
Замечание
Заинтересованы в обучении больше? Посетите официальный веб-сайт PyTorch.
Основные сведения о данных
Мы обучим модель на наборе данных цветка Ириса Фишера. Этот известный набор данных включает в себя 50 записей для каждого из трех видов Iris setosa, Iris virginica и Iris versicolor.
Были опубликованы несколько версий набора данных. Набор данных Iris можно найти в репозитории машинного обучения UCI, импортировать набор данных непосредственно из библиотеки Python Scikit-learn или использовать любую другую версию, опубликованную ранее. Чтобы узнать о наборе данных об ирисах, посетите страницу Википедии.
В этом руководстве показано, как обучить модель с табличным типом входных данных, вы будете использовать набор данных Iris, экспортируемый в файл Excel.
Каждая строка таблицы Excel показывает четыре признака ирисов: длина чашелистика в cm, ширина чашелистика в см, длина лепестка в см и лепестковая ширина в см. Эти функции будут использоваться в качестве входных данных. Последний столбец содержит тип Iris, связанный с этими параметрами, и будет представлять выходные данные регрессии. В общей сложности набор данных содержит 150 входных данных из четырех функций, каждый из которых соответствует соответствующему типу Iris.
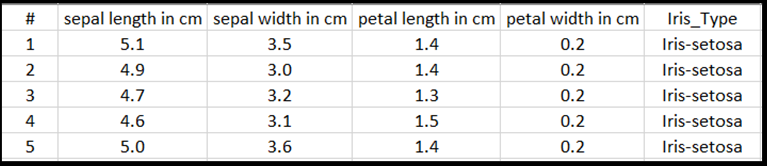
Анализ регрессии анализирует связь между входными переменными и результатом. Основываясь на входных данных, модель научится прогнозировать корректный тип результата — один из трех типов: Iris-setosa, Iris-versicolor, или Iris-virginica.
Это важно
Если вы решите использовать любой другой набор данных для создания собственной модели, необходимо указать входные переменные и выходные данные модели в соответствии с вашим сценарием.
Загрузите набор данных.
Скачайте набор данных Iris в формате Excel. Его можно найти здесь.
DataClassifier.pyВ файле в папке "Файлы обозревателя решений" добавьте следующую инструкцию импорта, чтобы получить доступ ко всем нужным пакетам.
import torch
import pandas as pd
import torch.nn as nn
from torch.utils.data import random_split, DataLoader, TensorDataset
import torch.nn.functional as F
import numpy as np
import torch.optim as optim
from torch.optim import Adam
Как видно, вы будете использовать пакет pandas (анализ данных Python) для загрузки и управления данными и пакета torch.nn, содержащего модули и расширяемые классы для создания нейронных сетей.
- Загрузите данные в память и проверьте количество классов. Мы ожидаем увидеть 50 штук каждого типа ирис. Обязательно укажите расположение набора данных на компьютере.
Добавьте в файл DataClassifier.py указанный ниже код.
# Loading the Data
df = pd.read_excel(r'C:…\Iris_dataset.xlsx')
print('Take a look at sample from the dataset:')
print(df.head())
# Let's verify if our data is balanced and what types of species we have
print('\nOur dataset is balanced and has the following values to predict:')
print(df['Iris_Type'].value_counts())
При выполнении этого кода ожидаемые выходные данные приведены следующим образом:
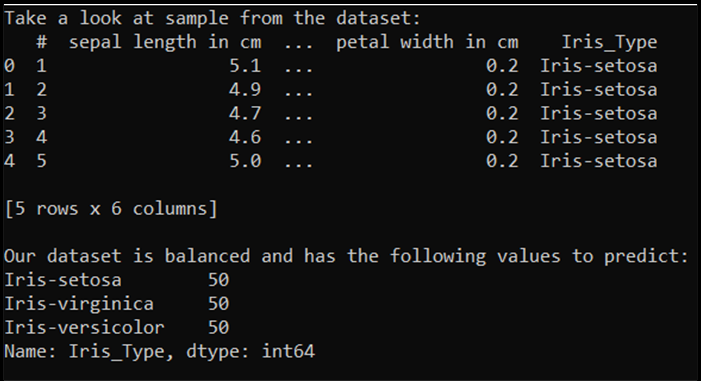
Чтобы использовать набор данных и обучить модель, необходимо определить входные и выходные данные. Входные данные включают 150 строк признаков, а выходные данные — столбец типа Iris. Нейронная сеть, которую мы будем использовать, требует числовых переменных, поэтому вы преобразуете выходную переменную в числовой формат.
- Создайте новый столбец в наборе данных, который будет представлять выходные данные в числовом формате и определять входные и выходные данные регрессии.
Добавьте в файл DataClassifier.py указанный ниже код.
# Convert Iris species into numeric types: Iris-setosa=0, Iris-versicolor=1, Iris-virginica=2.
labels = {'Iris-setosa':0, 'Iris-versicolor':1, 'Iris-virginica':2}
df['IrisType_num'] = df['Iris_Type'] # Create a new column "IrisType_num"
df.IrisType_num = [labels[item] for item in df.IrisType_num] # Convert the values to numeric ones
# Define input and output datasets
input = df.iloc[:, 1:-2] # We drop the first column and the two last ones.
print('\nInput values are:')
print(input.head())
output = df.loc[:, 'IrisType_num'] # Output Y is the last column
print('\nThe output value is:')
print(output.head())
При выполнении этого кода ожидаемые выходные данные приведены следующим образом:
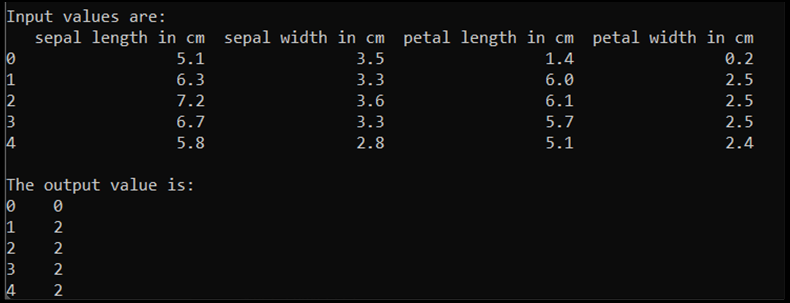
Чтобы обучить модель, необходимо преобразовать входные и выходные данные модели в формат Tensor:
- Преобразование в тензор:
Добавьте в файл DataClassifier.py указанный ниже код.
# Convert Input and Output data to Tensors and create a TensorDataset
input = torch.Tensor(input.to_numpy()) # Create tensor of type torch.float32
print('\nInput format: ', input.shape, input.dtype) # Input format: torch.Size([150, 4]) torch.float32
output = torch.tensor(output.to_numpy()) # Create tensor type torch.int64
print('Output format: ', output.shape, output.dtype) # Output format: torch.Size([150]) torch.int64
data = TensorDataset(input, output) # Create a torch.utils.data.TensorDataset object for further data manipulation
При выполнении кода ожидаемые выходные данные будут отображать формат входных и выходных данных следующим образом:

Есть 150 входных значений. Около 60% будут использованы в качестве данных для обучения модели. Вы будете хранить 20% для проверки и 30% для теста.
В этом руководстве размер серии для тренировочного набора данных определяется как 10. В наборе обучения имеется 95 элементов, то есть в среднем 9 полных пакетов для итерации через набор обучения один раз (одна эпоха). Размер пакета проверки и тестового набора будет храниться как 1.
- Разделение данных для обучения, проверки и тестирования наборов:
Добавьте в файл DataClassifier.py указанный ниже код.
# Split to Train, Validate and Test sets using random_split
train_batch_size = 10
number_rows = len(input) # The size of our dataset or the number of rows in excel table.
test_split = int(number_rows*0.3)
validate_split = int(number_rows*0.2)
train_split = number_rows - test_split - validate_split
train_set, validate_set, test_set = random_split(
data, [train_split, validate_split, test_split])
# Create Dataloader to read the data within batch sizes and put into memory.
train_loader = DataLoader(train_set, batch_size = train_batch_size, shuffle = True)
validate_loader = DataLoader(validate_set, batch_size = 1)
test_loader = DataLoader(test_set, batch_size = 1)
Дальнейшие шаги
С готовыми к работе данными пришло время обучить модель PyTorch