Cluster resource manager architecture overview
The Service Fabric Cluster Resource Manager is a central service that runs in the cluster. It manages the desired state of the services in the cluster, particularly with respect to resource consumption and any placement rules.
To manage the resources in your cluster, the Service Fabric Cluster Resource Manager must have several pieces of information:
- Which services currently exist
- Each service's current (or default) resource consumption
- The remaining cluster capacity
- The capacity of the nodes in the cluster
- The amount of resources consumed on each node
The resource consumption of a given service can change over time, and services usually care about more than one type of resource. Across different services, there may be both real physical and physical resources being measured. Services may track physical metrics like memory and disk consumption. More commonly, services may care about logical metrics - things like "WorkQueueDepth" or "TotalRequests". Both logical and physical metrics can be used in the same cluster. Metrics can be shared across many services or be specific to a particular service.
Other considerations
The owners and operators of the cluster can be different from the service and application authors, or at a minimum are the same people wearing different hats. When you develop your application you know a few things about what it requires. You have an estimate of the resources it will consume and how different services should be deployed. For example, the web tier needs to run on nodes exposed to the Internet, while the database services should not. As another example, the web services are probably constrained by CPU and network, while the data tier services care more about memory and disk consumption. However, the person handling a live-site incident for that service in production, or who is managing an upgrade to the service has a different job to do, and requires different tools.
Both the cluster and services are dynamic:
- The number of nodes in the cluster can grow and shrink
- Nodes of different sizes and types can come and go
- Services can be created, removed, and change their desired resource allocations and placement rules
- Upgrades or other management operations can roll through the cluster at the application on infrastructure levels
- Failures can happen at any time.
Cluster resource manager components and data flow
The Cluster Resource Manager has to track the requirements of each service and the consumption of resources by each service object within those services. The Cluster Resource Manager has two conceptual parts: agents that run on each node and a fault-tolerant service. The agents on each node track load reports from services, aggregate them, and periodically report them. The Cluster Resource Manager service aggregates all the information from the local agents and reacts based on its current configuration.
Let’s look at the following diagram:
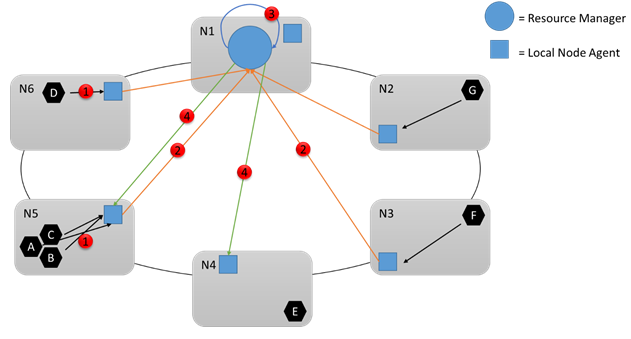
During runtime, there are many changes that could happen. For example, let’s say the amount of resources some services consume changes, some services fail, and some nodes join and leave the cluster. All the changes on a node are aggregated and periodically sent to the Cluster Resource Manager service (1,2) where they are aggregated again, analyzed, and stored. Every few seconds that service looks at the changes and determines if any actions are necessary (3). For example, it could notice that some empty nodes have been added to the cluster. As a result, it decides to move some services to those nodes. The Cluster Resource Manager could also notice that a particular node is overloaded, or that certain services have failed or been deleted, freeing up resources elsewhere.
Let’s look at the following diagram and see what happens next. Let’s say that the Cluster Resource Manager determines that changes are necessary. It coordinates with other system services (in particular the Failover Manager) to make the necessary changes. Then the necessary commands are sent to the appropriate nodes (4). For example, let's say the Resource Manager noticed that Node5 was overloaded, and so decided to move service B from Node5 to Node4. At the end of the reconfiguration (5), the cluster looks like this:

Next steps
- The Cluster Resource Manager has many options for describing the cluster. To find out more about them, check out this article on describing a Service Fabric cluster
- The Cluster Resource Manager's primary duties are rebalancing the cluster and enforcing placement rules. For more information on configuring these behaviors, see balancing your Service Fabric cluster