Na načítanie údajov do svojho jazera použite poznámkový blok
V tomto kurze sa naučíte, ako čítať/zapisovať údaje do svojho jazera fabric s notebookom. Fabric podporuje Spark API a Pandas API majú dosiahnuť tento cieľ.
Načítanie údajov pomocou rozhrania API služby Apache Spark
V bunke kódu poznámkového bloku použite nasledujúci príklad kódu na čítanie údajov zo zdroja a ich načítanie do súborov, tabuliek alebo oboch častí vášho jazera.
Ak chcete určiť umiestnenie, z ktorom sa má čítať, môžete použiť relatívnu cestu, ak údaje pochádzajú z predvoleného jazera aktuálneho poznámkového bloku. Ak údaje pochádzajú z iného jazera, môžete použiť absolútnu cestu k systému súborov Azure Blob (ABFS). Skopírujte túto cestu z kontextovej ponuky údajov.
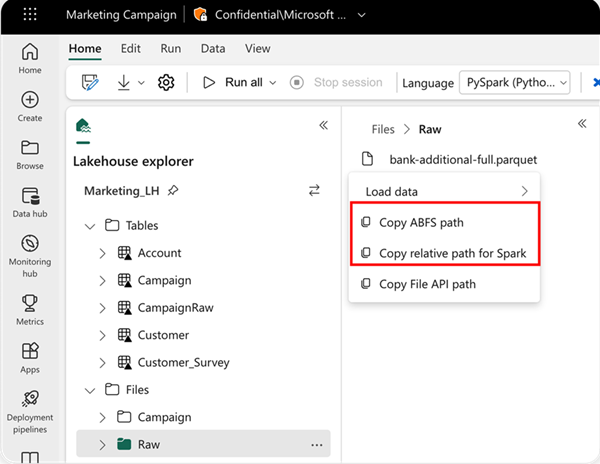
Kopírovať cestu ABFS: Táto možnosť vráti absolútnu cestu k súboru.
Skopírovanie relatívnej cesty k službe Spark: Táto možnosť vráti relatívnu cestu súboru v predvolenom prostredí lakehouse.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Načítanie údajov pomocou rozhrania API knižnice Pandas
Na podporu rozhrania Pandas API je predvolený lakehouse automaticky pripojený na notebook. Prípojka je '/lakehouse/default/'. Tento bod pripojenia môžete použiť na čítanie/zapisovanie údajov z/do predvoleného jazera. Možnosť Kopírovať cestu k súboru API z kontextovej ponuky vráti cestu k súboru rozhrania API z tohto bodu pripojenia. Cesta vrátená z možnosti Kopírovať ABFS cesta funguje aj pre rozhranie Pandas API.
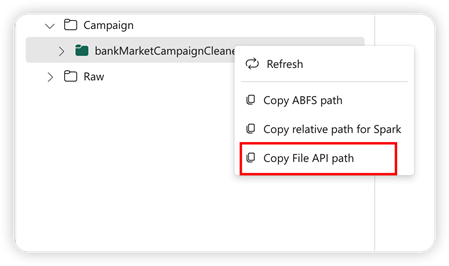
Kopírovať cestu k súboru API: Táto možnosť vráti cestu pod bodom pripojenia predvoleného jazera.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
Tip
V prípade rozhrania Spark API získajte cestu k súboru pomocou možnosti Kopírovať cestu ABFS alebo Skopírovanie relatívnej cesty k službe Spark . V prípade rozhrania Pandas API získajte cestu k súboru pomocou možnosti Kopírovať cestu k súboru ABFS alebo Cestu k kopírovaniu súboru API .
Najrýchlejší spôsob, ako mať kód na prácu s rozhraním API služby Spark alebo Pandas API, je použiť možnosť Načítať údaje a vybrať rozhranie API, ktoré chcete použiť. Kód sa automaticky vygeneruje v novej bunke kódu poznámkového bloku.

Súvisiaci obsah
Pripomienky
Pripravujeme: V priebehu roka 2024 postupne zrušíme službu Problémy v službe GitHub ako mechanizmus pripomienok týkajúcich sa obsahu a nahradíme ju novým systémom pripomienok. Ďalšie informácie nájdete na stránke: https://aka.ms/ContentUserFeedback.
Odoslať a zobraziť pripomienky pre