Poznámka
Na prístup k tejto stránke sa vyžaduje oprávnenie. Môžete sa skúsiť prihlásiť alebo zmeniť adresáre.
Na prístup k tejto stránke sa vyžaduje oprávnenie. Môžete skúsiť zmeniť adresáre.
Microsoft Fabric predstavuje všestranné analytické riešenie pre podniky, ktoré pokrývajú všetko od pohybu údajov až po dátovú vedu, analýzu v reálnom čase a business intelligence. Na jednom mieste ponúka komplexný balík služieb vrátane dátového jazera, dátového inžinierstva a integrácie údajov. Ďalšie informácie nájdete v téme Čo je Microsoft Fabric?
Tento kurz vás prevedie komplexným scenárom od získavania údajov až po spotrebu údajov. Pomáha vám vybudovať základné znalosti o službe Fabric vrátane rôznych prostredí a spôsobu ich integrácie, ako aj o skúsenostiach profesionálov a občanov, ktoré prichádzajú s prácou na tejto platforme. Tento kurz nie je určený pre referenčnú architektúru, úplný zoznam funkcií a funkcií ani odporúčanie konkrétnych osvedčených postupov.
Scenár od lakehouse od konca po koniec
Organizácie tradične budujú moderné sklady údajov pre svoje potreby transakčnej a štruktúrovanej analýzy údajov. A služby Data Lakehouses pre big data (polo/neštruktúrované) potreby analýzy údajov. Tieto dva systémy bežali paralelne, čím sa vytvorili silá, duplicita údajov a zvýšili sa celkové náklady na vlastníctvo.
Fabric s zjednotením úložiska údajov a štandardizácia vo formáte Delta Lake vám umožňuje odstrániť silá, odstrániť duplicitu údajov a drasticky znížiť celkové náklady na vlastníctvo.
Vďaka flexibilite, ktorú ponúka fabric, môžete implementovať architektúry lakehouse alebo data warehouse, alebo ich skombinovať, aby ste získali to najlepšie z oboch jednoduchých implementácií. V tomto kurze budete používať príklad maloobchodnej organizácie a od začiatku do konca zostaviť svoju zostavu lakehouse. Používa architektúru medailónu, kde bronzová vrstva obsahuje nespracované údaje, strieborná vrstva má overené a dedulicované údaje a zlatá vrstva obsahuje vysoko spresniné údaje. Môžete pristupovať rovnako k implementácii lakehouse pre všetky organizácie z akéhokoľvek odvetvia.
V tomto kurze sa vysvetľuje, ako vývojár vo fiktívnej spoločnosti Dovozcovia celého sveta z oblasti maloobchodu dokončí tieto kroky:
Prihláste sa do svojho konta Power BI a zaregistrujte si bezplatnú skúšobnú verziu služby Microsoft Fabric. Ak nemáte licenciu na Power BI, si zaregistrovať bezplatnú licenciu na Fabric a potom môžete spustiť skúšobnú verziu služby Fabric.
Vytvorte a implementujte komplexný lakehouse pre vašu organizáciu:
- Vytvorte pracovný priestor služby Fabric.
- Vytvorte si domček na jazere.
- Údaje Ingestujte, transformujte údaje a načítajte ich do jazera. Môžete tiež preskúmať OneLake, jednu kópiu vašich údajov v režime lakehouse a režim koncového bodu SQL Analytics.
- Pripojte sa k svojmu lakehouse pomocou SQL analytics endpointu a vytvorte sémantický model a zostavte report na analýzu predajných dát naprieč rôznymi dimenziami.
- Voliteľne môžete s kanálom koordinovať a naplánovať príjem údajov a postup transformácie. Pipeline zahŕňajú aktivity zamerané na Lakehouse, ako je údržba Lakehouse (na automatizáciu údržby tabuliek Delta pomocou OPTIMIZE a VACUUM) a aktivita Refresh SQL Endpoint (na synchronizáciu SQL analytického endpointu po načítaní dát). Pipeline expression builder tiež obsahuje pomoc Copilota pre rýchlejšie a presnejšie vytváranie výrazov. Pre podrobnosti pozri aktivitu údržby jazerného domu.
Vyčistíte zdroje tak, že odstránite pracovný priestor a ďalšie položky.
Architektúra
Na nasledujúcom obrázku je zobrazená architektúra lakehouse end-to-end. Súčasti, ktoré sú s tým spojené, sú popísané v nasledujúcom zozname.

Zdroje údajov: Vďaka službe Fabric sa môžete rýchlo a jednoducho pripojiť k službám Azure Data Services, ako aj k iným cloudovým platformám a lokálnym zdrojom údajov pri zjednodušenom príjmu údajov.
Príjem: Pomocou viac ako 200 natívnych konektorov môžete pre svoju organizáciu rýchlo vytvárať prehľady. Tieto konektory sú integrované do kanála fabricu a využívajú používateľsky prívetivú transformáciu údajov presúvaním pomocou toku údajov. Okrem toho sa môžete pomocou funkcie Skratka v službe Fabric pripojiť k existujúcim údajom bez toho, aby ste ich museli kopírovať alebo presúvať. Skratky OneLake tiež dokážu odkazovať na dátové produkty medzi nájomcami prostredníctvom externého zdieľania dát OneLake, čím získate prístup k živým, riadeným prevádzkovým dátam bez kopírovania alebo budovania ETL pipeline. Fabric tiež obsahuje vysokovýkonné vektorové čítačky súborov pre bežné formáty ako CSV (s podporou JSON), aby znížil oneskorenie pri vstupe.
Transformácia a ukladanie: Fabric sa štandardizuje vo formáte Delta Lake. Čo znamená, že všetky moduly služby Fabric môžu pristupovať k rovnakej množine údajov uloženej v službe OneLake a manipulovať s ňou bez duplikovania údajov. Jednotný model správy OneLake zabezpečuje, že dáta prístupné cez skratky sú súčasťou rovnakých bezpečnostných a compliance politík ako lokálne uložené dáta, čím poskytuje jednotnú verziu pravdy v celej organizácii. Tento úložný systém poskytuje flexibilitu pri vytváraní domov úložiska lakehouse pomocou architektúry medailí alebo siete údajov v závislosti od požiadavky vašej organizácie. Môžete si vybrať medzi prostredím s minimálnym použitím kódu alebo bez použitia kódu na transformáciu údajov, a to buď pomocou kanálov, tokov údajov alebo poznámkového bloku alebo Služby Spark, a to na prvý raz. Lakehouse tabuľky tiež podporujú optimalizácie výkonu, ako je Z-usporiadanie a Liquid Clustering, na zlepšenie výkonu dotazov a správu rozloženia dát vo veľkom rozsahu. Okrem toho sú k dispozícii Materialized Lake Views na predpočítanie a cacheovanie výsledkov cez dáta z jazerných domov, čo urýchľuje opakovanú analytiku. Prevádzkalizácia môže zahŕňať automatizovanú údržbu tabuliek Lakehouse Delta prostredníctvom aktivity Lakehouse Maintenance v potrubiach a spustenie obnovy SQL analytics endpointu ako súčasť krokov po načítaní – podrobnosti nájdete v voliteľnom kroku orchestrácie pipeline v prehľade scenára vyššie.
Consume: Power BI môže využívať údaje zo služby Lakehouse na vytváranie zostáv a vizualizáciu. Každý Lakehouse má zabudovaný TDS endpoint, SQL analytics endpoint, pre jednoduché pripojenie a dotazovanie dát v tabuľkách Lakehouse z iných reportovacích nástrojov. Orchestracia pipeline môže obsahovať krok na obnovenie endpointu Lakehouse SQL analytics, aby sa zabezpečilo, že schéma a metadáta sú aktuálne pre reportovacie nástroje po načítaní dát – podrobnosti nájdete v voliteľnom kroku orchestracie pipeline v prehľade scenára vyššie.
Prostredníctvom zdieľania dát medzi nájomcami môžu reporty, sémantické modely a AI/dátová veda využívať zdieľané OneLake dáta naprieč organizačnými hranicami, čo umožňuje spoluprácu bez duplicity dát.
Vzorová množina údajov
Tento tutoriál používa ukážkovú databázu Wide World Importers (WWI), ktorú importujete do jazerného domu v ďalšom tutoriáli. Pre komplexný scenár lakehouse dataset obsahuje dostatok údajov na preskúmanie škálovateľnosti a výkonnostných schopností platformy Fabric.
Wide World Dovozcovia (WWI) je veľkoobchod novosti tovaru dovozca a distribútor pôsobí z Oblasti San Francisco Bay. Ako veľkoobchodník patria zákazníci WWI väčšinou spoločnosti, ktoré predávajú jednotlivcom. WWI predáva maloobchodným zákazníkom po celých Spojených štátoch, vrátane špeciálnych obchodov, supermarketov, výpočtových obchodov, turistických atrakcií obchodov, a niektorí jedinci. WWI tiež predáva iným veľkoobchodníkom prostredníctvom siete agentov, ktorí podporujú výrobky v mene druhej svetovej vojny. Ďalšie informácie o svojom profile a prevádzke spoločnosti nájdete v téme Ukážkové databázy dovozcov zo celého sveta pre Microsoft SQL.
Vo všeobecnosti sa údaje prenášali z transakčných systémov alebo podnikových aplikácií do jazera. Pre jednoduchosť však v tomto tutoriáli používate dimenzionálny model poskytnutý prvou svetovou vojnou ako počiatočný zdroj dát. Dáta vložíte do jazerného domu a transformujete ich cez rôzne fázy (bronzová, strieborná a zlatá) medailónovej architektúry.
Dátový model
Kým dimenzionálny model z prvej svetovej vojny obsahuje množstvo faktických tabuliek, tento tutoriál používa tabuľku faktov Sale a jej korelované rozmery. Nasledujúci príklad ilustruje dátový model WWI:

Tok údajov a transformácie
Ako už bolo opísané, tento tutoriál využíva vzorkové údaje z údajov Wide World Importers (WWI) na stavbu komplexného jazerného domu. V tejto implementácii sú vzorové údaje uložené v konte úložiska údajov Azure vo formáte súboru Parquet pre všetky tabuľky. V reálnych scenároch by však údaje zvyčajne pochádzali z rôznych zdrojov a v rôznych formátoch.
Nasledujúci obrázok zobrazuje transformáciu zdroja, cieľa a dát:

Zdroj údajov: Zdrojové údaje sú vo formáte súboru Parquet a v nedielnej štruktúre. Sú uložené v priečinku pre každú tabuľku. V tomto tutoriáli nastavíte pipeline na spracovanie kompletných historických alebo jednorazových dát do jazerného domu.
V tomto tutoriáli používate tabuľku faktov o predaji , ktorá obsahuje jeden nadradený priečinok s historickými údajmi za 11 mesiacov (s jedným podpriečinkom pre každý mesiac) a ďalší priečinok obsahujúci inkrementálne údaje na tri mesiace (jeden podpriečinok pre každý mesiac). Počas počiatočného príjmu údajov sa do tabuľky lakehouse prelodí 11 mesiacov údajov. Keď prídu inkrementálne údaje, aktualizované októbrové a novembrové údaje sa zlúčia s existujúcimi údajmi a nové decembrové údaje sa zapíšu do tabuľky jazerných domov, ako je znázornené na nasledujúcom obrázku:
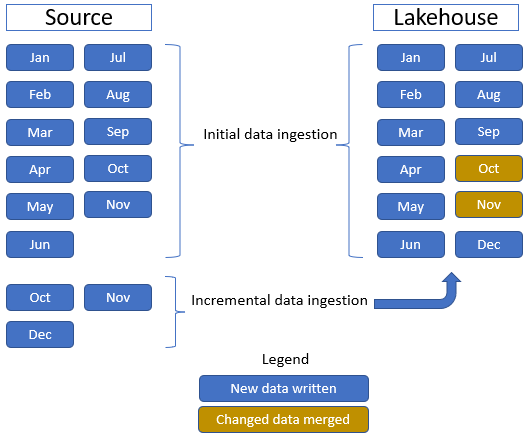
Lakehouse: V tomto kurze vytvoríte lakehouse, ingest dáta do súborov časti lakehouse, a potom vytvoriť delta lake tabuľky v sekcii tabuľky lakehouse.
Transform: Pre prípravu a transformáciu dát tento tutoriál pokrýva dva rôzne prístupy: notebooky a Spark pre zážitok zameraný na kód, a pipeline a dátové toky pre low-code alebo no-code zážitok. Najnovší runtime Fabric obsahuje natívny výkonný engine, ktorý prináša výrazné zlepšenie výkonu oproti open-source Sparku pre úlohy notebookov a Sparku. Pipeline expression builder obsahuje pomoc Copilota, ktorá pomáha vytvárať výrazy a budovať pipeline logiku pre rýchlejšie a presnejšie generovanie výrazov.
Spotrebujte: Power BI dokáže spotrebovať dáta z jazerného domu na reportovanie a vizualizáciu. Každý lakehouse má zabudovaný TDS endpoint nazývaný SQL analytics endpoint pre jednoduchú konektivitu a dotazovanie dát v lakehouse tabuľkách z iných reportovacích nástrojov. Môžete tiež použiť Direct Lake cez OneLake, aby Power BI priamo dotazoval na tabuľky lakehouse bez importu alebo samostatného cyklu obnovy sémantického modelu. Okrem toho môžete sprístupniť svoje dáta ne-Microsoft reportovacím nástrojom pomocou TDS/SQL analytics endpointu na pripojenie a spúšťanie SQL dotazov pre analytiku.
Pre Spark SQL záťaže konkrétne sa klienti kompatibilní s ODBC môžu pripojiť pomocou Microsoft ODBC Driver for Microsoft Fabric Data Engineering (Preview) s Microsoft Entra ID autentifikáciou (interaktívna, Azure CLI, service principal, certificate alebo access token).
