Poznámka
Na prístup k tejto stránke sa vyžaduje oprávnenie. Môžete sa skúsiť prihlásiť alebo zmeniť adresáre.
Na prístup k tejto stránke sa vyžaduje oprávnenie. Môžete skúsiť zmeniť adresáre.
Tento článok popisuje, ako použiť aktivitu kopírovania v kanáli na kopírovanie údajov z a do databázy SQL.
Podporovaná konfigurácia
Ak chcete nastaviť každú kartu v časti Aktivita kopírovania, prejdite do nasledujúcich sekcií.
- všeobecné
- zdrojové
- cieľ
- mapovania
- nastavenia
Všeobecné
Ak chcete nakonfigurovať kartu Všeobecné nastavenia
Zdroj
Pre databázu SQL na karte Source kopírovania sú podporované nasledujúce vlastnosti.

Nasledujúce vlastnosti sa vyžadujú:
pripojenia: Vyberte existujúcu databázu SQL odkazujúc na krok v tomto článku .
Použitiedotazu: Môžete vybrať tabuľku, dotazov alebo uloženú procedúru. Nasledujúci zoznam popisuje konfiguráciu každého nastavenia:
tabuľka: Zadajte názov databázy SQL, ktorá sa má čítať údaje. Vyberte existujúcu tabuľku v rozbaľovacom zozname alebo vyberte položky Zadajte manuálne a zadajte schému a názov tabuľky.
dotazu: Zadajte vlastný dotaz SQL na čítanie údajov. Príkladom je
select * from MyTable. Môžete tiež vybrať ikonu ceruzky a upraviť ju v editore kódu.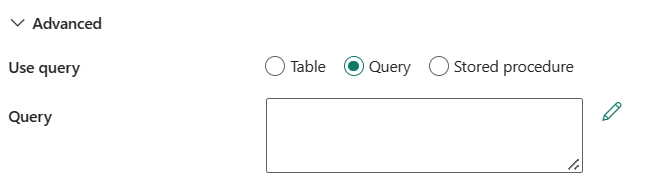
uložená procedúra: Z rozbaľovacieho zoznamu vyberte uloženú procedúru.

V časti Rozšírenémôžete zadať nasledujúce polia:
časový limit dotazu (minúty): Zadajte časový limit pre vykonanie príkazu dotazu, predvolená hodnota je 120 minút. Ak je parameter nastavený pre túto vlastnosť, povolené hodnoty sú časové rozpätie, napríklad 02:00:00 (120 minút).
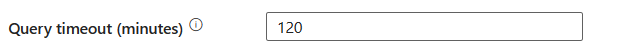
úroveň izolácie: Určuje správanie uzamknutia transakcií pre zdroj SQL. Povolené hodnoty sú: Čítanie spáchaných, ČítanieopakovateľnéhoSerializovateľnéalebo snímka. Ďalšie podrobnosti nájdete v
IsolationLevel Enum. 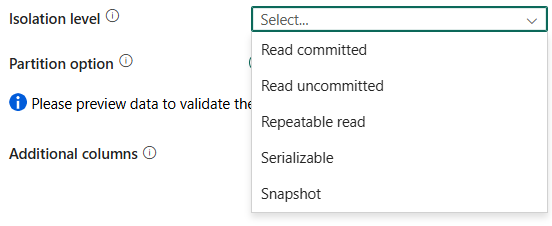
možnosti Oblasti: Zadajte možnosti rozdelenia údajov používané na načítanie údajov z databázy SQL. Povolené hodnoty sú: Žiadne (predvolené), Fyzické oblastitabuľky a Dynamický rozsah. Keď je povolená možnosť oblasti (to znamená, že nie je Žiadny), úroveň paralelného načítavania súbežného načítavania údajov z databázy SQL je riadená Stupne paralelného spracovania na karte s nastaveniami aktivity kopírovania.
Žiadny: Vyberte toto nastavenie, aby sa nepoužila oblasť.
Fyzické oblasti tabuľky: Pri použití fyzickej oblasti sa stĺpec a mechanizmus oblasti automaticky určia na základe vašej definície fyzickej tabuľky.
Dynamický rozsah: Pri použití dotazu so súbežne povoleným rozsahom je potrebný parameter oblasti rozsahu (
?DfDynamicRangePartitionCondition). Vzorový dotaz:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.Názov stĺpca Oblasť: Zadajte názov zdrojového stĺpca do celočíselného čísla alebo typu dátum/dátum a čas (
int,smallint,bigint,date,smalldatetime,datetime,datetime2alebodatetimeoffset), ktorý sa používa na rozdelenie rozsahu pre paralelnú kópiu. Ak nie je zadaný, index alebo primárny kľúč tabuľky sa automaticky rozpozná a použije ako stĺpec oblasti.Ak na načítanie zdrojových údajov použijete dotaz, môžete
?DfDynamicRangePartitionConditionklauzulu WHERE. Pozrite si napríklad časť Paralelná kópia z databázy SQL.rozdelenie hornej väzby oblasti: Zadajte maximálnu hodnotu stĺpca oblasti na rozdelenie rozsahu oblastí. Táto hodnota sa používa na rozhodnutie o kroku rozdelenia, nie na filtrovanie riadkov v tabuľke. Všetky riadky v tabuľke alebo výsledku dotazu sa rozdelia a skopírujú. Ak nie je zadaná, aktivita kopírovaním automaticky zistí hodnotu. Pozrite si napríklad časť Paralelná kópia z databázy SQL.
rozdelenie dolnej väzby oblasti: Zadajte minimálnu hodnotu stĺpca oblasti pre rozdelenie rozsahu oblastí. Táto hodnota sa používa na rozhodnutie o kroku rozdelenia, nie na filtrovanie riadkov v tabuľke. Všetky riadky v tabuľke alebo výsledku dotazu sa rozdelia a skopírujú. Ak nie je zadaná, aktivita kopírovaním automaticky zistí hodnotu. Pozrite si napríklad časť Paralelná kópia z databázy SQL.
Ďalšie stĺpce: Pridajte ďalšie stĺpce údajov na ukladanie relatívnej cesty alebo statickej hodnoty zdrojových súborov. Pre druhý sa podporuje výraz. Ďalšie informácie nájdete v Pridanie ďalších stĺpcov počas kopírovania.


Cieľ
Pre databázu SQL sa podporujú nasledujúce vlastnosti na karte kopírovania

Nasledujúce vlastnosti sa vyžadujú:
pripojenia: Vyberte existujúcu databázu SQL odkazujúc na krok v tomto článku .
možnosť Tabuľka: Vyberte možnosti Použiť existujúce alebo Automatické vytváranie tabuľky.
Ak vyberiete možnosť Použiť existujúce:
- tabuľka: Zadajte názov databázy SQL, ktorá sa má zapisovať údaje. Vyberte existujúcu tabuľku v rozbaľovacom zozname alebo vyberte položky Zadajte manuálne a zadajte schému a názov tabuľky.
Ak vyberiete možnosť Automatické vytvorenie tabuľky:
- tabuľka: Automaticky sa vytvorí tabuľka (ak neexistuje) v zdrojovej schéme, ktorá nie je podporovaná, keď sa uložená procedúra používa ako správanie pri zápise.
V časti Rozšírenémôžete zadať nasledujúce polia:
správanie pri písaní: Definuje správanie pri zápise, keď je zdrojom súbory z úložiska údajov na základe súborov. Môžete si vybrať Vložiť, Upsert alebo Uložená procedúra.

Vložiť: Túto možnosť vyberte, ak sa zdrojové údaje vkladali.
Upsert: Túto možnosť vyberte, ak zdrojové údaje obsahujú vkladáky aj aktualizácie.
Ako dočasnú tabuľku pre upsert zadajte, či sa má použiť globálna dočasná tabuľka alebo fyzická tabuľka, použiteTempDB. Služba predvolene používa ako dočasnú globálnu tabuľku dočasnú tabuľku a je toto políčko začiarknuté.
Ak zapíšete veľké množstvo údajov do databázy SQL, zrušte začiarknutie tejto možnosti a zadajte názov schémy, podľa ktorej Data Factory vytvorí vnášacu tabuľku na načítanie upstreamových údajov a automatické čistenie po dokončení. Uistite sa, že používateľ má povolenie na vytvorenie tabuľky v databáze a povolenie na zmenu schémy. Ak parameter nie je zadaný, ako pracovná os sa použije globálna dočasná tabuľka.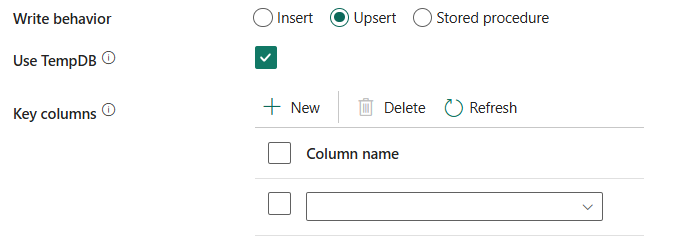
Vyberte schému databázy používateľa: Keď nie je vybratá použiť databázu TempDB, zadajte názov schémy, pod ktorou data factory vytvorí vnášacu tabuľku na načítanie upstreamových údajov a po dokončení ich automaticky vyčistí. Uistite sa, že máte povolenie na vytvorenie tabuľky v databáze a povolenia na zmenu schémy.
Nota
Musíte mať povolenie na vytváranie a odstraňovanie tabuliek. Predvolene bude dočasná tabuľka zdieľať rovnakú schému ako cieľová tabuľka.
kľúčové stĺpce: Vyberte, ktorý stĺpec sa používa na určenie, či riadok zo zdroja zodpovedá riadku z cieľa.
názov uloženej procedúry: Z rozbaľovacieho zoznamu vyberte uloženú procedúru.
zámokhromadnej vloženia tabuľky: Vyberte Áno alebo Nie. Toto nastavenie môžete použiť na zlepšenie výkonu kopírovania počas operácie hromadného vkladania do tabuľky bez indexu od viacerých klientov. Ďalšie informácie nájdete v
HROMADNÉ VLOŽENIE (Transact-SQL). pred kopírovaním skriptu: Zadajte skript pre aktivitu kopírovania, ktorá sa má spustiť pred napísaním údajov do cieľovej tabuľky pri každom spustení. Pomocou tejto vlastnosti môžete vyčistiť vopred načítané údaje.
časový limit dávky zápisu: Zadajte čas čakania na dokončenie operácie vkladania dávky pred uplynutím časového limitu. Povolená hodnota je časové rozpätie. Predvolená hodnota je 00:30:00 (30 minút).
veľkosť dávky zapisovania: Zadajte počet riadkov, ktoré sa majú vložiť do tabuľky SQL na dávku. Povolená hodnota je celé číslo (počet riadkov). Služba predvolene dynamicky určuje vhodnú veľkosť dávky na základe veľkosti riadka.
Maximálny počet súbežných pripojení: Zadajte hornú hranicu súbežných pripojení vytvorených s ukladacím priestorom údajov počas spustenia aktivity. Zadajte hodnotu iba vtedy, keď chcete obmedziť súbežné pripojenia.


Mapovanie
Ak pri konfigurácii karty Mapovanie nepoužite databázu SQL s cieľom automatického vytvárania tabuľky, prejdite na Mapovanie.
Ak použijete databázu SQL s cieľom automatického vytvárania tabuliek s výnimkou konfigurácie v Mapping, môžete upraviť typ pre cieľové stĺpce. Po výbere importovať schémymôžete zadať typ stĺpca vo svojom cieli.
Napríklad typ pre ID stĺpci v zdroji je int a môžete ho zmeniť na typ float pri mapovaní na cieľový stĺpec.

Nastavenia
Ak chcete Nastavenia konfigurácii karty, prejdite do Konfigurovať ďalšie nastavenia na karte Nastavenia.
Paralelná kópia z databázy SQL
Konektor databázy SQL v kopírovanej aktivite poskytuje vstavané rozdelenie údajov na kopírovanie údajov paralelne. Možnosti rozdelenia údajov nájdete na karte Source aktivity kopírovania.
Keď povolíte rozdeľovanie kópie, kopírovanie aktivity spustí paralelné dotazy voči zdroju databázy SQL a načíta údaje podľa oblastí. Paralelný stupeň je ovládaný Degree of copy parallelism na karte Nastavenia kopírovania aktivity. Ak ste napríklad nastavili Stupeň paralelného kopírovania na štyri, služba súbežne vygeneruje a spustí štyri dotazy na základe zadanej možnosti a nastavení oblasti a každý dotaz načíta časť údajov z databázy SQL.
Odporúčame povoliť paralelnú kópiu s oblasťou údajov najmä vtedy, keď načítate veľké množstvo údajov z databázy SQL. Nižšie sú uvedené navrhované konfigurácie pre rôzne scenáre. Pri kopírovaní údajov do úložiska údajov založených na súbore sa odporúča zapísať do priečinka ako viacero súborov (zadať iba názov priečinka). V takom prípade je výkon lepší ako zapisovanie do jedného súboru.
| Scenár | Navrhované nastavenia |
|---|---|
| Úplné načítanie z veľkej tabuľky pomocou fyzických oblastí. |
možnosť Oblasť: Fyzické oblasti tabuľky. Počas spustenia služba automaticky rozpozná fyzické oblasti a skopíruje údaje podľa oblastí. Ak chcete skontrolovať, či tabuľka obsahuje fyzickú oblasť alebo nie, môžete použiť tento dotaz. |
| Úplné načítanie z veľkej tabuľky bez fyzických oblastí, zatiaľ čo pri celočíselnom stĺpci alebo stĺpci typu datetime na rozdelenie údajov. |
možnosti oblasti: Oblasť dynamického rozsahu. stĺpca Oblasť (voliteľné): Zadajte stĺpec použitý na rozdelenie údajov. Ak parameter nie je zadaný, použije sa stĺpec indexu alebo primárneho kľúča. Oblasť horná hranica a oblasti dolná hranica (voliteľné): Určite, či chcete určiť krok rozdelenia. Na filtrovanie riadkov v tabuľke to však nie je možné. Všetky riadky v tabuľke sa rozdelia a skopírujú. Ak parameter nie je zadaný, aktivita kopírovania automaticky rozpozná hodnoty a môže to trvať dlho v závislosti od hodnôt MIN a MAX. Odporúča sa poskytnúť hornú väzbu a dolnú väzbu. Ak má napríklad stĺpec oblasti "ID" hodnoty v rozsahu od 1 do 100 a spodnú hranicu nastavíte ako 20 a hornú hranicu 80, s paralelnou kópiou ako 4 služba načíta údaje podľa 4 oblastí – ID v rozsahu <=20, [21, 50], [51, 80] a >=81. |
| Načítajte veľké množstvo údajov pomocou vlastného dotazu bez fyzických oblastí, zatiaľ čo so stĺpcom celé číslo alebo dátum/dátum a čas na rozdelenie údajov. |
možnosti oblasti: Oblasť dynamického rozsahu. dotazu: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.stĺpca Oblasť: Zadajte stĺpec použitý na rozdelenie údajov. Oblasť horná hranica a oblasti dolná hranica (voliteľné): Určite, či chcete určiť krok rozdelenia. Toto nie je pre filtrovanie riadkov v tabuľke, všetky riadky vo výsledku dotazu sa rozdelia a skopírujú. Ak nie je zadaná, aktivita kopírovaním automaticky zistí hodnotu. Ak má napríklad stĺpec oblasti "ID" hodnoty v rozsahu od 1 do 100 a spodnú hranicu nastavíte ako 20 a hornú hranicu ako 80, s paralelnou kópiou ako 4 služba načíta údaje podľa 4 oblastí- ID v rozsahu <=20, [21, 50], [51, 80] a >=81. Tu sú ďalšie vzorové dotazy pre rôzne scenáre: • Dotaz na celú tabuľku: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Dotaz z tabuľky s výberom stĺpca a ďalšími filtrami klauzuly where-clause: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Dotaz s poddotazmi: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Dotaz s oblasťou v poddotaze: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Najvhodnejšie postupy na načítanie údajov pomocou možnosti oblasti:
- Vyberte rozlišovací stĺpec ako stĺpec oblasti (napríklad primárny kľúč alebo jedinečný kľúč), aby sa predišlo skresleniu údajov.
- Ak tabuľka obsahuje vstavanú oblasť, na získanie lepšieho výkonu použite možnosť oblasti fyzické oblasti tabuľky.
Vzorový dotaz na kontrolu fyzickej oblasti
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Ak tabuľka obsahuje fyzickú oblasť, zobrazí sa časť HasPartition ako "áno" ako nasledujúca.

Súhrn tabuľky
Nasledujúce tabuľky obsahujú ďalšie informácie o aktivite kopírovania v databáze SQL.
Zdroj
| Meno | Popis | Hodnota | Požadovaný | Vlastnosť skriptu JSON |
|---|---|---|---|---|
| pripojenia | Pripojenie k zdrojového úložisku údajov. | <pripojenie> | Áno | pripojenie |
| Použitie dotazov | Spôsob čítania údajov. Použite tabuľkové na čítanie údajov zo zadanej tabuľky alebo použite dotazu na čítanie údajov pomocou dotazov SQL. | • tabuliek • dotazov, • uloženej procedúry |
Áno | / |
| názov schémy | Názov schémy. | < názov schémy > | Nie | schéma |
| názov tabuľky | Názov tabuľky. | < názov tabuľky > | Nie | tabuľka |
| na dotazov | ||||
| dotazov | Zadajte vlastný dotaz SQL na čítanie údajov. Napríklad: SELECT * FROM MyTable. |
< > dotazov SQL | Nie | sqlReaderQuery |
| na uloženú procedúru | ||||
| názov uloženej procedúry | Názov uloženej procedúry. | < názvu uloženej procedúry > | Nie | sqlReaderStoredProcedureName |
| časový limit dotazu (minúty) | Časový limit pre vykonanie príkazu dotazu je predvolene 120 minút. Ak je parameter nastavený pre túto vlastnosť, povolené hodnoty sú časové rozpätie, napríklad 02:00:00 (120 minút). | časové rozpätie | Nie | queryTimeout (časový limit dotazu) |
| úroveň izolácie | Určuje správanie uzamknutia transakcií pre zdroj SQL. | • Prečítajte si zaviazala • Čítať bez vynechania • Opakovateľný čitateľný • Serializovateľné •Snímka |
Nie | isolationLevel: • ReadCommitted • ReadUncommitted • Opakovateľné Čítané • Serializovateľné •Snímka |
| možnosti Oblasti | Možnosti rozdelenia údajov používané na načítanie údajov z databázy SQL. | •Žiadny • Fyzické oblasti tabuľky • Dynamický rozsah |
Nie | partition (oblasť)Možnosť: • Fyzické oddielyTabuľky • Dynamický rozsah |
| Pre Dynamický rozsah | ||||
| názov stĺpca Oblasti | Názov zdrojového stĺpca vo formáte celé číslo alebo typ dátum/dátum a čas (int, smallint, bigint, date, smalldatetime, datetime, datetime2alebo datetimeoffset), ktorý sa používa rozdelenie rozsahu pre paralelnú kópiu. Ak nie je zadaný, index alebo primárny kľúč tabuľky sa automaticky rozpozná a použije ako stĺpec oblasti. Ak na načítanie zdrojových údajov použijete dotaz, môžete ?DfDynamicRangePartitionCondition klauzulu WHERE. |
< názvov stĺpcov oblastí > | Nie | partitionColumnName |
| s hornou väzbou oblasti | Maximálna hodnota stĺpca oblasti na rozdelenie rozsahu oblastí. Táto hodnota sa používa na rozhodnutie o kroku rozdelenia, nie na filtrovanie riadkov v tabuľke. Všetky riadky v tabuľke alebo výsledku dotazu sa rozdelia a skopírujú. Ak nie je zadaná, aktivita kopírovaním automaticky zistí hodnotu. | < > oblasti | Nie | partitionUpperBound |
| dolnej väzby oblasti | Minimálna hodnota stĺpca oblasti na rozdelenie rozsahu oblastí. Táto hodnota sa používa na rozhodnutie o kroku rozdelenia, nie na filtrovanie riadkov v tabuľke. Všetky riadky v tabuľke alebo výsledku dotazu sa rozdelia a skopírujú. Ak nie je zadaná, aktivita kopírovaním automaticky zistí hodnotu. | < dolnej časti oblasti > | Nie | partitionLowerBound |
| ďalšie stĺpce | Pridajte ďalšie stĺpce údajov na ukladanie relatívnej cesty alebo statickej hodnoty zdrojových súborov. Pre druhý sa podporuje výraz. | •Meno •Hodnota |
Nie | additionalColumns: •meno •hodnota |
Cieľ
| Meno | Popis | Hodnota | Požadovaný | Vlastnosť skriptu JSON |
|---|---|---|---|---|
| pripojenia | Vaše pripojenie do cieľového úložiska údajov. | <pripojenie > | Áno | pripojenie |
| možností Tabuľka | Vaša cieľová tabuľka údajov. Vyberte si z Use existing or Auto create table. | • Použiť existujúce • Automaticky vytvoriť tabuľku |
Áno | schéma tabuľka |
| správania pri písaní | Definuje správanie pri zápise, keď je zdrojom súbory z úložiska údajov na základe súborov. | •Vložiť • Upsert • Uložená procedúra |
Nie | writeBehavior: •vložiť • upsert • sqlWriterStoredProcedureName |
| zámok hromadnej vloženia tabuľky | Toto nastavenie môžete použiť na zlepšenie výkonu kopírovania počas operácie hromadného vkladania do tabuľky bez indexu od viacerých klientov. | Áno alebo Nie (predvolené) | Nie | sqlWriterUseTableLock: true alebo false (predvolené) |
| pre Upsert | ||||
| použitie databázy TempDB | Určuje, či sa má použiť globálna dočasná tabuľka alebo fyzická tabuľka ako dočasná tabuľka pre upsert. | selected (predvolené) alebo nevybrané | Nie | useTempDB: true (predvolené) alebo false |
| kľúčových stĺpcov |
Vyberte stĺpec, ktorý sa používa na určenie toho, či sa riadok zo zdroja zhoduje s riadkom z cieľa. | < > kľúča | Nie | Kľúče |
| na uloženú procedúru | ||||
| názov uloženej procedúry | Táto vlastnosť je názov uloženej procedúry, ktorá prečíta údaje zo zdrojovej tabuľky. Posledným príkazom SQL musí byť príkaz SELECT v uloženej procedúre. | < názvom uloženej procedúry > | Nie | sqlWriterStoredProcedureName |
| skriptov pred kopírovaním | Skript na kopírovanie aktivity, ktorý sa má spustiť pred zápisom údajov do cieľovej tabuľky v každom spustení. Pomocou tejto vlastnosti môžete vyčistiť vopred načítané údaje. |
<
> skriptov pred kopírovaním (reťazec) |
Nie | preCopyScript |
| časový limit pri zápise | Čas čakania na dokončenie operácie vkladania dávky pred uplynutím limitu. Povolená hodnota je časové rozpätie. Predvolená hodnota je 00:30:00 (30 minút). | časové rozpätie | Nie | writeBatchTimeout |
| veľkosť dávky zápisu | Počet riadkov, ktoré sa majú vložiť do tabuľky SQL na každú dávku. Služba predvolene dynamicky určuje vhodnú veľkosť dávky na základe veľkosti riadka. |
<počet riadkov> (celé číslo) |
Nie | writeBatchSize |
| max. súbežných pripojení | Horná hranica súbežných pripojení vytvorených do ukladacieho priestoru údajov počas spustenia aktivity. Zadajte hodnotu iba vtedy, keď chcete obmedziť súbežné pripojenia. |
<horná hranica súbežných pripojení> (celé číslo) |
Nie | maxConcurrentConnections |